YOLO-World:实时开放词汇的目标检测 #
本文档旨在介绍 YOLO-World,一个前沿的实时开放词汇目标检测模型。我们将探讨其核心概念、设计架构、关键用途,并将其与传统的 YOLO 模型进行对比,阐述其创新之处和优势。
1. 引言:什么是 YOLO-World? #
YOLO-World 是一个革命性的目标检测系统,它将强大的 YOLO 实时检测框架与开放词汇(Open-Vocabulary) 能力相结合。这意味着 YOLO-World 不再局限于预先训练时定义好的固定类别集,而是能够根据用户在推理时提供的 任意文本描述(词汇、短语) 来实时检测图像或视频中的相应目标。
其核心突破在于,它利用大规模视觉-语言预训练的知识,让模型能够理解文本提示(prompts)与图像中视觉内容之间的关联,从而实现对“世界万物”的检测潜力,而无需针对每一个新类别都进行重新训练。
2. 用途与价值主张 #
传统的目标检测器(如标准 YOLO)在训练完成后,只能识别训练数据中包含的特定类别(例如 PASCAL VOC 的 20 类或 COCO 的 80 类)。如果需要检测新的物体类别,就必须收集大量标注数据并重新训练模型,成本高昂且灵活性差。
YOLO-World 的出现旨在解决这一痛点,其主要用途和价值在于:
- 极高的灵活性与适应性: 用户可以随时定义新的、甚至是训练时从未见过的物体类别进行检测,只需提供相应的文本描述即可。例如,你可以让它检测“戴着红色帽子的狗”、“损坏的包裹”或“特定的工具名称”。
- 零样本(Zero-Shot)检测: 无需为新类别准备任何标注样本即可进行检测。
- 降低数据标注和重训练成本: 大幅减少了为扩展检测能力而进行的数据收集、标注和模型训练工作。
3. 架构设计:YOLO-World 如何工作? #
YOLO-World 的设计巧妙地融合了 YOLO 的高效检测架构和视觉-语言模型(VLMs)的语义理解能力。其核心组件通常包括:
- YOLO 检测器骨干(Backbone): 采用高效的 YOLO 系列骨干网络(如 YOLOv8 的 Darknet 变体)来提取图像的视觉特征。这些特征包含了丰富的空间和语义信息。
- 文本编码器(Text Encoder): 使用强大的预训练文本编码器(如 CLIP 的文本编码器或其他 Transformer 模型)将用户输入的文本提示(类别名称、描述等)转换为高维度的文本嵌入向量(text embeddings)。这些向量捕获了文本的语义含义。
- 视觉-语言融合网络(Vision-Language Fusion Network): 这是 YOLO-World 的关键创新。它不再是在模型输出端简单地比较视觉和文本特征,而是在检测网络的颈部(Neck)(例如 PANet 或其变种)中引入了文本嵌入信息。
- RepVL-PAN (Region-Prompt Vision-Language Path Aggregation Network): YOLO-World 论文中提出的一种代表性结构。它允许文本嵌入在不同层级与视觉特征进行深度融合和交互。这使得模型能够将全局的文本语义信息有效地传递到局部的像素级特征,从而指导检测头关注与文本描述匹配的图像区域。
- 检测头(Detection Head): 类似于标准 YOLO,检测头根据融合了文本信息的视觉特征来预测边界框(Bounding Boxes)和目标存在置信度(Objectness Score)。关键区别在于,类别的判断不再是输出固定类别的分数,而是通过计算检测到的物体视觉特征与输入文本提示的嵌入向量之间的相似度来确定该物体是否匹配某个文本描述。

预训练策略: YOLO-World 的强大能力来源于大规模的预训练。它在包含图像、对应边界框以及文本描述的大型数据集(如目标检测、视觉定位、图文对数据集)上进行训练,学习将视觉区域与自由形式的文本描述关联起来的能力。
工作流程(推理时):
- 用户提供一张图像和一组文本提示(例如
["人", "红色的自行车", "背包"])。 - 文本编码器将每个提示转换为文本嵌入向量。
- 图像通过 YOLO 骨干网络提取视觉特征。
- 视觉-语言融合网络(如 RepVL-PAN)将文本嵌入向量与多尺度视觉特征进行融合。
- 检测头根据融合后的特征预测边界框,并计算每个预测框的视觉特征与所有输入文本提示嵌入向量的相似度。
- 根据相似度得分和目标存在置信度,筛选并输出与输入文本提示匹配的目标及其边界框。
4. 与标准 YOLO 的对比 #
| 特性 | 标准 YOLO (例如 YOLOv8) | YOLO-World |
|---|---|---|
| 检测词汇 | 固定 (Closed-Vocabulary):只能检测预训练定义的类别。 | 开放 (Open-Vocabulary):可检测任意文本描述的类别。 |
| 训练要求 | 需要所有目标类别的检测标注数据进行训练/微调。 | 主要依赖大规模视觉-语言预训练,无需为新类别提供检测数据。 |
| 灵活性 | 低:增加新类别需要重新训练。 | 高:通过输入新文本提示即可检测新类别。 |
| 零样本能力 | 无。 | 核心能力:无需样本即可检测新类别。 |
| 性能 | 对其已知类别通常具有更高的 mAP 和更快的速度。 | 对比专门训练的模型,在已知类别上 mAP 可能稍低,但泛化能力强。 |
| 输入 | 图像。 | 图像 + 文本提示 (Prompts)。 |
| 输出 | 边界框 + 固定类别标签 + 置信度。 | 边界框 + 匹配的文本提示 + 置信度。 |
| 实时性 | 非常高。 | 保持实时性(是其设计目标之一)。 |

5. 初探 YOLO-World 的预测任务流程 #
ultralytics库已经原生支持yolo-world,与传统yolo不同的是通过预先设定classes分类,然后进行预测任务
model = YOLO(r"yolov8x-world.pt")
model.set_classes(["car", "person", "bus", "bicycle", "motorcycle"])
输入的类别会由CLIP模型进行文件向量嵌入作为语义向量
def set_classes(self, text, batch=80, cache_clip_model=True):
"""Set classes in advance so that model could do offline-inference without clip model."""
try:
import clip
except ImportError:
check_requirements("git+https://github.com/ultralytics/CLIP.git")
import clip
if (
not getattr(self, "clip_model", None) and cache_clip_model
): # for backwards compatibility of models lacking clip_model attribute
self.clip_model = clip.load("ViT-B/32")[0]
model = self.clip_model if cache_clip_model else clip.load("ViT-B/32")[0]
device = next(model.parameters()).device
text_token = clip.tokenize(text).to(device)
txt_feats = [model.encode_text(token).detach() for token in text_token.split(batch)]
txt_feats = txt_feats[0] if len(txt_feats) == 1 else torch.cat(txt_feats, dim=0)
txt_feats = txt_feats / txt_feats.norm(p=2, dim=-1, keepdim=True)
self.txt_feats = txt_feats.reshape(-1, len(text), txt_feats.shape[-1])
self.model[-1].nc = len(text)
保存在self.txt_feats对象中
然后就到关键环节!YOLO-World 的检测头 (Detection Head) 与传统 YOLO 不同。它不再是预测固定类别的索引号。对于图像中检测到的每个潜在目标(由其视觉特征表示),模型会计算该目标的视觉特征与我们预先计算好的所有类别文本嵌入 (self.txt_feats) 之间的相似度(通常是余弦相似度)。
def predict(self, x, profile=False, visualize=False, txt_feats=None, augment=False, embed=None):
# 获取、准备并复制扩展文本特征
txt_feats = (self.txt_feats if txt_feats is None else txt_feats).to(device=x.device, dtype=x.dtype)
if len(txt_feats) != len(x):
txt_feats = txt_feats.repeat(len(x), 1, 1)
# # 克隆原始文本特征,专用于检测头
ori_txt_feats = txt_feats.clone()
y, dt, embeddings = [], [], [] # outputs
for m in self.model: # except the head part
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if isinstance(m, C2fAttn):
x = m(x, txt_feats)
elif isinstance(m, WorldDetect):
# 将图像特征和文本特征传递给 WorldDetect 检测头
# 相似度计算在此模块的 forward 方法内部发生
x = m(x, ori_txt_feats)
elif isinstance(m, ImagePoolingAttn):
txt_feats = m(x, txt_feats)
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x
可以想象成,模型在问:“这个图像区域的‘样子’(视觉特征),和我理解的‘car’、‘person’、‘bus’等词语的‘意思’(文本嵌入),哪个最接近?”
模型最终输出边界框 (bounding boxes)、置信度分数 (confidence scores) 以及根据上述视觉-语义对齐确定的类别标签。
像标准 YOLO 一样,会应用非极大值抑制 (NMS) 等后处理步骤来去除冗余的检测框,得到最终的预测结果。
6. 运行环境&效果测试 #
运行环境参考 #
支持CPU、N卡推理
| 参数 | 描述 |
|---|---|
| 系统 | win11 |
| CPU | i7-14700K |
| GPU | 4090 16G |
| 解释器版本 | python11 |
| YOLOv8核心库版本 | ultralytics==8.2.93 |
| 模型 | yolov8x-world.pt(有n/s/m/s/x模型选择,参数量大小从左到右排序) |
| 推理速度 | CPU:300ms/帧;GPU:8ms/帧 |
效果测试 #
下图是YOLO-World官方给出的识别效果
可以看出除了基础类别的识别外,还可以实现自定义人物穿着特点的类别检测任务:the person wearing red clothes

下面结合一个场景做实际的测试
在道路监控场景的目标检测应用中,系统通常需要针对特定颜色属性(如黑色或红色车辆)进行目标筛选。传统目标检测模型对颜色等细粒度属性特征的辨识能力较弱,当业务需求涉及颜色过滤时,往往需要专门采集标注对应颜色的车辆数据集并重新训练检测模型,这将产生高昂的时间与资源成本。而基于先进视觉语言模型的YOLO-World架构,凭借其强大的零样本学习能力和对颜色特征的深度感知优势,能够直接通过"黑色轿车"、“红色卡车"等复合语义指令实现精准目标检索,无需额外训练即可完成特定颜色车辆的实时检测。这种即用型特性使YOLO-World在智慧交通、车辆追踪等需要颜色特征识别的场景中展现出显著的技术优势。
一般的类别检测任务
["car", "person", "bus", "bicycle", "motorcycle"]

自定义检测白色的车辆
["white car", "person", "bus", "bicycle", "motorcycle"]
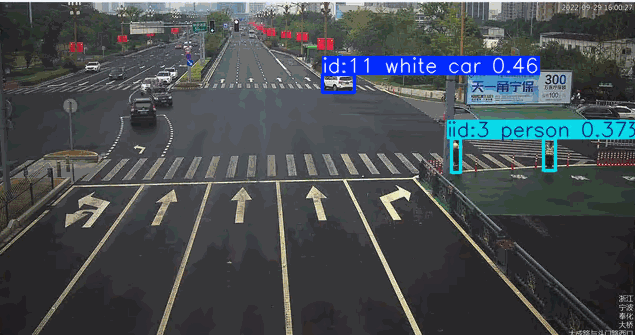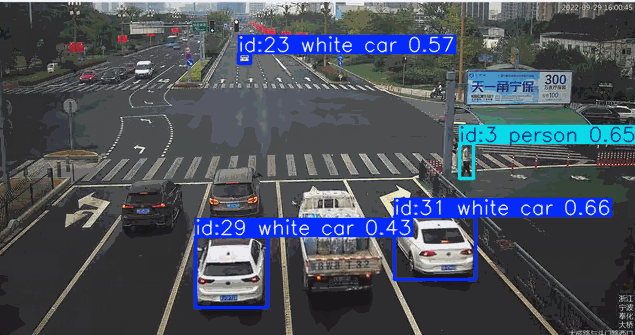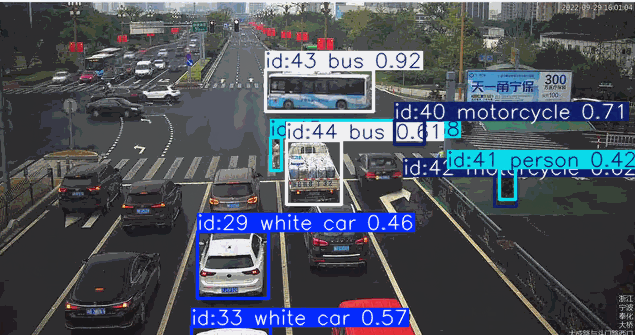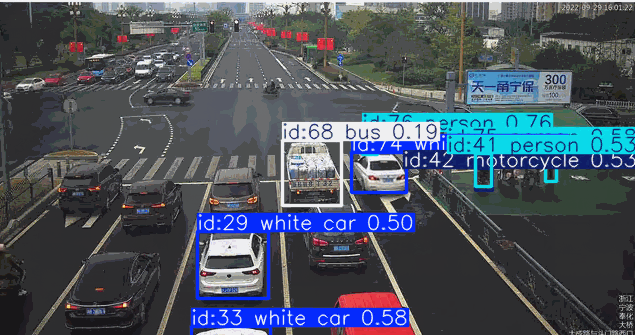
检测红色车辆
["red car", "person", "bus", "bicycle", "motorcycle"]
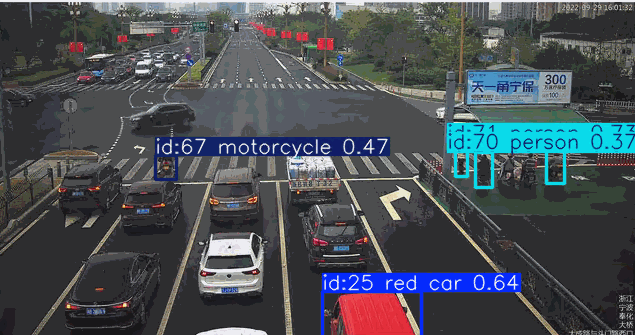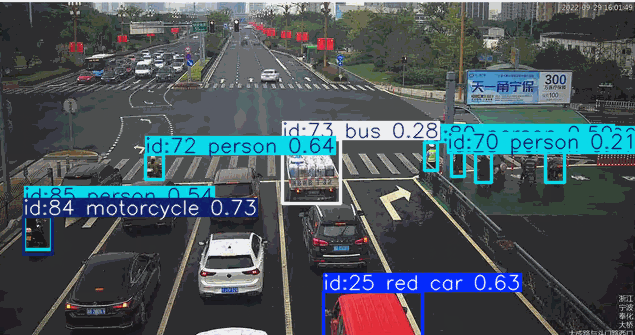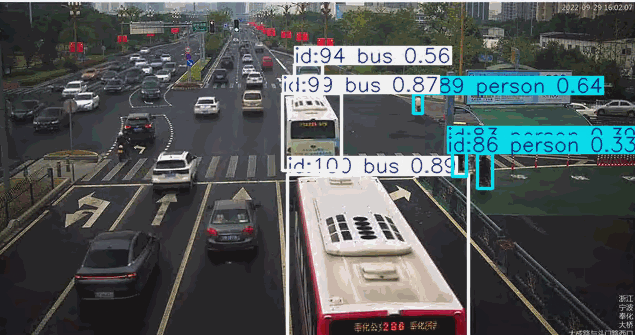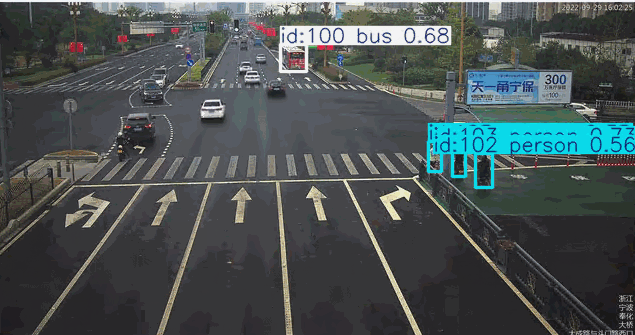
7. 目前的优势与不足 #
优势点
- 开放词汇检测,打破固定类别限制,泛化能力强。
- 零样本学习, 无需额外标注和训练即可检测新物体。
- 继承 YOLO 框架的高效性,可用于实时应用。
- 灵活性&适应性强,可根据需求动态改变检测目标。
- 显著减少数据标注和模型迭代的成本。
不足点
- 小参数量的模型效果不理想,项目实际落地需要选择参数量大的模型才能一定程度保证效果
- 检测任务中目标的普遍置信度相比传统yolo模型的置信度低