虽然 sync.Pool 使用起来很简单,但如果使用不当,还是有可能出现问题的,例如,
- 对象重置不彻底:若未正确重置对象状态(例如忘记清空某个字段),可能导致脏数据污染,引发逻辑错误。
- 长时间占用对象:若某个 Goroutine 持有对象时间过长(例如执行阻塞操作),可能导致其他 Goroutine 频繁创建新对象,削弱池的优势。
- 高并发下池对象不足问题:若并发量远高于池中对象数量,New 函数会被频繁调用,可能抵消复用对象的收益。
- 返回池对象引用:应该限制池对象仅在局部作用域内使用,不应暴露给外部,否则会导致 data race 问题。
由于前两个问题相对简单直接,本文仅讨论后两个问题。
关于“高并发下池对象不足问题” #
下面通过真实场景案例,分析一下 “并发量远高于池中对象数量,导致 New 函数频繁调用,抵消对象复用收益” 的问题。
案例 1:高并发 HTTP 服务器的 JSON 序列化缓冲区 #
场景描述 #
某电商平台的商品详情接口需要处理 每秒 10 万次(QPS) 的请求。每个请求需要将商品数据序列化为 JSON 返回给客户端。为优化性能,开发团队使用 sync.Pool 缓存 *bytes.Buffer 对象,避免重复分配内存。
代码实现
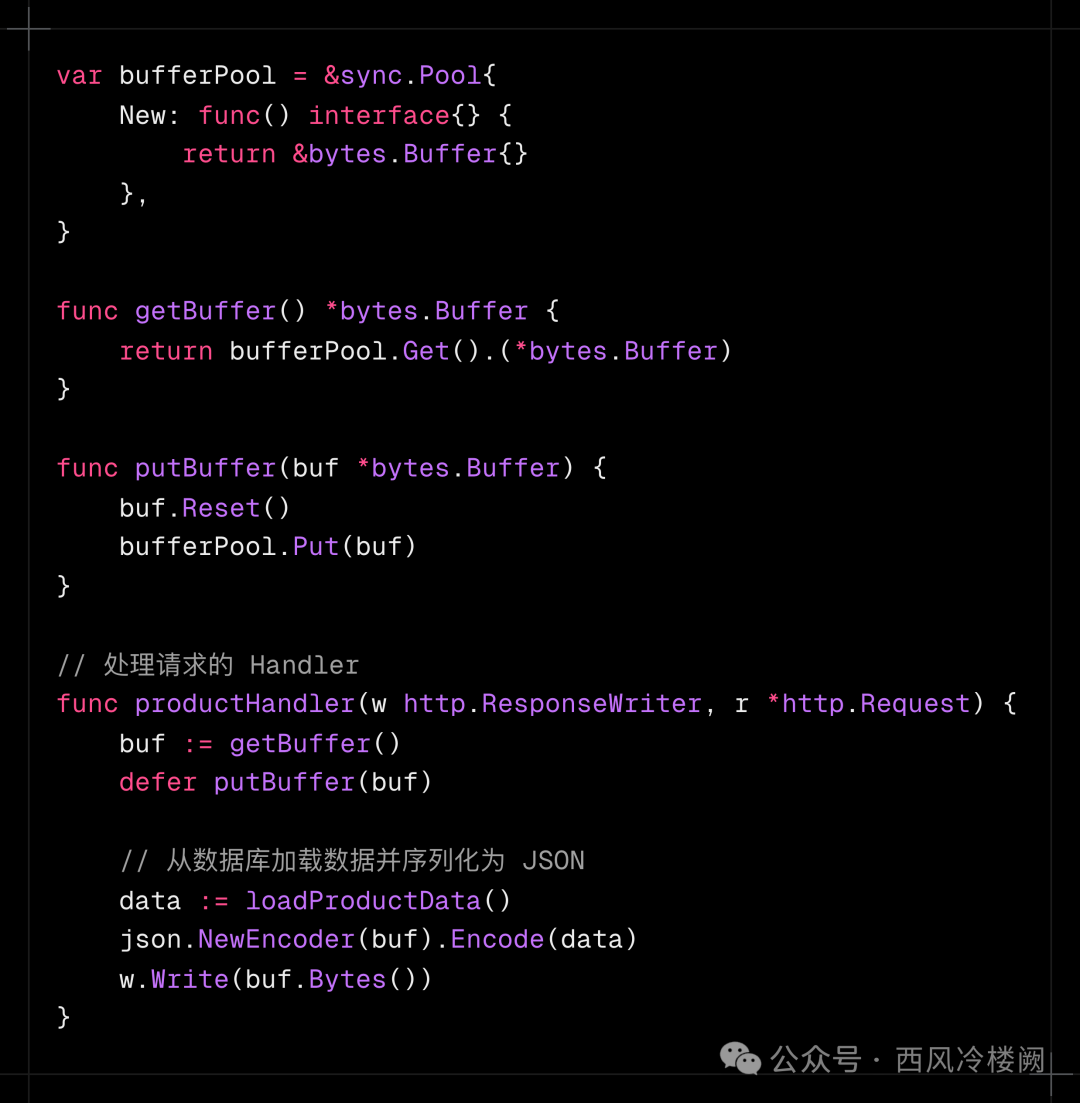
效果
- New 调用频率下降 70%,GC 频率恢复至正常水平。
- 请求延迟从 15ms 降低到 5ms。
*案例 2:实时日志处理系统的临时对象池* #
场景描述
某日志分析服务需实时解析海量日志条目(每秒 50 万条),每条日志需解析为结构体并暂存到内存队列。开发团队使用 sync.Pool 缓存日志解析的临时结构体对象。
代码实现
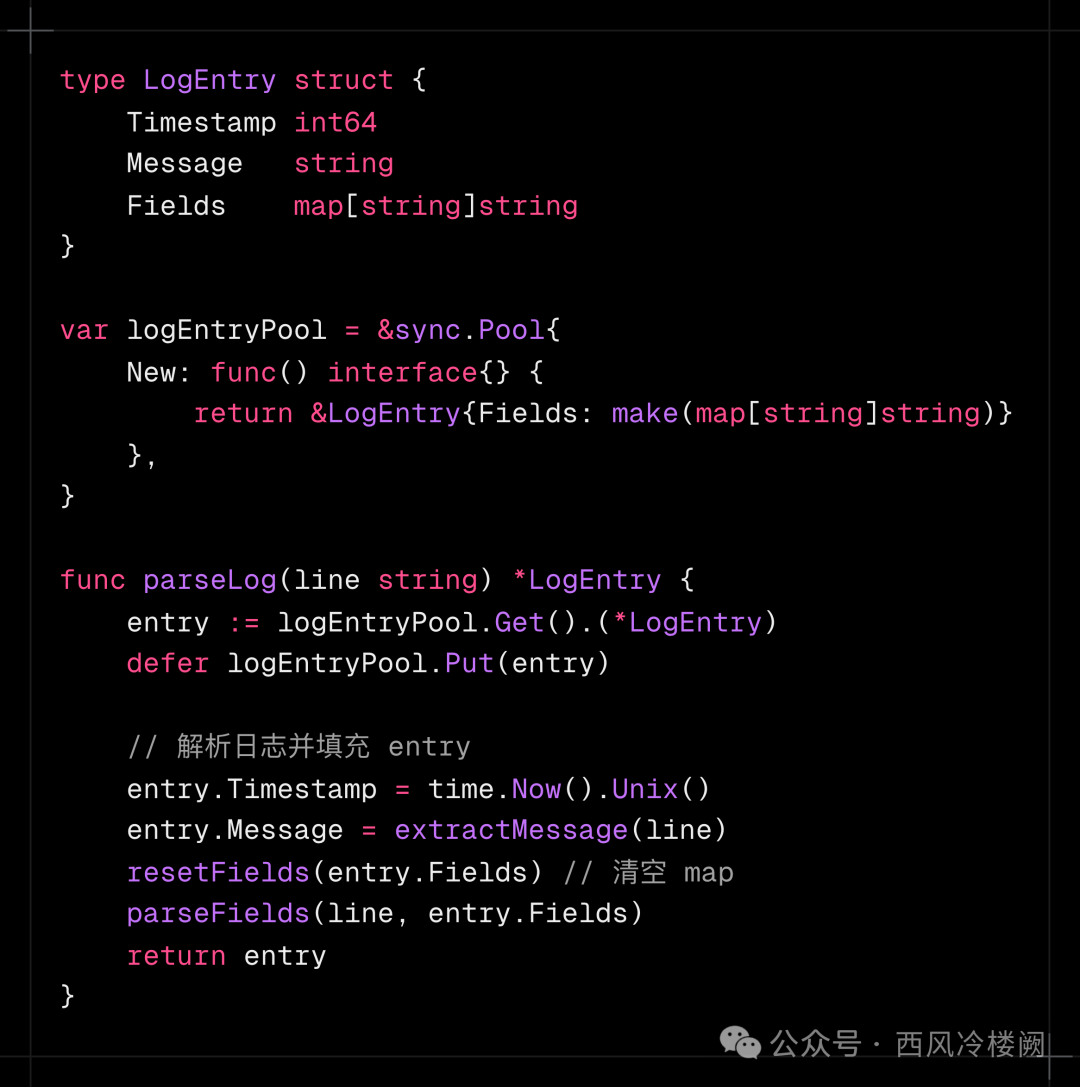
问题现象
- 内存占用波动剧烈:服务内存使用量周期性骤增,与 GC 周期高度相关。
- 解析性能下降:日志处理吞吐量从 50 万条/秒下降到 30 万条/秒。
根因分析
- 大对象缓存失效:LogEntry 含 map 字段,初始化成本高,但 sync.Pool 的本地共享队列容量有限(动态扩展但受 GC 控制)。
- 对象放回逻辑缺陷:未在 Put 前清空 map,导致脏数据残留,部分协程误判对象不可用,触发额外 New 调用。
优化措施
- 重置对象状态:在 Put 前清空 map,确保对象复用安全。
- 手动管理对象池:改用基于 chan 的有界池,限制最大缓存数量(如 make(chan *LogEntry, 1000))。
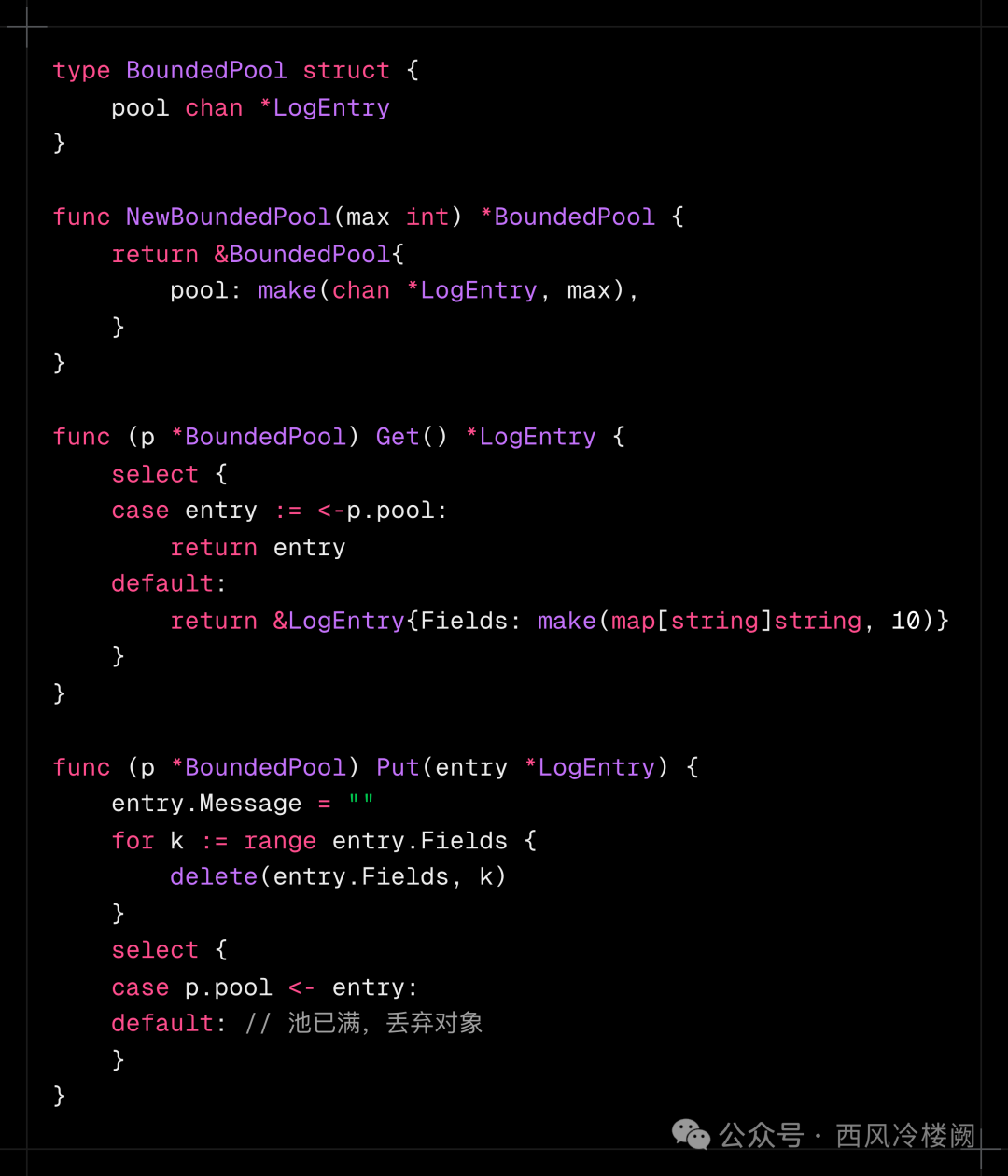
效果
- 内存占用趋于平稳,吞吐量恢复至 48 万条/秒。
- CPU 使用率下降 20%。
案例3:高并发图像处理服务 #
场景描述 图像处理服务需为每个请求分配 1MB 缓冲区,使用 sync.Pool 缓存。服务部署在 8 核服务器上(GOMAXPROCS=8),峰值 QPS 为 5 万。
问题现象
- 内存占用达 10GB+,远超预期。
- GC 停顿时间增加,影响实时性。
根因分析
- 大对象缓存不适用 sync.Pool:1MB 缓冲区被缓存后,GC 无法及时回收(sync.Pool 依赖 GC 清理机制)。
- 本地池对象积累:每个 P 的共享队列可能缓存多个大对象(poolChain 动态扩展),导致内存占用失控。
优化措施
- 限制池容量:通过全局计数器或 chan 实现有界池,强制丢弃超限对象。
- 改用手动内存管理:对于大对象,使用 slice 预分配内存池(如 var bufferPool = make([]*bytes.Buffer, 0, 1000))。
总结 #

解决方案
- 优先缓存小对象(如 <4KB 的缓冲区),避免大对象占用内存。
- 高频短生命周期对象适用 sync.Pool,长生命周期对象需手动管理。
- 分片池(Sharded Pool):按对象类型或大小分片,减少竞争。
- 有界池(Bounded Pool):通过 chan 或计数器限制最大缓存数量。
- 预热对象池:服务启动时预先填充对象,避免冷启动时的 New 风暴。
- 监控与调优:通过 pprof 分析 New 调用频率,结合业务负载调整池策略。
关于“返回池对象引用” #
假设代码实现如下,请问在使用时会产生什么问题?
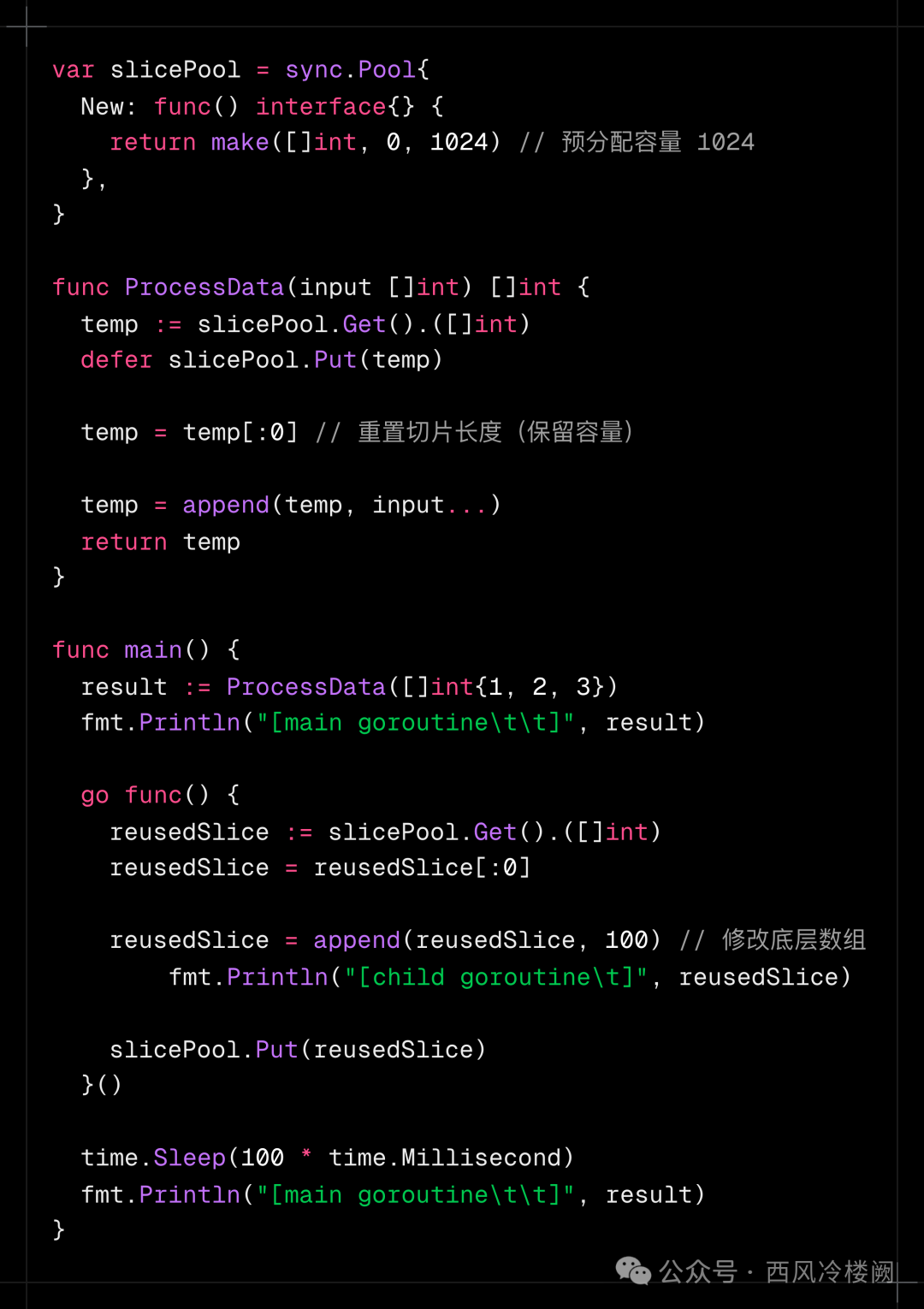
简单来说,因为切片 []int 不仅在函数内部使用,还传递给外面使用,这样会产生 data race 问题。
因为涉及到 切片底层数组共享 和 并发环境下的数据竞争风险,让我们通过底层原理逐步分析。
1. 问题核心 #
- sync.Pool 复用的是切片的 底层数组,而非切片本身。
- 当多个 Goroutine 通过 Get() 获取同一个底层数组的切片时,它们可能并发修改同一块内存区域。
2. 代码关键逻辑 #
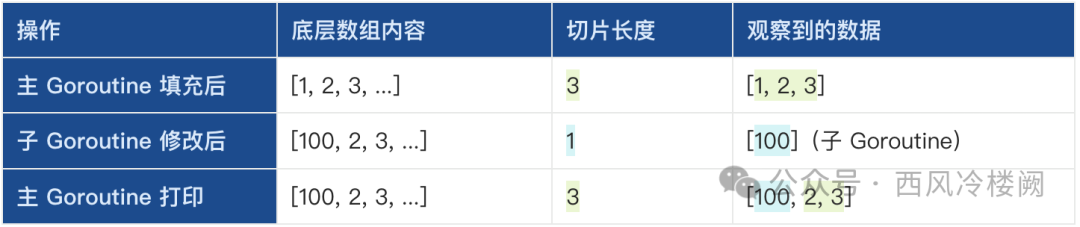
主 Goroutine 调用 ProcessData([]int{1,2,3}):
- 从 slicePool 获取一个底层容量为 1024 的切片 temp。
- 重置切片长度为 0(temp = temp[:0])。
- 追加 [1,2,3],此时 temp 的底层数组内容为 [1,2,3],长度为 3。
- 返回 temp 的引用给 result。
- 通过 defer slicePool.Put(temp) 将 temp 放回池中。
子 Goroutine:
- 从 slicePool 获取同一个底层数组的切片 reusedSlice(假设主 Goroutine 已放回)。
- 重置切片长度为 0(reusedSlice = reusedSlice[:0])。
- 追加 100,此时底层数组内容为 [100,2,3](覆盖第一个元素),长度为 1。
- 将 reusedSlice 放回池中。
主 Goroutine 打印 result:
- result 是主 Goroutine 中 ProcessData 返回的切片,其长度为 3,底层数组已被子 Goroutine 修改为 [100,2,3]。
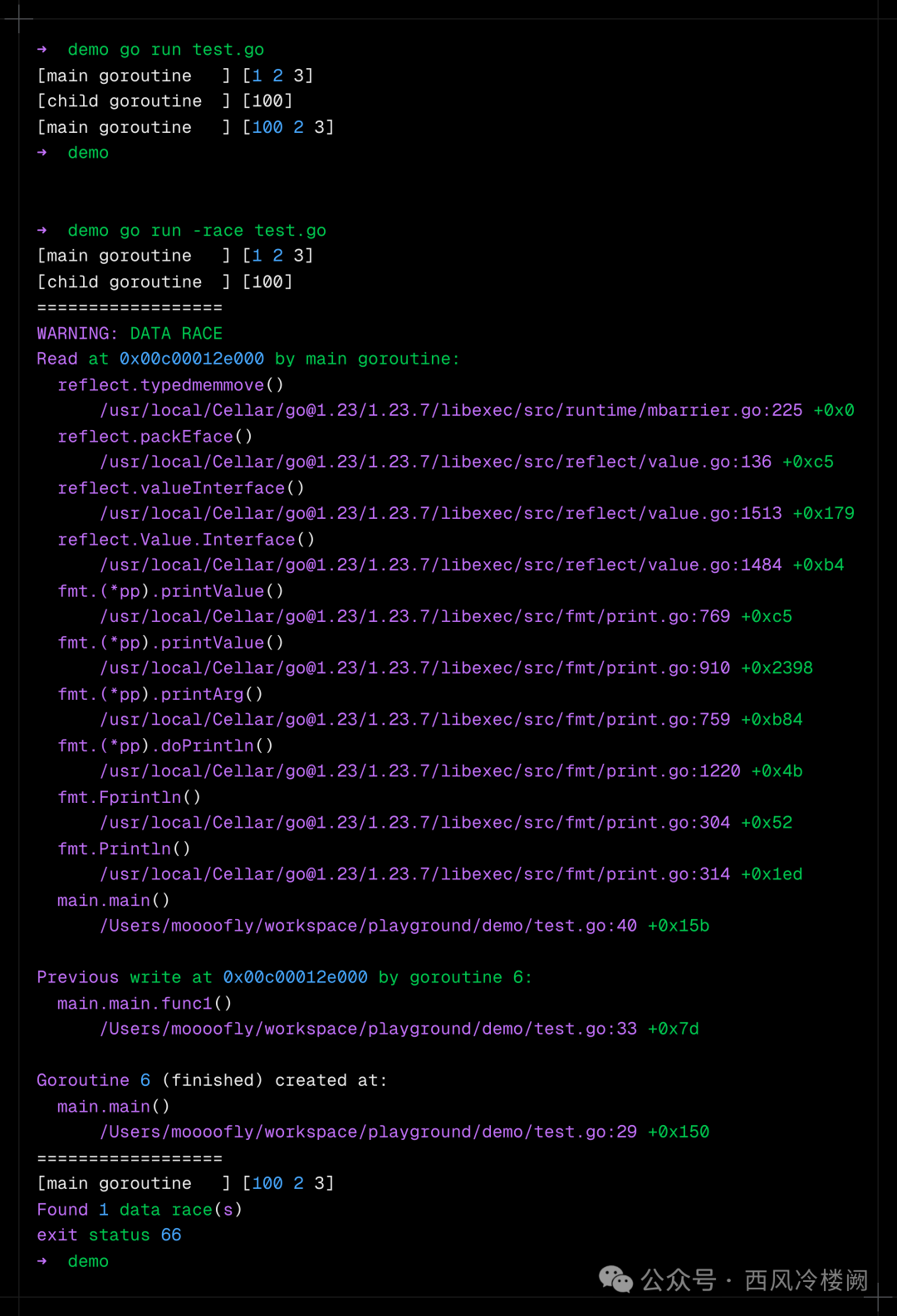
- 最终输出 [100,2,3]。
内存数据变化情况如下:
3.运行结果 #
4. 问题根源 + 修复方案 #
问题根源
- 切片所有权不明确:ProcessData 返回的切片仍引用池中的底层数组,外部代码可能长期持有该引用。
- 并发修改未隔离:多个 Goroutine 可能同时操作同一底层数组。
方案 1:深拷贝返回结果 #
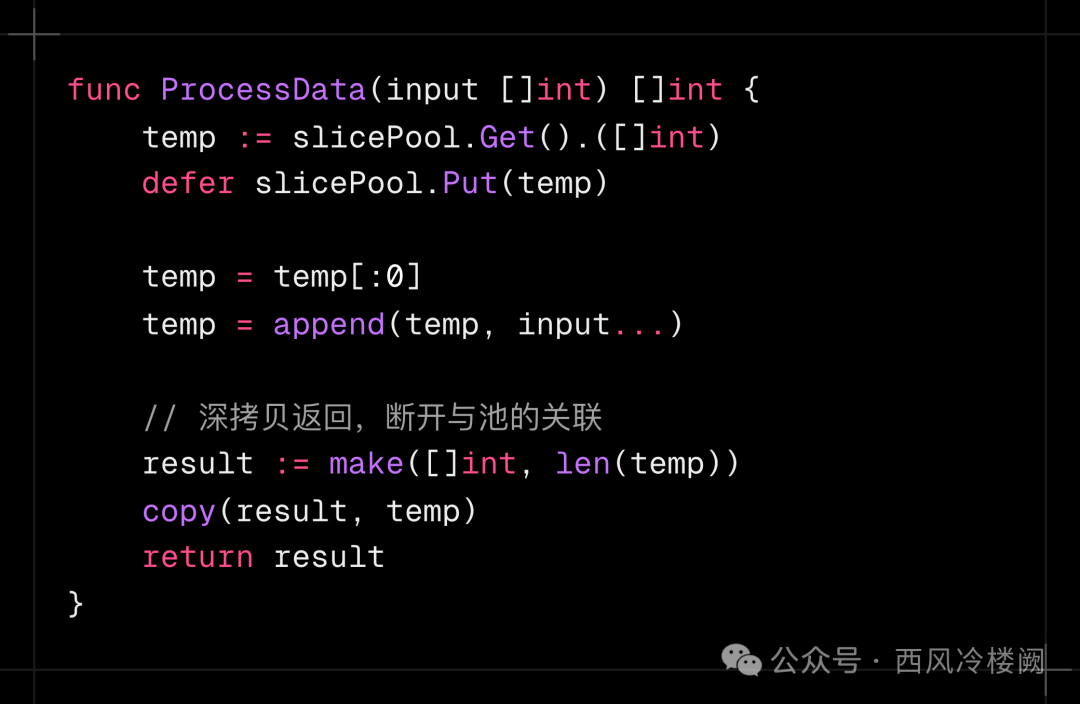
- 优点:深拷贝后,result 是独立的内存副本,与池对象解耦,彻底隔离池对象与外部引用。
- 缺点:增加内存分配开销,抵消池的部分性能优势。
方案 2:禁止返回池对象 #
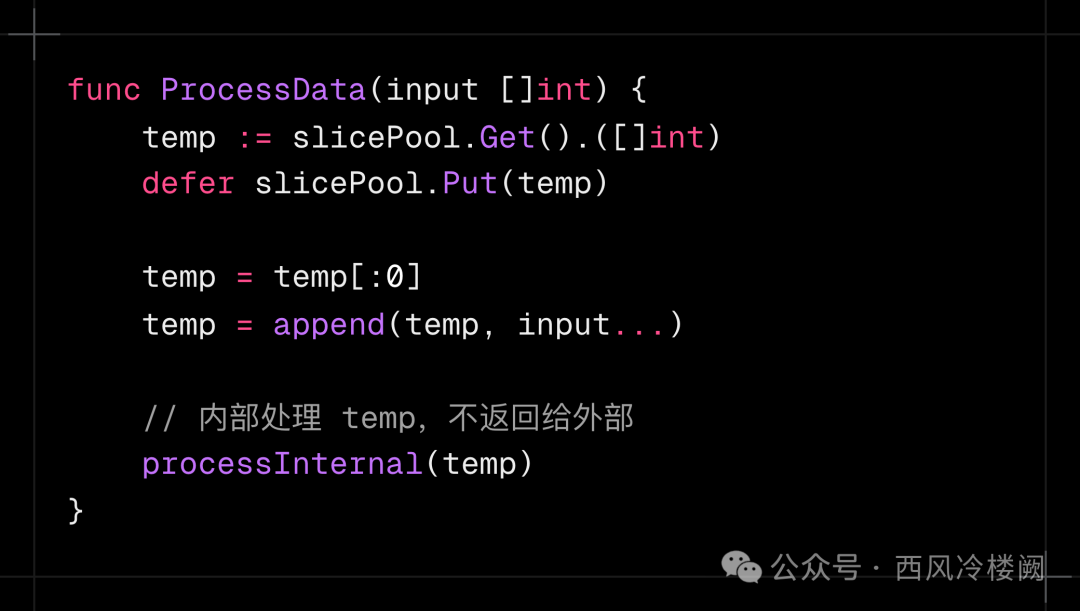
- 优点:完全控制池对象的生命周期。
- 缺点:限制 API 设计灵活性。
5. 结论 #
- 始终彻底重置对象状态,避免脏数据。
- 避免在池中存放有状态的长期对象,确保对象生命周期短暂。
- 合理设置对象初始容量(如切片、Map 的预设大小),减少扩容开销。
- 避免返回池对象引用,限制池对象作用域:池对象仅在局部作用域内使用,不应暴露给外部。若需返回数据,则必须深拷贝。
- 启用竞态检测:开发阶段通过 -race 标志检测潜在并发问题。