图像增强技术介绍 #
什么是图像增强? #
图像增强 (Image Enhancement) 是指通过一系列图像处理技术,有选择性地突出图像中感兴趣的特征、抑制不必要的特征,或改善图像的视觉效果,使其更适合于人类观察或计算机分析。其目的不是试图恢复图像的原始信息(这更偏向于图像复原),而是改善图像的质量,使其在特定应用场景下更有用。
常用的图像增强原理/类别:
- 空间域增强 (Spatial Domain Enhancement): 直接对图像的像素值进行操作。
- 点操作 (Point Operations): 对单个像素进行处理,不考虑其邻域像素。常见的有:
- 灰度变换: 如对比度拉伸、亮度调整、伽马校正、直方图均衡化等。通过修改像素的灰度级来改善图像的对比度和动态范围。
- 伪彩色处理: 将灰度图像的不同灰度级映射为不同的颜色,以突出细节。
- 邻域操作 (Neighborhood Operations): 基于像素及其邻域像素的值进行处理。常见的有:
- 图像平滑 (Smoothing): 使用均值滤波、中值滤波、高斯滤波等去除噪声,模糊图像。
- 图像锐化 (Sharpening): 使用拉普拉斯算子、梯度算子(Sobel, Prewitt)等增强图像的边缘和细节,使图像更清晰。
- 点操作 (Point Operations): 对单个像素进行处理,不考虑其邻域像素。常见的有:
- 频率域增强 (Frequency Domain Enhancement): 将图像变换到频率域(如傅里叶变换),对频率分量进行修改,然后再反变换回空间域。
- 低通滤波 (Low-pass Filtering): 衰减高频分量,保留低频分量,效果类似于空间域的平滑,可以去除噪声。
- 高通滤波 (High-pass Filtering): 衰减低频分量,保留高频分量,效果类似于空间域的锐化,可以增强边缘。
- 带通/带阻滤波: 保留或去除特定频率范围的分量。
- 同态滤波 (Homomorphic Filtering): 一种在频率域中同时压缩亮度范围和增强对比度的技术,常用于改善光照不均的图像。
- 基于深度学习的增强 (Deep Learning-based Enhancement): 利用深度神经网络(尤其是卷积神经网络 CNN、生成对抗网络 GAN、Transformer 等)学习从低质量图像到高质量图像的复杂映射关系。这是当前研究的热点和主流方向,在超分辨率、去噪、去模糊、去雨去雾、低光照增强等方面取得了突破性进展。
SwinIR 架构、超分原理及技术 #
-
SwinIR 架构设计: SwinIR 将 Swin Transformer 成功应用于图像复原任务。其核心架构主要包括三个部分:
- 浅层特征提取 (Shallow Feature Extraction): 使用一个简单的卷积层(如 3x3 卷积)从输入的低质量图像 (LQ) 中提取基本的底层特征,如边缘、颜色、纹理的初步信息。
- 深层特征提取 (Deep Feature Extraction): 这是 SwinIR 的核心,由多个 残差 Swin Transformer 块 (Residual Swin Transformer Blocks, RSTB) 堆叠而成。每个 RSTB 内部包含若干个 Swin Transformer 层,并通过残差连接进行连接。
- Swin Transformer 层: 其关键在于 基于窗口的自注意力 (Window-based Self-Attention) 和 窗口移位机制 (Shifted Window mechanism)。它首先将特征图划分为不重叠的局部窗口,在窗口内计算自注意力,这大大降低了计算复杂度。然后,通过周期性地移动窗口划分的边界(Shifted Window),使得相邻窗口之间能够进行信息交互,从而模拟了全局的自注意力效果,有效捕捉长距离依赖。
- 高质量图像重建 (High-Quality Image Reconstruction): 将深度特征通过上采样模块(对于超分辨率任务)和/或卷积层进行融合和重建,最终输出高质量的图像 (HQ)。对于超分辨率,通常会包含一个像素重组(Pixel Shuffle)或其他上采样层来扩大特征图尺寸。

-
图像处理流程:
- 输入: 低分辨率图像 (LR Image)。
- 浅层特征提取: 通过一个卷积层提取初步特征。
- 深层特征提取: 将浅层特征送入堆叠的 RSTB 模块中,通过 Swin Transformer 层进行深层次的特征学习和转换。
- 重建/上采样: 将深度特征输入到重建模块。对于 x4 超分,通常包含一个上采样层(如 Pixel Shuffle)将特征图尺寸放大 4 倍,并结合卷积层进行最终的像素值预测。
- 输出: 生成的高分辨率图像 (SR Image)。
- 训练阶段: 上述流程是生成器部分。训练时,还会将生成的 SR 图像和真实的 HR 图像送入判别器,计算对抗损失,并结合像素损失(如 L1 loss)、感知损失(可选)等,共同更新生成器和判别器的参数。
NAFNet 去噪/去模糊原理及技术 #
-
NAFNet 原理 (去噪/去模糊): NAFNet 的核心思想是构建一个 简单而强大的基线网络 (Baseline) 用于图像复原。它旨在学习一个从带有噪声或模糊的退化图像到清晰图像的映射。其原理可以看作是估计原始图像,通过网络去除或减弱噪声/模糊成分。它采用了一种类似于 U-Net 的对称编码器-解码器结构。
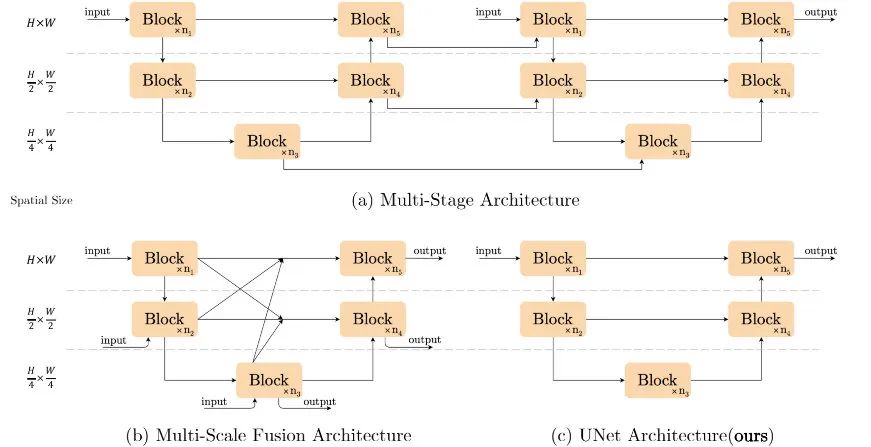
-
图像处理流程: NAFNet 通常采用类似 U-Net 的编码器-解码器结构:
- 输入: 带有噪声或模糊的退化图像。
- 编码器 (Encoder): 图像通过一系列 NAFBlock(包含卷积、Simple Gate、可能的通道注意力、LN 等)和下采样操作(如步进卷积或池化),逐步提取更深层、更抽象的特征,同时减小特征图的空间分辨率。
- 瓶颈层 (Bottleneck): 在最深的层次进行特征处理。
- 解码器 (Decoder): 通过一系列 NAFBlock 和上采样操作(如转置卷积或 Pixel Shuffle),逐步恢复图像细节和空间分辨率。通常会加入 跳跃连接 (Skip Connections),将编码器对应层级的特征图与解码器的特征图融合,帮助网络保留低级细节信息,这对去噪和去模糊任务至关重要。
- 重建: 最后通过一个或多个卷积层将解码器输出的特征映射回所需的干净图像。
- 输出: 去除噪声或模糊后的清晰图像。
环境参考及效果展示 #
硬件环境参考 #
支持CPU、N卡推理
| 参数 | 描述 |
|---|---|
| 系统 | win11 |
| CPU | i5-12400K |
| GPU | 3060 12G |
| 解释器版本 | python11 |
| 核心库版本 | torch ===2.4.1+cu121 |
| 推理速度(图像分辨率1280x720) | SwinIR模型22秒,NAFNet的两个模型1-2秒 |
SwinIR真实世界超分 #
- 原图

- 效果

- 原图

-
效果

NAFNet去噪 #
- 原图

- 效果

NAFNet去拖影 #
- 原图

- 效果

- 原图

- 效果

将来的展望 #
视频取证图像增强业务后续研究方向包括:
-
人脸超分与增强: 进一步提高人脸的保真度、身份一致性和真实感,特别是在极低分辨率或严重退化的情况下。
-
文字超分与增强 : 专门针对图像中的文字进行增强和超分辨率,提高文字的清晰度和可读性。
-
黑白图片上色 (Colorization): 利用 AI 模型为黑白老照片或视频自动上色,使其更加生动。
参考 #
https://www.modelscope.cn/models/iic/cv_nafnet_image-denoise_sidd/summary