title: "YOLOv8快速上手+实践"
weight: 2
# bookFlatSection: false
# bookToc: true
# bookHidden: false
# bookCollapseSection: false
# bookComments: false
# bookSearchExclude: false
YOLOv8快速上手+实践 #
前言 #
本文旨在快速上手并不涉及细致的训练超参数调优和YOLO源码层面的解析。
YOLOv8是YOLO家族中流行的实时目标检测系统,以其快速、准确和高效的特性在计算机视觉领域中广泛应用(目前YOLO的发展很快,YOLOv10就在前不久也已经正式发布)。本文将详细介绍如何在NVIDIA GPU环境下部署YOLOv8,从环境配置、库安装,到模型训练和应用的全流程操作,并在其中结合实际的火焰特征识别的实践。
环境部署(N卡) #
需要提前准备好要使用的Python环境,此步骤不再赘述
安装和配置CUDA #
前往nvidia的开发者网站,选择下载CUDA toolkit
先检查一下本地环境显卡驱动支持的最高CUDA版本,查看的CUDA toolkit 版本不能高于显卡驱动支持的最高版本
-
方式一:打开N卡的控制面板,在系统信息的组件里

-
方式二:使用命令
nvidia-smi查看CUDA版本
其次建议要下载前先确认下准备使用的Pytorch版本,尽量CUDA toolkit的版本和Pytorch支持的保持一致,起码不能使用低版本
- 最新版的CUDA:https://developer.nvidia.com/cuda-downloads
- 历史版本:https://developer.nvidia.com/cuda-toolkit-archive
跟着安装程序走即可,最后检查一下安装是否成功:
nvcc --version
成功输出版本信息即为成功

【可选】下载&安装CUDNN库 #
cuDNN 是用于深度神经网络的 GPU 加速库
继续回到之前的N卡开发者网站上,需要注册登录后才能下载
- 最新版本:https://developer.nvidia.com/cudnn
- 历史版本:https://developer.nvidia.com/rdp/cudnn-archive
下载的版本也需要和CUDA的大版本一一对应
下载下来的CUDNN库包括bin、include和lib目录,将目录下对应的所有文件复制到之前CUDA toolkit
的安装目录下即可
安装PyTorch #
官网:https://pytorch.org/get-started/locally/
选择自己环境的配置项,复制pip或者conda的命令来安装即可

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
如果安装失败或者下载过慢,请配置相关的代理
安装完成后可以在python环境中验证一下
torch.cuda.is_available()— CUDA工具链是否可用torch.cuda.device_count()— GPU数量torch.cuda.get_device_name(0)— 获取第一个GPU的名字

安装YOLOv8 #
- 官方Github:https://github.com/ultralytics/ultralytics
- 官方文档:https://docs.ultralytics.com/
yolov8提供了cli的工具,一方面可以直接通过命令行来训练和预测,另一方面cli的源码更有利于我们进行源码分析
从pip源安装 #
pip install ultralytics
从源码安装 #
下载源码后进入目标Python环境,执行下面的安装命令
pip install .
也可以加上-e参数,启用编辑模式
pip install -e .

【可选】其他工具 #
pip install jupyterlab tensorboard
基础操作&实践运用 #
预测任务 #
YOLOv8的预训练模型下载:https://docs.ultralytics.com/models/yolov8/#supported-tasks-and-modes
以下测试仅使用最小的YOLOv8n模型,如果需要其他更精确的预测需求可以选择其他的版本
命令行 #
以下的使用例子使用官方提供的图片
yolo task=detect mode=predict model=./yolov8n.pt source="./ultralytics/assets/bus.jpg"
其中
source里面可以写图片或者视频文件的路径,也可以写screen开始实时检测当前屏幕的画面,又或者是source=0可以调用摄像头实时检测画面
展示预测结果

可以在runs\detect里面找到对应的预测任务,输出预测的图片结果

也可以代码执行
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
# 加载 YOLO 模型
yolo = YOLO("./yolov8n.pt", task="detect")
# 运行目标检测
results = yolo(source="./ultralytics/assets/zidane.jpg")
# 打印结果
print(results)
# 可视化结果
image = cv2.imread("./ultralytics/assets/zidane.jpg")
# 遍历结果并提取边界框和标签
for result in results:
boxes = result.boxes.xyxy.cpu().numpy().astype(int) # 获取边界框坐标并转换为整数
labels = result.boxes.cls.cpu().numpy().astype(int) # 获取类索引并转换为整数
scores = result.boxes.conf.cpu().numpy() # 获取置信度分数
for box, label, score in zip(boxes, labels, scores):
x1, y1, x2, y2 = box
# 绘制边界框和标签
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, f"{label} {score:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 使用 matplotlib 显示图像
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
其他更多的参数,详情见:https://docs.ultralytics.com/modes/predict/#inference-arguments

代码示例 #
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt", task="detect")
results = yolo(source="./ultralytics/assets/bus.jpg")
相关参数也可以在源码的ultralytics\cfg\default.yaml中找到

以及可以结合opencv实时检测视频中的每帧画面预测结果
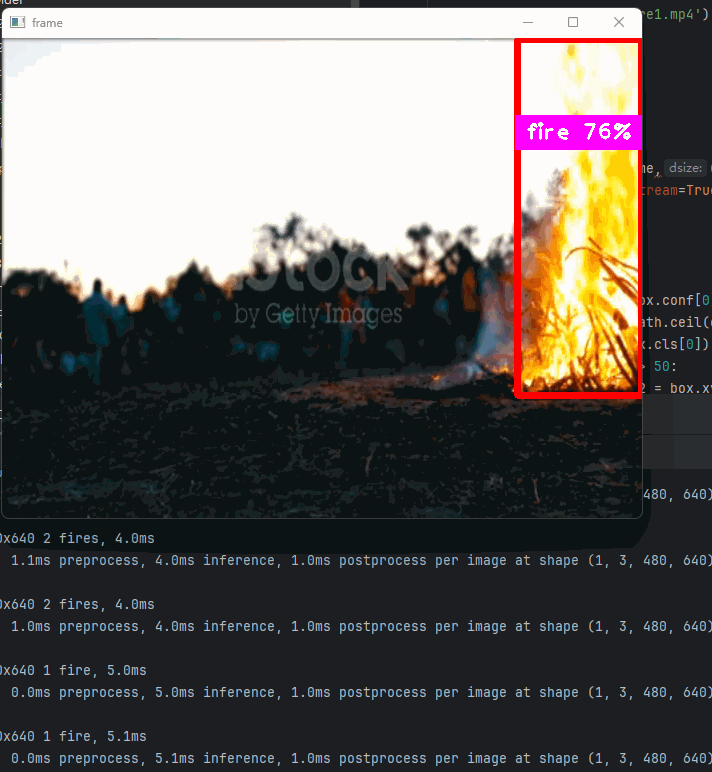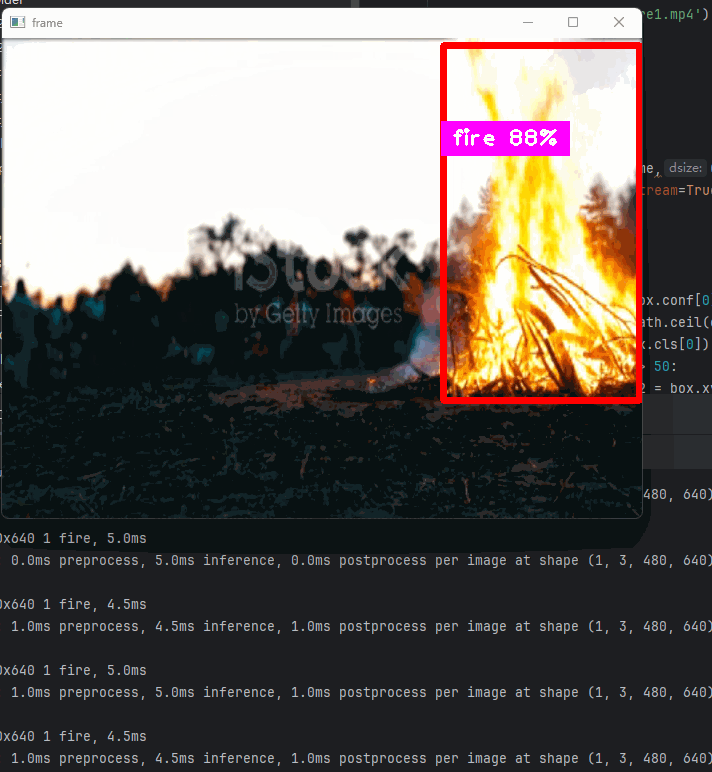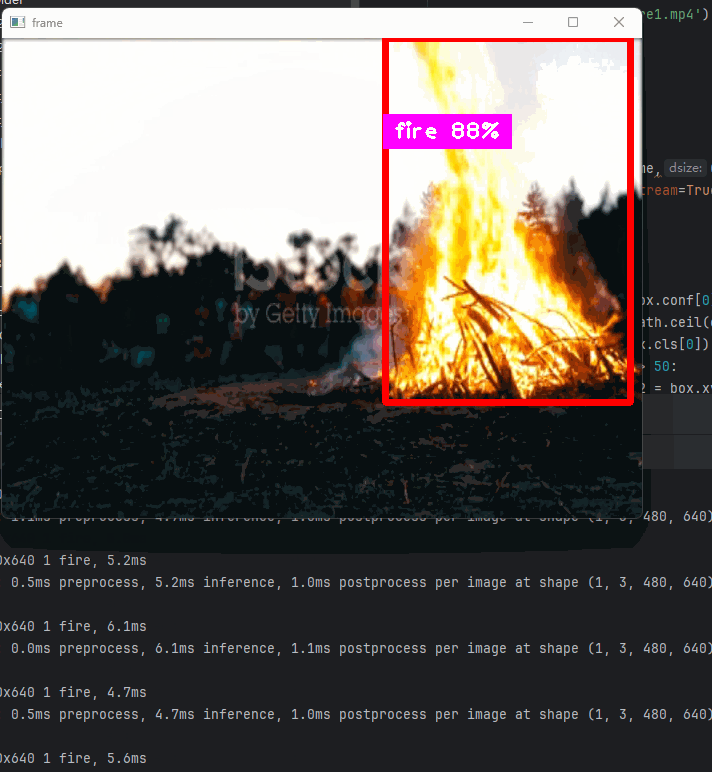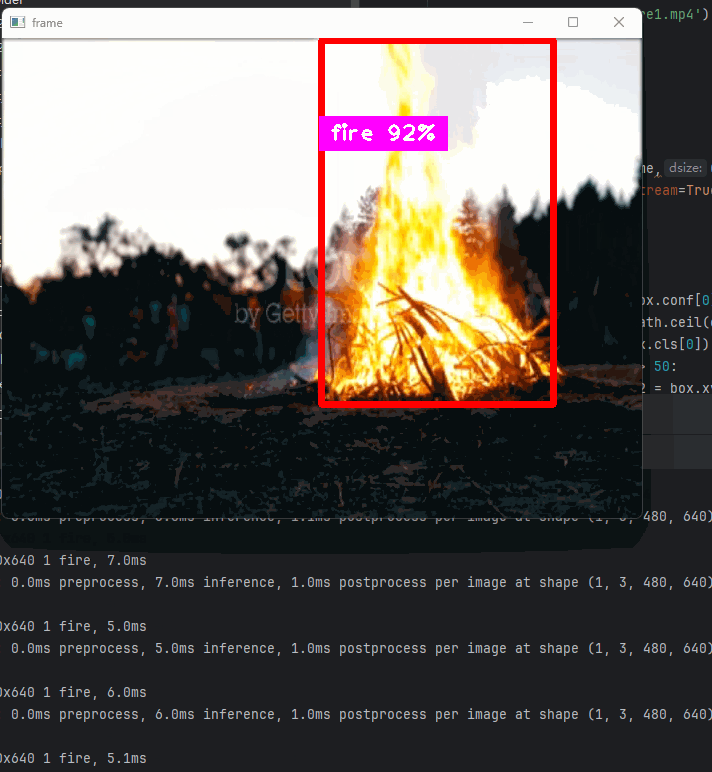
代码执行:
import cv2
from ultralytics import YOLO
import numpy as np
# 加载 YOLO 模型
model = YOLO("./yolov8n.pt", task="detect")
# 打开视频文件
video_path = "./test.mp4"
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"Error: Could not open video file {video_path}.")
exit()
# 获取视频的帧率和尺寸
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 定义视频编解码器并创建 VideoWriter 对象
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, fps, (width, height))
while True:
# 读取视频帧
ret, frame = cap.read()
if not ret:
print("End of video or failed to capture image")
break
# 运行目标检测
results = model(frame)
# 遍历结果并提取边界框、标签和置信度
for result in results:
boxes = result.boxes.xyxy.cpu().numpy().astype(int) # 获取边界框坐标并转换为整数
labels = result.boxes.cls.cpu().numpy().astype(int) # 获取类索引并转换为整数
scores = result.boxes.conf.cpu().numpy() # 获取置信度分数
for box, label, score in zip(boxes, labels, scores):
x1, y1, x2, y2 = box
# 绘制边界框和标签
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{label} {score:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 写入处理后的帧到输出视频
out.write(frame)
# 显示处理后的帧(如果在本地运行时)
# cv2.imshow('YOLOv8 Detection', frame)
# 按 'q' 键退出循环
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# 释放视频捕捉对象和 VideoWriter 对象
cap.release()
out.release()
# cv2.destroyAllWindows()
数据集准备&标注 #
可以自己准备数据集,也可以从找一些公开的训练数据集,标注过程是一个重复性的工作会比较枯燥。当然也可以直接去找对应YOLO版本已经标注好的数据,这会非常方便,也可以自定义添加自己场景下的数据集,总之数据集越丰富最后训练的模型识别的精度也会越高。
使用labelimg进行数据标注 #
安装和启动labelimg
注意:使用labelimg,python的版本不要高于3.9,高版本的python解释器运行时会出错
pip install labelimg
# 启动
labelimg
打开存放图片的目录,并设置保存的类型为YOLO

按下快捷键w,即可绘制区域,完成后填上对应的label标签名,然后继续切换到下一张图片重复进行

之后会在保存位置生成与图片名称一致的.txt文件,里面记录了label对应的序号以及绘制区域的信息

其他数据标注工具 #
- https://github.com/HumanSignal/label-studio/
- 官网:https://labelstud.io/
- Make Sense数据集标注【推荐】
- https://github.com/SkalskiP/make-sense
- 官网:https://www.makesense.ai/
模型训练 #
训练前准备 #
训练的目录需要在yaml文件中配置清楚,datasets的yaml描述文件可以在ultralytics\cfg\datasets中找到示例【yaml是数据集描述文件】

数据配置文件的基本格式:
path: raw-images # 数据集的根路径
train: ../train/images # 训练集
val: ../valid/images # 验证集
test: ../test/images # 测试集
names: # 检测目标的分类
0: 'fire'
训练模型 #
命令行的方式训练
yolo task=detect mode=train model=./yolov8n.pt data=data.yaml epochs=30 workers=1 batch=16
使用代码的方式训练
from ultralytics import YOLO
model = YOLO('./yolov8n.pt')
model.train(data='data.yaml', workers=1, epochs=30, batch=16)
训练过程会看到每轮训练的进度,结束后会有结果的保存位置,在训练结果中可以找到生成效果最好的模型best.pt和最后一次生成的last.pt,这个last.pt可以在以后继续训练

接着还有很多训练过程中的匹配示例图片,可以看到训练匹配的效果,以及展示训练过程中各项指标的变化情况。这有助于理解和分析模型的训练过程及其性能表现

使用训练的模型 #
yolo detect predict model=runs/detect/train5/weights/best.pt source=fire2.mp4 show=True


结语 #
在计算机视觉领域,YOLOv8以其出色的性能和简洁的设计备受青睐。掌握了这项技术后,你不仅能够处理各种实时目标检测任务,还可以根据具体需求对模型进行优化和定制。