第一章 概述 #
go语言特征 #
-
简单
-
并发模型
go语言从根部将一切都并发化,运行时用Goroutine运行所有的一切,包括main.main入口函数。Goroutine是go的显著特征。它用类协程的方式处理并发单元,又在运行时层面做了更深度的优化处理。搭配channel,实现CSP模型。
csp模型
Actor 模型中 Actor 之间就是不能共享内存的,彼此之间通信只能依靠消息传递的方式。Golang 实现的 CSP 模型和 Actor 模型看上去非常相似,虽然 Golang 中协程之间,也能够以共享内存的方式通信,但是并不推荐;而推荐的以通信的方式共享内存,实际上指的就是协程之间以消息传递方式来通信。
Channel模型中,worker之间不直接彼此联系,而是通过不同channel进行消息发布和侦听。消息的发送者和接收者之间通过Channel松耦合,发送者不知道自己消息被哪个接收者消费了,接收者也不知道是哪个发送者发送的消息。
Go语言的CSP模型是由协程Goroutine与通道Channel实现:
- Go协程goroutine: 是一种轻量线程,它不是操作系统的线程,而是将一个操作系统线程分段使用,通过调度器实现协作式调度。是一种绿色线程,微线程,它与Coroutine协程也有区别,能够在发现堵塞后启动新的微线程。
- 通道channel: 类似Unix的Pipe,用于协程之间通讯和同步。协程之间虽然解耦,但是它们和Channel有着耦合。
-
内存分配
刨去因配合垃圾回收器而修改的内容,内存分配器完整的保留了tcmalloc的原始架构。除偶尔因性能问题而被迫采用对象池和自主内存管理外,我们基本无须参与内存管理操作。
-
垃圾回收
go垃圾回收不咋地
- 静态链接
只须编译一个可执行文件,无须附加任何东西就能部署。将运行时、依赖库直接打包到可执行文件内部,简化了部署和发布操作,无须事先安装运行环境和下载诸多第三方库。
- 标准库
- 工具链
设计初衷 #
- 少即是多(less is more):如果一个特性并不对解决任何问题有显著价值,那么go就不提供它;如果需要一个特性,那么只有一种方法去实现
- 面向接口编程:非侵入式接口,反对继承、反对虚函数和虚函数重载(多态)、删除构造和析构函数
- 正交+组合的语言特性:语言的特性之间相互独立,不相互影响。比如类型和方法是互相独立的,类型之间也是相互独立的,没有子类,包也没有子包。不同特性用组合的方式来松耦合
- 并发在语言层面支持:并发更好利用多核,有更强的表现力来模拟真实世界
在设计上,Go秉承了C的简单粗暴。
为什么没有继承 #
Go没有子类型的概念,只能把类型嵌入到另一个类型中,所以没有类型系统。Go的作者认为类型系统被过度使用了,应该在这个方向上退一步。
- 使用伸缩性良好的组合,而不是继承
- 数据和方法不再绑定在一起,数据的集合用struct,方法的集合用interface,保持正交
类似子类父类的系统造成非常脆弱的代码。类型的层次必须在早期进行设计,通常会是程序设计的第一步,但是一旦写出程序后,早期的决策就很难进行改变了。所以,类型层次结构会促成早期的过度设计,因为程序员要尽力对软件可能需要的各种可能的用法进行预测,不断地为了避免挂一漏万,不断的增加类型和抽象的层次。这种做法有点颠倒了,系统各个部分之间交互的方式本应该随着系统的发展而做出相应的改变,而不应该在一开始就固定下来。
作者附了一个例子,是一些以接口为参数并且其返回结果也是一个接口的函数:
// 入参是接口的函数,而不是成员方法
func ReadAll(r io.Reader) ([]byte, error)
// 封装器 - 出入参都是接口
func LoggingReader(r io.Reader) io.Reader //读到的内容录入日志
func LimitingReader(r io.Reader, n int64) io.Reader //读n个字节停下来
func ErrorInjector(r io.Reader) io.Reader
这种组合+函数的模式是相当灵活的。如果用继承,我们可能会多三个io.Reader的定义;然后用多态去获得对应的功能
为什么没有异常? #
panic和recover这些函数是故意弄的不好用的,因为我们应该减少使用他们。不像Java库中使用异常那样,在go的库中这两个关键字几乎没有使用。
- 业务中的错误并不是真正的异常情况,if和return完全可以胜任,无需控制流
- 如果错误要使用特殊的控制结构,错误处理就会扭曲程序的控制流,非常复杂
- 显式的错误检查会迫使程序员在错误出现的时候对错误进行思考,并进行相应的处理,而不是推给前面的调用堆栈
毫无疑问这会使代码更长一些,但如此编码带来的清晰度和简单性可以弥补其冗长的缺点
为什么没有X? #
总结:Go的设计着眼于编程的便利性、编译的速度、概念的正交性以及支持并发和垃圾回收等功能。如果你在Go中找不到其他语言的X特性,那么只能说明这个特性不适合Go,比如它会影响编译速度或设计的清晰度,或者使得基础系统变得特别复杂。
第二章 类型 #
变量 #
定义 #
var a int //会自动初始化为0
var y=false //自动推断为bool类型
var x,y int
x=1
y=2 //定义完变量后再赋值
var a int =2
var a,s=100,"abc" //初始化
var (
x,y int
a,s=100,"abc" //字符串加“”
)
a:=100 //自动推导类型
a,s:=100,"abc"
注意:
* 定义变量,同时显示初始化
* 不能提供数据类型
* 只能用在函数内部
退化赋值 #
退化赋值的前提条件是:最少有一个新变量被定义,且必须是同一作用域。
fun main(){
x:=100
x,y:=200,"abc" //退化赋值操作,只有y是变量定义
}
fun main(){
x:=100
x:=200 //错误
}
在处理函数错误返回值时,退化赋值允许我们重复使用err变量。
多变量赋值 #
fun main(){
x,y:=1,2
x,y=y+2,x+2
}
4 3
匿名变量 #
匿名变量,丢弃数据不进行处理, _匿名变量配合函数返回值使用才有价值.
_,i,_,j:=1,2,3,4
编译器将未使用的变量当作错误。
命名 #
命名建议: #
- 以字母或下画线开始,由多个字母、数字和下画线组合而成。
- 区分大小写
- 使用驼峰拼写格式
- 局部变量优先使用短名
- 不要使用保留关键字
- 不建议使用与预定义常量、类型、内置函数相同的名字
- 专有名词通常会全部大写,eg: escapeHTML
符号名字首字母大小写决定了其作用域。首字母大写的为导出成员,可被包外引用,而小写则仅能在包内使用。
空标识符 #
通常作为忽略占位符使用,可作为表达式左值,无法读取内容。可用来临时规避编译器对未使用变量和导入包的错误检查。但它是预置成员,不能重新定义。
x,_:=strconv.Atoi("12")
fmt.println(x)
常量 #
定义 #
常量值必须是编译器可以确定对字符、字符串、数字或布尔值。
代码中不使用的常量不会发生编译错误,与变量不同。
const x,y int=123,0x22
const s = "hello,world"
const x = '点点滴滴' //错误
const (
i,f =1,0.123 //int , float64(默认)
b =false
)
const (
x uint16=12
y //与x类型,右值相同
s ="abc"
z //与s类型,右值相同
)
const (
ptrsize=unsafe.Sizeof(uintptr(0)) //返回数据类型的大小 uintptr是一个整数类型
strsize=len("hello,world!") //len返回长度,表示有几个元素,cap返回指定类型的容量,类型不同意义不同。
)
const (
x,y int =99,-999
b byte =byte(x) // x被指定为int类型,须显式转换为byte类型
n =uint8(y) //错误 右值不能超过常量类型的取值范围。
)
数字类型变量的字节数和取值范围如下:
- int8 1B -128~127
- int16 2B -32768~32767
- int32 4B -2147483648~2147483647
- int64 8B -9223372036854775808~9223372036854775807
枚举 #
« 左移运算符将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。
const(
x = iota //0 自增
y //1
z //2
)
const(
_ = iota //0
KB=1 <<(10*iota) //1<<(10*1)
MB //1<<(10*2)
GB //1<<(10*3)
)
const(
_,_ =iota,iota*10 //0,0*10
a,b //1,1*10
c,d //2,2*10
)
const(
a =iota //0
b //1
c =100 //100
d //100
e =iota //4(恢复itoa自增,计数包括c,d)
f //5
)
自增默认数据类型为int,可显式指定类型。
const(
a =iota //int
b float32 =iota //float32
c =iota //int (如果不指定iota,则与b数据类型相同)
)
在实际编码中,建议用自定义类型实现用途明确的枚举类型。但这并不能将取值范围限定在预定义的枚举值内。
type color byte //自定义类型 byte取值范围 -128-127
const(
black colot =iota //指定常量类型
red
blue
)
展开 #
不同于变量在运行期分配存储内存(非优化状态),常量通常会被编译器在预处理阶段直接展开,作为指令数据使用。
就是说常量不会分配存储空间,无法获取地址。
基本类型 #
| 类型 | 长度 | 默认值 | 说明 |
|---|---|---|---|
| bool | 1 | false | |
| byte | 1 | 0 | uint8 |
| int,uint | 4,8 | 0 | 默认整数类型,依据目标平台,32或64位 |
| int8,uint8 | 1 | 0 | -128~127,0~255 |
| int16,uint16 | 2 | 0 | -32768~32767,0~65535 |
| int32,uint32 | 4 | 0 | -21亿~21亿,0~42亿 |
| int64,uint64 | 8 | 0 | |
| float32 | 4 | 0.0 | |
| float64 | 8 | 0.0 | 默认浮点数类型 |
| complex64 | 8 | ||
| complex128 | 16 | ||
| rune | 4 | 0 | Unicode Code Point,int32 |
| uintptr | 4,8 | 0 | 足以存储指针的uint |
| string | "" | 字符串,默认值为空字符串,而非NULL | |
| array | 数组 | ||
| struct | 结构体 | ||
| function | nil | 函数 | |
| interface | nil | 接口 | |
| map | nil | 字典,引用类型 | |
| slice | nil | 切片,引用类型 | |
| channel | nil | 通道,引用类型 |
strconv #
strconv包提供了字符串与简单数据类型之间的类型转换功能。可以将简单类型转换为字符串,也可以将字符串转换为其它简单类型。
golang strconv**.ParseInt** 是将字符串转换为数字的函数,功能灰常之强大,看的我口水直流.
func ParseInt(s string, base int, bitSize int) (i int64, err error)
参数1 数字的字符串形式
参数2 数字字符串的进制 比如二进制 八进制 十进制 十六进制
参数3 返回结果的bit大小 也就是int8 int16 int32 int64
别名 #
byte alias for uint8
rune alias for int32
别名类型无需转换,可以直接赋值。
| 格式化指令 | 含义 |
|---|---|
| %% | 字面上的百分号,并非值的占位符 |
| %b | 一个二进制整数,将一个整数格式转化为二进制的表达方式 |
| %c | 一个Unicode的字符 |
| %d | 十进制整数 |
| %o | 八进制整数 |
| %x | 小写的十六进制数值 |
| %X | 大写的十六进制数值 |
| %U | 一个Unicode表示法表示的整型码值 |
| %s | 输出字符串表示(string类型或[]byte) |
| %t | 以true或者false的方式输出布尔值 |
| %q | 双引号围绕的字符串,由Go语法安全地转义 |
| %p | 十六进制表示,前缀 0x |
| %T | 相应值的类型 |
| %v | 只输出所有的值 相应值的默认格式 |
| %+v | 先输出字段类型,再输出该字段的值 |
| %#v | 先输出结构体名字值,再输出结构体(字段类型+字段的值) |
| # | 备用格式:为八进制添加前导 0(%#o)。 为十六进制添加前导 0x(%#x) |
Go语言fmt包中%(占位符)使用 #
具体看下面链接
https://blog.csdn.net/zp17834994071/article/details/108619759
math包中常用的方法 #
package main
import (
"fmt"
"math"
)
func main() {
/*
取绝对值,函数签名如下:
func Abs(x float64) float64
*/
fmt.Printf("[-3.14]的绝对值为:[%.2f]\n", math.Abs(-3.14))
/*
取x的y次方,函数签名如下:
func Pow(x, y float64) float64
*/
fmt.Printf("[2]的16次方为:[%.f]\n", math.Pow(2, 16))
/*
取余数,函数签名如下:
func Pow10(n int) float64
*/
fmt.Printf("10的[3]次方为:[%.f]\n", math.Pow10(3))
/*
取x的开平方,函数签名如下:
func Sqrt(x float64) float64
*/
fmt.Printf("[64]的开平方为:[%.f]\n", math.Sqrt(64))
/*
取x的开立方,函数签名如下:
func Cbrt(x float64) float64
*/
fmt.Printf("[27]的开立方为:[%.f]\n", math.Cbrt(27))
/*
向上取整,函数签名如下:
func Ceil(x float64) float64
*/
fmt.Printf("[3.14]向上取整为:[%.f]\n", math.Ceil(3.14))
/*
向下取整,函数签名如下:
func Floor(x float64) float64
*/
fmt.Printf("[8.75]向下取整为:[%.f]\n", math.Floor(8.75))
/*
取余数,函数签名如下:
func Floor(x float64) float64
*/
fmt.Printf("[10/3]的余数为:[%.f]\n", math.Mod(10, 3))
/*
分别取整数和小数部分,函数签名如下:
func Modf(f float64) (int float64, frac float64)
*/
Integer, Decimal := math.Modf(3.14159265358979)
fmt.Printf("[3.14159265358979]的整数部分为:[%.f],小数部分为:[%.14f]\n", Integer, Decimal)
}
引用类型 #
特指slice、map、channel这三种预定义类型。相比数字、数组等类型,引用类型拥有更复杂的存储结构。除分配内存外,他们还须初始化一系列属性,诸如、长度,甚至包括哈希分布、数据队列等。
内置函数new按指定类型长度分配零值内存,返回指针,并不关心类型内部构造和初始化方式。而引用类型则必须使用make函数创建,编译器会将make转换为目标类型专用的创建函数(或指令),以确保完成全部内存分配和相关属性初始化。
就一句话 slice、map、channel只能用make函数创建。
new函数也可以为引用类型分配内存,但这不是完整的创建。以字典map为例,它仅分配零字典类型本身(实际就是个指针包装)所需内存,并没有分配键值存储内存,也没有初始化散列桶等内部属性,因此它无法正常工作。
func main(){ p:=new(map[string]int) //函数new返回指针 m:=*p m["a"]=1 //错误 fmt.println(m) }
类型转换 #
go强制要求使用显示类型转换。
a :=10
b :=byte(a)
c :=a + int(b) //混合类型表达式必须确保类型一致
语法歧义 #
如果转换的目标是指针、单向通道或没有返回值的函数类型,那么必须使用括号,以避免造成语法分解错误。
func main(){
x :=100
p :=*int(&x) //错误
p :=(*int)(&x) // 让编译器将*int解析为指针类型
println(p)
}
自定义类型 #
使用关键字type定义用户自定义类型。
即便指定了基础类型,也只表明它们有相同底层数据结构,两者间不存在任何关系,属于完全不同的两种类型。除操作符外,自定义类型不会继承基础类型的其他信息(包括方法)。不能视作别名,不能隐式转换,不能直接用于比较表达式。
func main(){ type data int var d data =10 var x int = d //错误 println(x) println(d ==x) //错误 }
未命名类型 #
数组、切片、字典、通道等类型与具体元素类型或长度等属性有关,故称作未命名类型。可用type为其提供具体名称,将其改变为命名类型。
具有相同声明的未命名类型被视作同一类型。
- 具有相同基类型的指针
- 具有相同元素类型和长度的数组
- 具有相同元素类型的切片
- 具有相同键值类型的字典
- 具有相同数据类型及操作方向的通道
- 具有相同字段序列的结构体
- 具有相同签名的函数
- 具有相同方法集的接口
未命名类型转换规则:
- 所属类型相同
- 基础类型相同,且其中一个是未命名类型
- 数据类型相同,将双向通道赋值给单向通道,且其中一个为未命名类型
- 将默认值nil赋值给切片、字典、通道、指针、函数或接口
- 对象实现了目标接口
第三章 表达式 #
保留字 #
go语言仅25个保留关键字(keyword)。
运算符 #
没有乘幂和绝对值运算符,对应的是标准库math里的Pow、Abs函数实现。
算术运算符 #
假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| – | 自减 | A– 输出结果 9 |
关系运算符 #
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| == | 相等于 | 4 == 3 | false |
| != | 不等于 | 4 != 3 | true |
| < | 小于 | 4 < 3 | false |
| > | 大于 | 4 > 3 | true |
| <= | 小于等于 | 4 <= 3 | false |
| >= | 大于等于 | 4 >= 1 | true |
逻辑运算符 #
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| ! | 非 | !a | 如果a为假,则!a为真; 如果a为真,则!a为假。 |
| && | 与 | a && b | 如果a和b都为真,则结果为真,否则为假。 |
| || | 或 | a || b | 如果a和b有一个为真,则结果为真,二者都为假时,结果为假。 |
有逻辑运算符连接的表达式叫做逻辑表达式
位运算符 #
位运算符对整数在内存中的二进制位进行操作。
下表列出了位运算符 &, |, 和 ^ 的计算:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假定 A = 60; B = 13; 其二进制数转换为:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&“是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符”|“是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符”^“是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| « | 左移运算符”«“是双目运算符。左移n位就是乘以2的n次方。 其功能把”«“左边的运算数的各二进位全部左移若干位,由”«“右边的数指定移动的位数,高位丢弃,低位补0。 | A « 2 结果为 240 ,二进制为 1111 0000 |
| » | 右移运算符”»“是双目运算符。右移n位就是除以2的n次方。 其功能是把”»“左边的运算数的各二进位全部右移若干位,"»“右边的数指定移动的位数。 | A » 2 结果为 15 ,二进制为 0000 1111 |
位移右操作数必须是无符号整数,或可以转换的无显式类型常量。
func main(){ b:=23 //b是有符号int类型变量 a:=1 << b //错误 println(a) }
- 按位 与 的运算规则是,如果两数对应的二进制位都为 1,那么结果为 1, 否则结果为 0。
- 按位 或 的运算规则是,如果两数对应的二进制位有一个为 1,那么结果为 1, 否则结果为 0。
- 按位 异或 的运算规则是如果两数对应的二进制位不同,那么结果为 1, 否则结果为 0。
a := 16 >> 3 *// 16除以2的3次方*
a := 1 << 3 // 2的3次方*1
赋值运算符 #
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| «= | 左移后赋值 | C «= 2 等于 C = C « 2 |
| »= | 右移后赋值 | C »= 2 等于 C = C » 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
其他运算符 #
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
运算符优先级 #
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 5 | * / % « » & &^ |
| 4 | + - | ^ |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
初始化 #
type data struct{
x int
s string
}
d:=data{
1,
"abc" //错误,须以逗号或者右花括号结束
}
流程控制 #
if…else… #
比较特别的是对初始化语句的支持,可定义块局部变量或执行初始化函数。
func main(){ x:=10 if xinit();x==0{ //优先执行xinit函数 println("a") } if a,b :=x+1,x+10; a<b{ //定义一个或多个局部变量(也可以是函数返回值) println(a) }else{ println(b) } }局部变量的有效范围包含整个if/else块。
死代码:是指永远不会执行的代码,可使用专门的工具或用代码覆盖率测试进行检查。
switch #
switch-case结构语法如下:
switch 变量或者表达式的值{
case 值1:
要执行的代码
case 值2:
要执行的代码
case 值3:
要执行的代码
………………………………..
default:
要执行的代码
}
func main(){
a,b,c,d,x:=1,2,3,2
switch x {
case a,b: //多个匹配条件中其一即可。
println("a | b")
case c:
println("c")
case 4:
println("d")
default:
println("z")
}
}
输出:a | b
switch 同样支持初始化语句,按从上到下、从左到右顺序匹配case执行。只有全部匹配失败时,才会执行default块。
func main(){
switch x:=5;x{
default: //不会先执行这个
x+=100
println(x)
case 5:
x +=50
println(x)
}
}
相邻的空case不构成多条件匹配。
switch x{
case a: //隐式:case a : break
case b:
println(c)
}
无须显式执行break语句,case执行完毕后自动中断。如需贯通后续case,须执行fallthrough,但不再匹配后续条件表达式。fallthrough必须放在case块结尾,可用break语句阻止。
func main{
switch x:=5;x{
default:
println(x)
case 5:
x +=10
//break 终止 不再执行后续语句
fallthrough //继续执行下一case,不在匹配条件表达式 也不会执行dēfault
case 6:
x +=3
println(x)
}
}
for #
语法结构如下:
for 表达式1;表达式2;表达式3{
循环体
}
for range #
可用for…range完成数据迭代。
允许返回单值
无论是for循环,还是range迭代,其定义的局部变量都会重复使用。
func main(){
data :=[3]string{"a","b","c"}
for i,s:=range data{
println(&i,&s)
}
}
输出: //重复使用地址。
0xc82003fe98 0xc82003fec8
0xc82003fe98 0xc82003fec8
0xc82003fe98 0xc82003fec8
range会复制目标数据
func main(){
data := [3]int{10,20,30}
for i,x :=range data { //从data复制品中取值
if i==0 {
data[0] +=100
data[1] +=200
data[2] +=300
}
fmt.printf("x: %d,data: %d\n",x,data[i])
}
for i,x :=range data[:]{
if i ==0{
data[0] +=100
data[1] +=200
data[2] +=300
}
fmt.printf("x: %d,data: %d\n",x,data[i])
}
}
输出:
x:10,data:110 //range返回的依旧是复制值
x:20,data:220
x:30,data:330
x:110,data:210 //当i==0修改data时,x已取值,所以是110
x:420,data:420 //复制的仅是slice自身,底层array依旧是原对象
x:630,data:630
如果range目标表达式是函数调用,也仅被执行一次。
select语句 #
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。
select 随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的。
Go 编程语言中 select 语句的语法如下:
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
以下描述了 select 语句的语法:
-
每个 case 都必须是一个通信
-
所有 channel 表达式都会被求值
-
所有被发送的表达式都会被求值
-
如果任意某个通信可以进行,它就执行,其他被忽略。
-
如果有多个 case 都可以运行,Select 会随机公平地选出一个执行。其他不会执行。
否则:
- 如果有 default 子句,则执行该语句。
- 如果没有 default 子句,select 将阻塞,直到某个通信可以运行;Go 不会重新对 channel 或值进行求值。
func main() {
var c1, c2, c3 chan int
var i1, i2 int
select {
case i1 = <-c1:
fmt.Printf("received ", i1, " from c1\n")
case c2 <- i2:
fmt.Printf("sent ", i2, " to c2\n")
case i3, ok := (<-c3): *// same as: i3, ok := <-c3*
if ok {
fmt.Printf("received ", i3, " from c3\n")
} else {
fmt.Printf("c3 is closed\n")
}
default:
fmt.Printf("no communication\n")
}
}
以上代码执行结果为:
no communication
goto, continue,break #
| 控制语句 | 描述 |
|---|---|
| break 语句 | 经常用于中断当前 for 循环或跳出 switch 语句或select语句。 |
| continue 语句 | 仅用于for循环,跳过当前循环的剩余语句,然后继续进行下一轮循环。 |
| goto 语句 | 将控制转移到被标记的语句。 |
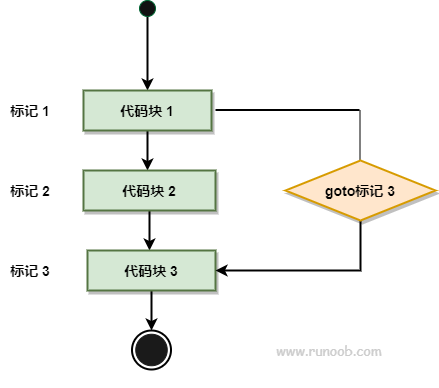
goto #
语法格式如下:
goto label;
..
.
label: statement;
未使用的标签会引发编译错误。
goto 语句流程图如下:
package main
import "fmt"
func main() {
var a int = 10
LOOP: for a < 20 {
if a == 15 {
a = a + 1
goto LOOP
}
fmt.Printf("a的值为 : %d\n", a)
a++
}
}
以上实例执行结果为:
a的值为 : 10
a的值为 : 11
a的值为 : 12
a的值为 : 13
a的值为 : 14
a的值为 : 16
a的值为 : 17
a的值为 : 18
a的值为 : 19
不能跳转到其他函数,或内层代码块
func test(){ test: println("test") } func main(){ for i:=0; i<3; i++{ loop: println(i) } goto test //不能跳转到其他函数 goto loop //不能跳转到内层代码块内 }
第四章 函数 #
定义 #
Go 语言函数定义格式如下:
func 函数名( 参数列表 ) 返回类型 {
函数体
}
函数只能判断是否为nil,不支持其他比较操作。
func a(){}
func b(){}
func main(){
println(a == nil)
println(a == b) //错误
}
建议命名规则:
- 通常是动词和介词加上名称,例如scanWords。
- 避免不必要的缩写,printError要比printErr更好一些
- 避免使用类型关键字,比如buildUserStruct看上去会很别扭
- 避免歧义,不能有多种用途的解释造成误解
- 避免只能通过大小写区分的同名函数
- 避免与内置函数同名,这会导致误用
- 避免使用数字,除非是特定专有名词,例如utf8
- 避免添加作用域提示前缀
- 统一使用camel/pascal case拼写风格
- 使用相同术语,保持一致性
- 使用习惯用语,比如init表示初始化,is/has返回布尔值结果
- 使用反义词组命名行为相反的函数,比如get/set、min/max等
参数 #
go不支持有默认值对可选参数,不支持命名参数。调用时,必须按签名顺序传递指定类型和数量的实参,就算以_命名的参数也不能忽略。
形参是指函数定义中的参数,实参则是函数调用时所传递的参数。行参类似函数的局部变量,而实参则是函数外部对象,可以是常量,变量,表达式或函数等。
参数可视作函数局部变量,因此不能在相同层次定义同名变量。
func add(x,y int)int{
x:=100 //错误
var y int //错误
return x+y
}
不管是指针、应用类型、还是其他类型参数,都是值拷贝传递。区别无非是拷贝目标对象,还是拷贝指针而已。在函数调用前,会为行参和返回值分配内存空间,并将实参拷贝到形参内存。尽管实参和形参都指向同一目标,但传递指针时依然被复制。
func test(p **int){
x:=100
*p=&x
}
func main(){ //二级指针的使用
var p *int
test(&p)
println(*p)
}
变参 #
变参本质上就是一个切片。只能接收一到多个同类型参数,且必须放在列表尾部。
func test(s string,a ...int){
fmt.printf("%T,%v\n",a,a) //显示类型和值
}
func main(){
test("abc",1,2,3,4)
}
将切片作为变参时,须进行展开操作。如果是数组,先将其转换为切片。
func test(a ...int){
fmt.println(a)
}
func main(){
a:=[3]int{1,2,3}
test(a[:]...)//如果是数组,先将其转换为切片。
}
既然变参是切片,那么参数复制的仅是切片自身,并不包括底层数组,也因此可修改原数据。如果需要,可用内置函数copy复制底层数据。
func test(a ...int){
for i:=range a{
a[i] +=100
}
}
func main(){
a:=[]int{10,20,30}
test(a...)
fmt.println(a)
}
输出:
[110 120 130]
func test(a ...[3]int){ //这里要加容量
fmt.println(a)
}
func main(){
s2 := make([][3]int, 5) //记住这种特殊情况
test(s2[3]...)
}
/*---------------*/
func test(a ...int){ //这里要加容量
fmt.println(a)
}
func main(){
s2 := make([][]int, 5) //记住这种特殊情况
test(s2[3]...)
}
返回值 #
有返回值的函数,必须有明确的return终止语句。
除非有panic,或者无break的死循环,则无须return终止语句。
稍有不便的是没有元组类型,也不能用数组、切片接收,但可以用_忽略掉不想要的返回值。多返回值可用作其他函数调用实参,或当作结果直接返回。
匿名函数 #
匿名函数是指没有定义名字符号的函数。
我们可以在函数内定义匿名函数,形成类似嵌套效果。匿名函数可直接调用,保存到变量,作为参数或返回值。
直接使用
func main(){
func(s string){
println(s)
}("hello,world!") //匿名函数的参数
}
赋值给变量
func main(){
add:=func(x,y int)int{
return x+y
}
println(add(1,2))
}
作为参数
func test(f func()){
f()
}
func main(){
test(func() {
println("hello,world")
})
}
作为返回值
func test()func(int , int) int{
retrun func(x,y int) int{
return x+y
}
}
func main(){
add:=test()
println(add(1,2))
}
将匿名函数赋值给变量,与为普通函数提供名字标识符有着根本的区别。但编译器会为匿名函数生成一个“随机”符号名。
普通函数和匿名函数都可以作为结构体字段,或经通道传递。
除闭包因素外,匿名函数也是一种常见的重构手段。可将大函数分解成多个相对独立的匿名函数块,然后用相对简洁的调用完成逻辑流程,实现框架和细节分离。
相比语句块,匿名函数的作用域被隔离(不使用闭包),不会引发外部污染,更加灵活。没有定义顺序限制,必要时可抽离,便于实现干净、清晰的代码层次。
闭包 #
闭包是在其词法上下文中引用了自由变量的函数,或者说是函数和其引用环境的组合体。
func test(x int) func(){
return func(){
println(x)
}
}
func main(){
f:=test(123)
f()
}
test返回的匿名函数会引起上下文环境变量x。当该函数在main中执行时,它依然可以正确读取x的值,这种现象就称作闭包。
闭包直接引用了原环境变量。返回的不仅仅是匿名函数,还包括所引用的环境变量指针。
正因为闭包通过指针引用环境变量,那么可能会导致其生命周期延长,甚至被分配到堆内存。另外,还有所谓“延迟求值”的特性。
延迟调用 #
语句defer向当前函数注册稍后执行的函数调用。这些调用被称作延迟调用,因为它们直到当前函数执行结束前才被执行,常用于资源释放、解除锁定,以及错误处理等操作。
func main(){
f,err:=os.open("./main.go")
if err!=nil{
log.Fatalln(err)
}
defer f.close() //仅注册,直到main退出前才执行
... do something ...
}
延迟调用注册的是调用,必须提供执行所需参数(哪怕为空)。参数值在注册时被复制并缓存起来。
func main(){
x,y :=1,2
defer func(a int){
println("defer x,y =",a,y) //y为闭包引用
}(x) //给匿名函数传参 注册时复制调用参数
x +=100
y +=200
println(x,y)
}
输出:
101 202
defer x,y =1 202
延迟调用可修改当前函数命名返回值,但其自身返回值被抛弃。
多个延迟调用安装FILO先进先出次序执行。
编译器通过插入额外指令来实现延迟调用执行,而return和Panic语句都会终止当前函数流程,引发延迟调用。另外,return不是ret汇编指令,它会先更新返回值。
func test() (z int){
defer func(){
println("defer:",z)
z +=100
}()
return 100
}
func main (){
println("test:",test())
}
输出:
defer:100
test:200
错误处理 #
error #
标准库将error定义为接口类型,以便实现自定义错误类型。
type error interface{
Error() string
}
error总是最后一个返回参数。标准库提供了相关创建函数,可方便地创建包含简单错误文本的error对象。
错误变量通常以err作为前缀,且字符串内部全部小写,没有结束标点,以便于嵌入到其他格式化字符串中输出。
全局错误变量并非没有问题,因为它们可被用户重新赋值,这就可能导致结果不匹配。
与errors.New类似的还有fat.Errorf,它返回一个格式化内容的错误对象。
自定义错误类型:
type DivError struct{ //自定义错误类型
x,y int
}
func (DivError) Error() string{ //实现error接口方法
return "division by zero"
}
func div(x,y int)(int,error){
if y==0{
return 0,DivError{x,y}
}
return x/y,nil
}
自定义错误类型通常以Error为名称后缀。在用switch按类型匹配时,注意case顺序。应将自定义类型放在前面,优先匹配更具体的错误类型。
大量函数和方法返回error,会使得代码很难看,解决思路有:
- 使用专门的检查函数处理错误逻辑(比如记录日志),简化检查代码。
- 在不影响逻辑的情况下,使用defer延后处理错误状态(err退化赋值)。
- 在不中断逻辑的情况下,将错误作为内部状态保存,等最终“提交”时再处理。
panic,recover #
panic会立即中断当前函数流程,执行延迟调用。而在延迟调用函数中,recover可捕获并返回panic提交的错误对象。
func main(){
deefer func(){
if err:=recover();err!=nil{ //捕获错误
log.Fatalln(err)
}
}()
panic("i am dead") //引发错误
println("exit.") //永不会执行
}
error返回的是一般性的错误,但是panic函数返回的是让程序崩溃的错误。
也就是当遇到不可恢复的错误状态的时候,如数组访问越界、空指针引用等,这些运行时错误会引起painc异常,在一般情况下,我们不应通过调用panic函数来报告普通的错误,而应该只把它作为报告致命错误的一种方式。当某些不应该发生的场景发生时,我们就应该调用panic。
一般而言,当panic异常发生时,程序会中断运行。随后,程序崩溃并输出日志信息。日志信息包括panic value和函数调用的堆栈跟踪信息。
当然,如果直接调用内置的panic函数也会引发panic异常;panic函数接受任何值作为参数。
我们在实际的开发过程中并不会直接调用panic( )函数,但是当我们编程的程序遇到致命错误时,系统会自动调用该函数来终止整个程序的运行,也就是系统内置了panic函数。
Go语言为我们提供了专用于“拦截”运行时panic的内建函数——recover。它可以是当前的程序从运行时panic的状态中恢复并重新获得流程控制权。
因为Panic参数是空接口类型,因此可以使用任何对象作为错误状态。而recover返回结果同样要做转型才能获得具体信息。
无论是否执行recover,所有延迟调用都会被执行。但中断性错误会沿调用堆栈向外传递,要么被外层捕获,要么导致进程奔溃。
第五章 数据 #
字符串 #
字符串是个不可变字节(byte)序列,其本身是一个复合结构。
头部指针指向字节数组,但没有NULL结尾。默认以UTF-8编码存储Unicode字符,字面量里允许使用十六进制、八进制和UTF编码格式。
内置函数len返回字节数组长度,cap不接受字符串类型参数。
字符串默认值不是nil ,而是“”。
使用”`“定义不做转义处理的原始字符串(raw string),支持跨行。
func main(){
s:=`line\r\n,
line 2`
}
输出:
line\r\n,
line 2
编译器不会解析原始字符串内的注释语句,且前置锁进空格也属于字符串内容。
允许索引号访问字节数组(非字符),但不能获取元素地址。
func main(){
s:="abc"
println(s[1])
println(&s[1]) //错误
}
以切片语法(起始和结束索引号)返回子串时,其内部依旧指向原字节数组。
使用for遍历字符串时,分byte和rune两种方式。
func main(){
s:="雨痕"
for i:=0;i<len(s);i++{ //byte
fmt.printf("%d:[%c]\n",i,s[i])
}
for i,c:=rangs s{
fmt.printf("%d:[%c]\n",i,c) //rune:返回数组索引号,以及unicode字符
}
}
输出:
0:[e`]
1:[]
2:
...
0:[雨]
3:[痕]
rune是Go语言中一种特殊的数据类型,它是int32的别名,几乎在所有方面等同于int32,用于区分字符值和整数值。
字符串处理 #
Contains
func Contains (s, substrstring) bool
功能:字符串s中是否包含substr,返回bool值
var str string ="hellogo"
fmt.println(strings.contains(str,"go")) //返回值为true
Join
func Join (a[]string,sepstring) string
功能:字符串链接,把slicea通过sep链接起来
s :=[]string("abc","hello","mike")
buf :=strings.Join(s,"|")
fmt.println("buf=",buf)
输出:
buf=abc|hello|mike
Index
func Index (s,sepstring) int
功能:在字符串s中查找sep所在的位置,返回位置值,找不到返回-1
fmt.println(strings.Index("abcdhello","hello"))
fmt.println(strings.Index("abcdhello","go")) //不包含返回-1
输出:
4
-1
Repeat
func Repeat (sstring,countint) string
功能:重复s字符串count次,最后返回重复的字符串
buf:=strings.Repeat("go",3)
fmt.Println("buf=",buf) //"gogogo"
Replace
func Replace (s,old,newstring,nint)string
功能:在s字符串中,把old字符串替换为new字符串,n表示替换的次数,小于0表示全部替换
fmt.println(string.Replace("oink oink oink","k","ky",2))
fmt.println(string.Replace("oink oink oink","k","moo",-1))
输出:
oinky oinky oink
moo moo moo
Split
func Split (s,sepstring)[]string
功能:把s字符串按照sep分割,返回slice
buf:="hello@go@mike"
s2:=strings.Split(buf,"@")
fmt.println("s2=",s2)
输出:
s2=[hello abc go mike]
Trim
func Trim (sstring,cutsetstring)string
功能:在s字符串的头部和尾部去除cutset指定的字符串
buf:=strings.Trim(" are u ok? "," ") //去掉两头空格
fmt.println("buf=#%s#\n",buf)
输出:
buf=#are u ok?#
Fields
func Fields (sstring)[]string
功能:去除s字符串的空格符,并且按照空格分割返回slice
字符串转换 #
要修改字符串,须将其转换为可变类型([]rune或[]byte),待完成后再转换回来。但不管如何转换,都须重新分配内存,并复制数据。
相应的字符串转换函数都在”strconv”包。
Format 系列函数把其他类型的转换为字符串。
//将bool类型转换为字符串
var str string
str = strconv.FormatBool(false)
fmt.println(str)
//将整型转换为字符串
var str string
str = strconv.Itoa(666)
fmt.println(str)
//将浮点数转换为字符串
var str string
str = strconv.FormatFloat(3.14,'f',3,64)//'f'指打印格式,以小数方式,3指小数点位数,64以float64处理
fmt.println(str)
Parse系列函数把字符串转换为其他类型
//字符串转化其他类型
var flag bool
var err error
flag,err=strconv.ParseBool("true")
if err==nil{
fmt.println("flag=",flag)
}else{
fmt.println("err=",err)
}
//把字符串转换为整型
a,_:=strconv.Atoi("456")
fmt.println("a=",a)
b,err:=strconv.ParseFlat("123.34",64)
if err ==nil{
fmt.println("flag=",b)
}else{
fmt.println("err=",err)
}
Append 系列函数将整数等转换为字符串后,添加到现有的字节数组中
slice :=make([]byte,0,1024)
slice = strconv.AppendBool(slice,true)
slice = strconv.AppendInt(slice,1234,10) //第二个数为要追加的数,第三个为指定10进制方式追加。
slice = strconv.APPendQute(slice,"abc")
fmt.println("slice=",string(slice)) //转换string后再打印
结果:
slice=true1234"abc"
unicode #
类型rune专门用来存储Unicode码点(code point),它是int32的别名,相当于UCS-4/UTF-32编码格式。使用单引号的字面量,其默认类型就是rune。
除[]rune 外,还可以直接在rune,byte,string间进行转换。
数组 #
定义数组类型时,数组长度必须是非负整型常量表达式,长度是类型组成部分。也就是说元素类型相同,但长度不同的数组不属于同一类型。
初始化 #
func main(){
var a [4]int //元素自动初始化为零 [0 0 0 0]
b:=[4]int{2,5} //未提供初始值的元素自动化初始为0 [2 5 0 0]
c:=[4]int{5,3:10} //可指定索引位置初始化 [5 0 0 10]
d:=[...]int{1,2,3} //按初始化值数量确定数组长度 [1 2 3]
e:=[...]int{10,3:100} //支持索引初始化,但注意数组长度与此有关 [10 0 0 100]
}
对于结构等复合类型,可省略元素初始化类型标签。
type user struct{
name string
age byte
}
d:=[...]user{
{"tom",20},
{"mare",23}, //省略了类型标签
}
在定义多维数组时,仅第一维度允许使用”…“。
指针 #
指针数组:是指元素为指针类型的数组。
数组指针:是获取数组变量的地址。
func main(){
x,y:=10,20
a:=[...]*int{&x,&y} //元素为指针的指针数组
p:=&a //存储数组地址的指针
}
可获取任意元素地址。
a:=[...]int{1,2}
println(&a,&a[0],&a[1])
0xc82003ff20 0xc82003ff20 0xc82003ff28
数组指针可直接用来操作元素。
复制 #
go数组是值类型,赋值和传参操作都会复制整个数组数据。
切片 #
切片本身并非动态数组或数组指针。它内部通过指针引用底层数组,设定相关属性将数据读写操作限定在指定区域内。切片本身是个只读对象,其工作机制类似数组指针的一种包装。
切片:切片与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大,所以可以将切片理解成“动态数组”,但是,它不是数组。
type slice struct{
array unsafe.Pointer
len int
cap int
}
s:=[ ]int{ } //定义空切片
s:=[]int{1,2,3} //初始化切片
s =append(s,5,6,7) //通过append函数向切片中追加数据
fmt.println(s)
输出结果:[1 2 3 5 6 7]
var s1 []int //声明切片和声明数组一样,只是少了长度,此为空(nil)切片
//借助make函数, 格式 make(切片类型, 长度, 容量)
s := make([]int, 5, 10)
属性cap表示切片所引用数组片段的真实长度,len用于限定可读的写元素数量。另外,数组必须是addressable,否则会引发错误。
可直接创建切片对象,无须预先准备数组。因为是引用类型,须使用make函数或显示初始化语句,它会自动完成底层数组内存分配。
func main(){
s1:=make([]int,3,5) //指定le、cap,底层数组初始化为零
s2:=make([]int,s) //省略cap,和len相等
s3:=[]int{10,20,5:30} //按初始化元素分配底层数组,并设置len、cap
fmt.println(s3,len(s3),cap(s3))
}
输出:
[10 20 0 0 0 30] 6 6
func main(){ var a []int b:=[]int{} println(a==inl,b==nil) } 输出:true false前者仅定义了一个[]int类型变量,并未执行初始化操作,而后者则用初始化表达式完成了全部创建过程。
变量b的内部指针被赋值,a==nil,仅表示他是个未初始化的切片对象,切片本身依然会分配所需内存。
不支持比较操作,就算元素类型支持也不行,仅能判断是否为nil
func mian(){
a:=make([]int,1)
b:=make([]int,1)
println(a==b) //错误。不能比较
}
二维切片初始化,都是0
bp:=make([][]int,n)
for i:=range bp{
bp[i]=make([]int,n)
}
可以获取元素地址,但不能向数组那样直接用指针访问元素内容。
func main(){
s:=[]int{0,1,2,3,4}
p:=&s //取header地址
p0:=&s[0] //取array[0]地址
p1:=&s[1]
println(p,p0,p1)
(*p)[0]+=100 //*[]int 不支持索引操作,须先返回[]int 对象
*p +=100 //直接用元素指针操作
fmt.println(s)
}
输出:
0xc82003ff00 0xc8200141e0 0xc8200141e8
[100 101 2 3 4]
如果元素类型也是切片,那么就可以实现类似交错数组的功能
func main(){
x:=[][]int{
{1,2},
{10,20,30},
{100},
}
fmt.println(x[1])
x[2]=append(x[2],200,300)
fmt.println(x[2])
}
输出:
[10 20 30]
[100 200 300]
切片只是很小的结构体对象,用来代替数组传参可避免复制开销。make函数允许在运行期动态指定数组长度,绕开了数组类型必须使用编译器常量的限制。
并非所有时候都适合用切片代替数组,因为切片底层数组可能会在堆上分配内存。而且小数组在栈上拷贝的消耗也未必就比make代价大。
reslice #
将切片视作[cap]slice数据源,据此创建新切片对象。不能超出cap,但不受len限制。
s2=s1 [2:4:6]
len:2 cap:4
s[low:high:max]
从切片s的索引位置low到high处所获得的切片,len=high-low,cap=max-low
新建切片对象依旧指向原底层数组,也就是说修改对所有关联切片可见。
func main(){
d:=[...]int{0,1,2,3,4,5,6,7,8,9}
s1:=d[3:7]
s2:=s1[1:3]
for i:=range s2{
s2[i]+=100
}
fmt.println(d)
fmt.println(s1)
fmt.rpintln(s2)
}
输出:
[0 1 2 3 104 105 6 7 8 9]
[3 104 105 6] //就是说 修改会全部修改
[104 105]
append #
向切片尾部(slice[len])添加数据,返回新的切片对象。
数据被追加到原底层数组。如超出cap限制,则为新切片对象重新分配数组
正因为存在重新分配底层数组的缘故,在某些场合建议预留足够多的空间,避免中途内存分配和数据复制开销。
删除第i个元素 #
a = append(a[:i], a[i+1:]…) // 删除中间1个元素
a = append(a[:i], a[i+N:]…) // 删除中间N个元素
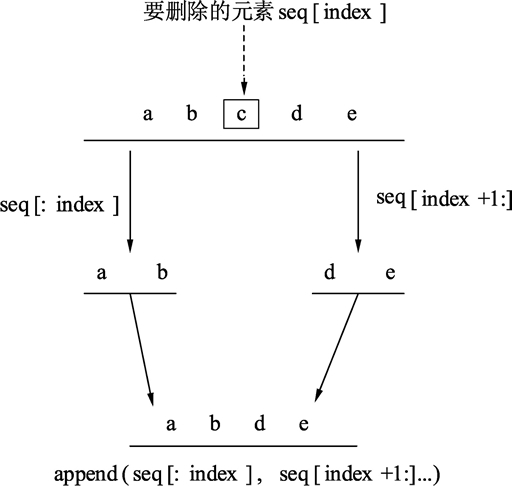
Go语言中删除切片元素的本质是,以被删除元素为分界点,将前后两个部分的内存重新连接起来。
在第i个位置增加元素 #
因为 append 函数返回新切片的特性,所以切片也支持链式操作,我们可以将多个 append 操作组合起来,实现在切片中间插入元素:
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 中。
copy #
在两个切片对象间复制数据,允许指向同一底层数组,允许目标区间重叠。最终所复制长度以较短的切片长度(len)为准。将第二个切片里面的元素,拷贝到第一个切片中。
返回值为int型,为返回复制的元素个数。
func main(){
s:=[]int{0,1,2,3,4,5,6,7,8,9}
s1:=s[5:8]
n:=copy(s[4:],s1) //在同一底层数组的不同区间复制
fmt.Println(n,s)
s2:=make([]int,6) //在不数组间复制
n=copy(s2,s)
fmt.println(n,s2)
}
输出:
3 [0 1 2 3 5 6 7 7 8 9]
6 [0 1 2 3 5 6]
还可直接从字符串中复制数据到[]byte
func main(){
b:=make([]byte,3)
n:=copy(b,"abcde")
fmt.println(n,b)
}
输出:
3 [97 98 99]
字典 #
字典(哈希表)是一种使用频率极高的数据结构。
作为无序键值对集合,字典要求key必须是支持相等运算符(== ,!=)的数据类型。比如,数字、字符串、指针
数组、结构体,以及对应接口类型。
字典是引用类型,使用make函数或初始化表达语句来创建。
func main(){
m:=make(map[string]int)
m["a"]=1
m["b"]=2
m2:=map[int]struct{ //值为匿名结构体类型
x int
}{
1: {x:100}, //可省略key,value类型标签
2: {x:200},
}
fmt.println(m,m2)
}
访问不存在的键值,默认返回零值,不会引发错误。但推荐使用ok-idiom模式,毕竟通过零值无法判断键值是否存在,或许存储的value本就是零。
func main(){
m:=map [string]int{
"a":1,
"b":2,
}
m["a"]=10
m["c"]=20
if v,ok:=m["d"];ok{ //使用ok-idiom判断key是否存在,返回值
println(v)
}
delete(m,"d") //删除键值对。不存在时,不会出错
}
map是无序的,对字典进行迭代,每次返回的键值次序都不同。
函数len返回当前键值对数量,cap不接受字典类型。字典是“not addressable”,故不能直接修改value成员(结构或数组)。
func main(){
type user struct{
name string
age byte
}
m:=map[int]sting{
1:{"tom",19},
}
m[1].age +=1 //错误
}
正确做法是返回整个value,待修改后再设置字典键值,会直接用指针类型。
type user struct{
name string
age byte
}
func main(){
m:=map[int]user{
1:{"tom",19},
}
u:=m[1]
u.age +=1
m[1] =u
m2:=map[int]*user{ //value是指针类型
1:&user{"jak",20}
}
m2[1].age++ //返回的是指针,可透过指针修改目标对象
}
不能对nil字典进行写操作,但能读
var m1 map[int]string //只是声明一个map,没有初始化, 为空(nil)map
fmt.Println(m1 == nil) //true
//m1[1] = "Luffy" //nil的map不能使用err, panic: assignment to entry in nil map
m4 := make(map[int]string, 10) //第2个参数指定容量
结构体 #
结构体将多个不同类型命名字段序列打包成一个复合类型。
字段名必须唯一,可用“—”补位,支持使用自身指针类型成员。字段名、排列顺序属类型组成部分。
type node struct{
_ int
id int
next *node
}
func main(){
n1:node{
id:1,
}
n2:node{
id:2,
next:&n1,
}
}
可按顺序初始化全部字段,或使用命名方式初始化指定字段。
func main(){
type user struct{
name string
age byte
}
u1:=user{"tom",12}
u2:=user{"tom"} //错误
}
JSON格式数据 #
该程序成功得到了JSON格式的数据,但存在一个小问题是JSON字段普遍使用驼峰命名,上面我们得到的则是大写开头的。只需添加标签即可解决这个问题:
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Hobbies[] string `json:"hobbies"`
}
我们还可以在标签种加上omitempty,使程序在将结构体数据转换为JSON格式是忽略空值:
type Person struct {
Name string `json:"name,omitempty"`
Age int `json:"age,omitempty"`
Hobbies[] string `json:"hobbies,omitempty"`
}
指针 #
内存地址是内存中每个字节单元的唯一编号,而指针则是一个实体。指针会分配内存空间,相当于一个专门用来保存地址的整型变量。
指针运算为左值时,我们可更新目标对象状态,而为右值时则为了获取目标状态。
func main(){ x:=10 var p *int =&x //取地址,保存到指针变量 *p +=20 //用指针间接引用,并更新对象 println(p,*p) }并非所有对象都能进行取地址操作
m:=map[string]int{"a":1} println(&m["a"]) //错误g
指针类型支持相等运算符,但不能做加减法运算和类型转换。
可通过unsafe.Pointer将指针转换为uintptr后进行加减法运算,但可能会造成非法访问。
Go语言保留了指针,但与C语言指针有所不同。主要体现在:
-
默认值 nil
-
操作符 “&” 取变量地址, “*” 通过指针访问目标对象
-
不支持指针运算,不支持 “->” 运算符,直接⽤ “.” 访问目标成员
指向指针的指针 #
如果一个指针变量存放的又是另一个指针变量的地址,则称这个指针变量为指向指针的指针变量。
当定义一个指向指针的指针变量时,第一个指针存放第二个指针的地址,第二个指针存放变量的地址:

指向指针的指针变量声明格式如下:
var ptr **int;
以上指向指针的指针变量为整型。
访问指向指针的指针变量值需要使用两个 * 号。
指针作为函数参数 #
Go 语言允许向函数传递指针,只需要在函数定义的参数上设置为指针类型即可。
指针作为参数进行传递时,为引用传递,也就是传递的地址。
以下实例演示了如何向函数传递指针,并在函数调用后修改函数内的值,:
package main
import "fmt"
func main() {
var a int = 100
var b int= 200
fmt.Printf("交换前 a 的值 : %d\n", a )
fmt.Printf("交换前 b 的值 : %d\n", b )
/* 调用函数用于交换值
&a 指向 a 变量的地址
&b 指向 b 变量的地址
*/
swap(&a, &b);
fmt.Printf("交换后 a 的值 : %d\n", a )
fmt.Printf("交换后 b 的值 : %d\n", b )
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址的值 */
*x = *y /* 将 y 赋值给 x */
*y = temp /* 将 temp 赋值给 y */
}
以上实例允许输出结果为:
交换前 a 的值 : 100
交换前 b 的值 : 200
交换后 a 的值 : 200
交换后 b 的值 : 100
第六章 方法 #
定义 #
方法是与对象实例绑定的特殊函数。方法是有关联状态的,而函数通常没有。
可以为当前包,以及除接口和指针以外的任何类型定义方法。
/* 定义结构体 */
type Circle struct {
radius float64
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("圆的面积 = ", c1.getArea())
}
//该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
方法同样不支持重载(overload)。receiver参数名没有限制,按惯例会选用简短有意义的名称(不推荐使用this、self)。如方法内部并不引用实例,可省略参数名,仅保留类型。
type N int
func (N) test(){
println("hi!")
}
方法可看作特殊的函数,那么receiver的类型自然可以是基础类型或指针类型。这会关系到调用时对象实例是否被复制。
type N int
func (n N) value (){
n++
fmt.Printf("v:%p,%v\n",&n,n)
}
func(n *N) pointer(){
(*n)++
fmt.Printf("p:%p,%v\n",n,*n)
}
func main(){
var a N=25
a.value()
a.pointer()
fmt.Printf("a:%p,%v\n",&a,a)
}
输出:
v:0xc8200741c8,26
p:0xc8200741c0,26
a:0xc8200741c0,26
可以使用实例值或指针调用方法,编译器会根据方法receiver类型自动在基础类型和指针类型之间转换。
不能用多级指针调用方法。
func main(){
var a N=25
p:=&a
p2:=&p
p2.value() //错误
p2.pointer() //错误g
}
指针类型的receiver必须是合法指针(包括nil),或能获取实例地址。
type x struct{}
func (x *X)test(){
println("hi",x)
}
func main(){
var a *x
a.test() //相当于test(nil)
x{},test() // 错误
}
如何选择方法的receiver类型?
- 要修改实例状态,用*T。
- 无须修改状态的小对象或固定值,建议用T。
- 大对象建议用*T,以减少复制成本。
- 引用类型、字符串、函数等指针包装对象,直接用T。
- 若包含Mutex等同步字段,用*T,避免因复制造成锁操作无效。
- 其他无法确定的情况,都用*T。
匿名字段 #
可以像访问匿名字段成员那样调用其方法,由编译器负责查找。
type data struct{
sync.Mutex
buf [1024]byte
}
func main(){
d:=data{}
d.Lock() //编译会处理为sync.(*Mutex).Lock()调用
defer d.Unlock()
}
同名遮蔽问题,利用这种特性,可实现类似覆盖(override)操作。
type user struct{}
type manager struct{
user
}
func (user) toString() string{
return "user"
}
func (m manager) toString()string{
retrun m.user.toString()+";manager"
}
func main(){
var m manager
println(m.toString())
println(m.user.toString())
}
输出:
user;manager
user
尽管能直接访问匿名字段的成员和方法,但它们依然不属于继承关系。
方法集 #
类型有一个与之相关的方法集(method set),这决定了它是否实现某个接口。
- 类型 T 方法集包含所有 receiver T 方法。
- 类型 *T 方法集包含所有 receiver T + *T 方法。
- 匿名嵌入 S,T 方法集包含所有 receiver S 方法。
- 匿名嵌入 *S,T 方法集包含所有 receiver S + *S 方法。
- 匿名嵌入 S 或 *S,*T 方法集包含所有 receiver S + *S 方法。
- 可利用反射(reflect)测试这些规则。
type S struct{}
type T struct {
S // 匿名嵌入字段
}
func (S) sVal() {}
func (*S) sPtr() {}
func (T) tVal() {}
func (*T) tPtr() {}
func methodSet(a interface{}) { // 显示方法集里所有方法名字
t := reflect.TypeOf(a)
for i, n := 0, t.NumMethod(); i < n; i++ {
m := t.Method(i)
fmt.Println(m.Name, m.Type)
}
}
func main() {
var t T
methodSet(t) // 显示 T 方法集
println("----------")
methodSet(&t) // 显示 *T 方法集
}
输出:
sVal func(main.T)
tVal func(main.T)
----------------------
sPtr func(*main.T)
sVal func(*main.T)
tPtr func(*main.T)
tVal func(*main.T)
输出结果符合预期,但我们也注意到某些方法的 receiver 类型发生了改变。真实情况是,这些都是由编译器按方法集所需自动生成的额外包装方法。
方法集仅影响接口实现和方法表达式转换,与通过实例或实例指针调用方法无关。实例 并不使用方法集,而是直接调用(或通过隐式字段名)。 很显然,匿名字段就是为方法集准备的。
组合没有父子依赖,不会破坏封装。且整体和局部松耦合,可任意增加来实现扩展。各单元持 有单一职责,互无关联,实现和维护更加简单。
尽管接口也是多态的一种实现形式,但我认为应该和基于继承体系的多态分离开来。
表达式 #
方法和函数一样,除直接调用外,还可赋值给变量,或作为参数传递。依照具体引用方 式的不同,可分为 expression 和 value 两种状态。
Method Expression #
通过类型引用的 method expression 会被还原为普通函数样式,receiver 是第一参数,调 用时须显式传参。至于类型,可以是 T 或 *T,只要目标方法存在于该类型方法集中即可。
type N int
func (n N) test() {
fmt.Printf("test.n: %p, %d\n", &n, n)
}
func main() {
var n N = 25
fmt.Printf("main.n: %p, %d\n", &n, n)
f1 := N.test // func(n N)
f1(n)
f2 := (*N).test // func(n *N)
f2(&n) // 按方法集中的签名传递正确类型的参数
}
输出:
main.n: 0xc82000a140, 25
test.n: 0xc82000a158, 25
test.n: 0xc82000a168, 25
*尽管 N 方法集包装的 test 方法 receiver 类型不同,但编译器会保证按原定义类型拷贝传值。
当然,也可直接以表达式方式调用。
func main() {
var n N = 25
N.test(n)
(*N).test(&n) // 注意: *N 须使用括号,以免语法解析错误
}
Method Value #
基于实例或指针引用的 method value,参数签名不会改变,依旧按正常方式调用。
但当 method value 被赋值给变量或作为参数传递时,会立即计算并复制该方法执行所需 的 receiver 对象,与其绑定,以便在稍后执行时,能隐式传入 receiver 参数。
type N int
func (n N) test() {
fmt.Printf("test.n: %p, %v\n", &n, n)
}
func main() {
var n N = 100
p := &n
n++
f1 := n.test // 因为 test 方法的 receiver 是 N 类型,
// 所以复制 n,等于 101
n++
f2 := p.test // 复制 *p,等于 102
n++
fmt.Printf("main.n: %p, %v\n", p, n)
f1()
f2()
}
输出:
main.n: 0xc820076028, 103
test.n: 0xc820076060, 101
test.n: 0xc820076070, 102
编译器会为 method value 生成一个包装函数,实现间接调用。至于 receiver 复制,和闭包的实 现方法基本相同,打包成 funcval,经由 DX 寄存器传递。
当 method value 作为参数时,会复制含 receiver 在内的整个 method value。
func call(m func()) {
m()
}
func main() {
var n N = 100
p := &n
fmt.Printf("main.n: %p, %v\n", p, n)
n++
call(n.test)
n++
call(p.test)
}
输出:
main.n: 0xc82000a288, 100
test.n: 0xc82000a2c0, 101
test.n: 0xc82000a2d0, 102
当然,如果目标方法的 receiver 是指针类型,那么被复制的仅是指针。
type N int
func (n *N) test() {
fmt.Printf("test.n: %p, %v\n", n, *n)
}
func main() {
var n N = 100
p := &n
n++
f1 := n.test // 因为 test 方法的 receiver 是 *N 类型,
// 所以复制 &n
n++
f2 := p.test // 复制 p 指针
n++
fmt.Printf("main.n: %p, %v\n", p, n)
f1() // 延迟调用,n == 103
f2()
}
输出:
main.n: 0xc82000a298, 103
test.n: 0xc82000a298, 103
test.n: 0xc82000a298, 103
只要 receiver 参数类型正确,使用 nil 同样可以执行。
type N int
func (N) value() {}
func (*N) pointer() {}
func main() {
var p *N
p.pointer() // method value
(*N)(nil).pointer() // method value
(*N).pointer(nil) // method expression
// p.value() // 错误: invalid memory address or nil pointer dereference
}
第七章 接口 #
定义 #
接口代表一种调用契约,是多个方法声明的集合。
在某些动态语言里,接口(interface)也被称作协议(protocol)。准备交互的双方,共 同遵守事先约定的规则,使得在无须知道对方身份的情况下进行协作。接口要实现的是 做什么,而不关心怎么做,谁来做。
接口解除了类型依赖,有助于减少用户可视方法,屏蔽内部结构和实现细节。接口最常见 的使用场景,是对包外提供访问,或预留扩展空间。
Go 接口实现机制很简洁,**只要目标类型方法集内包含接口声明的全部方法,就被视为 实现了该接口,无须做显示声明。**当然,目标类型可实现多个接口。
从内部实现来看,接口自身也是一种结构类型,只是编译器会对其做出很多限制。
type iface struct {
tab *itab
data unsafe.Pointer
}
- 不能有字段
- 不能定义自己的方法
- 只能声明方法,不能实现
- 可嵌入其他接口类型
接口通常以 er 作为名称后缀,方法名是声明组成部分,但参数名可不同或省略。
type tester interface {
test()
string() string
}
type data struct{}
func (*data) test() {}
func (data) string() string { return "" }
func main() {
var d data
// var t tester = d // 错误: data does not implement tester
// (test method has pointer receiver)
var t tester = &d
t.test()
println(t.string())
}
编译器根据方法集来判断是否实现了接口,显然在上例中只有 *data 才复合 tester 的要求。
如果接口没有任何方法声明,那么就是一个空接口(interface{}),它的用途类似面向对象里的根类型 Object,可被赋值为任何类型的对象。
接口变量默认值是 nil。如果实现接口的类型支持,可做相等运算。
func main() {
var t1, t2 interface{}
println(t1 == nil, t1 == t2)
t1, t2 = 100, 100
println(t1 == t2)
t1, t2 = map[string]int{}, map[string]int{}
println(t1 == t2)
}
输出:
true true
true
panic: runtime error: comparing uncomparable type map[string]int
可以像匿名字段那样,嵌入其他接口。目标类型方法集中必须拥有包含嵌入接口方法在 内的全部方法才算实现了该接口。
嵌入其他接口类型,相当于将其声明的方法集导入。这就要求不能有同名方法,因为不支持重 载。还有,不能嵌入自身或循环嵌入,那会导致递归错误。
type stringer interface {
string() string
}
type tester interface {
stringer // 嵌入其他接口
test()
}
type data struct{}
func (*data) test() {}
func (data) string() string {
return ""
}
func main() {
var d data
var t tester = &d
t.test()
println(t.string())
}
超集接口变量可隐式转换为子集,反过来不行。
func pp(a stringer) {
println(a.string())
}
func main() {
var d data
var t tester = &d
pp(t) // 隐式转换为子集接口
var s stringer = t // 超级转换为子集
println(s.string())
// var t2 tester = s // 错误: stringer does not implement tester
// (missing test method)
}
支持匿名接口类型,可直接用于变量定义,或作为结构字段类型。
type data struct{}
func (data) string() string {
return ""
}
type node struct {
data interface { // 匿名接口类型
string() string
}
}
func main() {
var t interface { // 定义匿名接口变量
string() string
} = data{}
n := node{
data: t,
}
println(n.data.string())
}
执行机制 #
接口使用一个名为 itab 的结构存储运行期所需的相关类型信息。
type iface struct {
tab *itab // 类型信息
data unsafe.Pointer // 实际对象指针
}
type itab struct {
inter *interfacetype // 接口类型
_type *_type // 实际对象类型
fun [1]uintptr // 实际对象方法地址
}
利用调试器,我们可查看这些结构存储的具体内容。
type Ner interface {
a()
b(int)
c(string) string
}
type N int
func (N) a() {}
func (*N) b(int) {}
func (*N) c(string) string { return "" }
func main() {
var n N
var t Ner = &n
t.a()
}
输出:
$ go build -gcflags "-N -l"
$ gdb test
...
(gdb) info locals # 设置断点,运行,查看局部变量信息
&n = 0xc82000a130
t = {
tab = 0x12f028,
data = 0xc82000a130
}
(gdb) p *t.tab.inter.typ._string # 接口类型名称
$17 = 0x737f0 "main.Ner"
(gdb) p *t.tab._type._string # 实际对象类型
$20 = 0x707a0 "*main.N"
(gdb) p t.tab.inter.mhdr # 接口类型方法集
$27 = {
array = 0x60158 <type.*+72888>,
len = 3,
cap = 3
}
(gdb) p *t.tab.inter.mhdr.array[0].name # 接口方法名称
$30 = 0x70a48 "a"
(gdb) p *t.tab.inter.mhdr.array[1].name
$31 = 0x70b08 "b"
(gdb) p *t.tab.inter.mhdr.array[2].name
$32 = 0x70ba0 "c"
(gdb) info symbol t.tab.fun[0] # 实际对象方法地址
main.(*N).a in section .text
(gdb) info symbol t.tab.fun[1]
main.(*N).b in section .text
(gdb) info symbol t.tab.fun[2]
main.(*N).c in section .text
很显然,相关类型信息里保存了接口和实际对象的元数据。同时,itab 还用 fun 数组 (不定长结构)保存了实际方法地址,从而实现在运行期对目标方法的动态调用。
除此之外,接口还有一个重要特征:将对象赋值给接口变量时,会复制该对象。
type data struct {
x int
}
func main() {
d := data{100}
var t interface{} = d
println(t.(data).x)
}
输出:
$ go build -gcflags "-N -l"
$ gdb test
(gdb) info locals # 输出局部变量
d = {
x = 100
}
t = {
_type = 0x5ec00 <type.*+67296>,
data = 0xc820035f20 # 接口变量存储的对象地址
}
(gdb) p/x &d # 局部变量地址。显然和接口存储的不是同一对象
$1 = 0xc820035f10
我们甚至无法修改接口存储的复制品,因为它也是 unaddressable 的。
func main() {
d := data{100}
var t interface{} = d
p := &t.(data) // 错误: cannot take the address of t.(data)
t.(data).x = 200 // 错误: cannot assign to t.(data).x
}
即便将其复制出来,用本地变量修改后,依然无法对 iface.data 赋值。解决方法就是将 对象指针赋值给接口,那么接口内存储的就是指针的复制品。
func main() {
d := data{100
var t interface{} = &d
t.(*data).x = 200
println(t.(*data).x)
}
输出:
$ go build -gcflags "-N -l" && ./test
200
$ gdb test
(gdb) info locals # 显示局部变量
d = {
x = 100
}
t = {
_type = 0x50480 <type.*+8096>,
data = 0xc820035f10
}
(gdb) p/x &d # 显然和接口内 data 存储的地址一致
$1 = 0xc820035f10
只有当接口变量内部的两个指针(itab, data)都为 nil 时,接口才等于 nil。
func main() {
var a interface{} = nil
var b interface{} = (*int)(nil)
println(a == nil, b == nil)
}
输出:
true false
(gdb) info locals
b = {
_type = 0x500c0 <type.*+7616>, # 显然 b 包含了类型信息
data = 0x0
}
a = {
_type = 0x0,
data = 0x0
}
由此造成的错误并不罕见,尤其是在函数返回 error 时。
type TestError struct{}
func (*TestError) Error() string {
return "error"
}
func test(x int) (int, error) {
var err *TestError
if x < 0 {
err = new(TestError)
x = 0
} else {
x += 100
}
return x, err // 注意: 这个 err 是有类型的
}
func main() {
x, err := test(100)
if err != nil {
log.Fatalln("err != nil") // 此处被执行
}
println(x)
}
2020/01/01 19:48:27 err != nil
exit status 1
(gdb) info locals # 很显然 x 没问题,但 err 并不等于 nil
x = 200
err = {
tab = 0x2161e8, # tab != nil
data = 0x0
}
正确做法是明确返回 nil。
func test(x int) (int, error) {
if x < 0 {
return 0, new(TestError)
}
return x + 100, nil
}
类型转换 #
类型推断可将接口变量还原为原始类型,或用来判断是否实现了某个更具体的接口类型。
type data int
func (d data) String() string {
return fmt.Sprintf("data:%d", d)
}
func main() {
var d data = 15
var x interface{} = d
if n, ok := x.(fmt.Stringer); ok { // 转换为更具体的接口类型
fmt.Println(n)
}
if d2, ok := x.(data); ok { // 转换回原始类型
fmt.Println(d2)
}
e := x.(error) // 错误: main.data is not error
fmt.Println(e)
}
输出:
data:15
data:15
panic: interface conversion: main.data is not error: missing method Error
使用 ok-idiom 模式,即便转换失败也不会引发 panic。还可用 switch 语句在多种类型间 做出推断匹配,这样空接口就有更多发挥空间。
func main() {
var x interface{} = func(x int) string {
return fmt.Sprintf("d:%d", x)
}
switch v := x.(type) { // 局部变量 v 是类型转换后的结果
case nil:
println("nil")
case *int:
println(*v)
case func(int) string:
println(v(100))
case fmt.Stringer:
fmt.Println(v)
default:
println("unknown")
}
}
输出:
d:100
提示:type switch 不支持 fallthrought。
技巧 #
让编译器检查,确保类型实现了指定接口。
type x int
func init() { // 包初始化函数
var _ fmt.Stringer = x(0)
}
输出:
cannot use x(0) (type x) as type fmt.Stringer in assignment:
x does not implement fmt.Stringer (missing String method)
定义函数类型,让相同签名的函数自动实现某个接口。
type FuncString func() string
func (f FuncString) String() string {
return f()
}
func main() {
var t fmt.Stringer = FuncString(func() string { // 转换类型,使其实现 Stringer接口
return "hello, world!"
})
fmt.Println(t)
}
第八章 并发 #
含义 #
并发(concurrency)和并行(parallesim)的区别。
- 并发:逻辑上具备同时处理多个任务的能力。
- 并行:物理上在同一时刻执行多个并发任务。
我们通常会说程序是并发设计的,也就是说它允许多个任务同时执行,但实际上并不一 定真在同一时刻发生。在单核处理器上,它们能以间隔方式切换执行。而并行则依赖多 核处理器等物理设备,让多个任务真正在同一时刻执行,它代表了当前程序运行状态。 简单点说,并行是并发设计的理想执行模式。
多线程或多进程是并行的基本条件,但单线程也可用协程(coroutine)做到并发。尽管 协程在单个线程上通过主动切换来实现多任务并发,但它也有自己的优势。除了将因阻 塞而浪费的时间找回来外,还免去了线程切换开销,有着不错的执行效率。协程上运行 的多个任务本质上是依旧串行的,加上可控自主调度,所以并不需要做同步处理。
即便采用多线程也未必就能并行。Python 就因 GIL 限制,默认只能并发而不能并行,所以很多 时候转而使用“多进程 + 协程”架构。
很难说哪种方式更好一些,它们有各自适用的场景。通常情况下,用多进程来实现分布式和负载平衡,减轻单进程垃圾回收压力;用多线程(LWP)抢夺更多的处理器资源; 用协程来提高处理器时间片利用率。
简单将 goroutine 归纳为协程并不合适。运行时会创建多个线程来执行并发任务,且任务单元可被调度到其他线程并行执行。这更像是多线程和协程的综合体,能最大限度提升执行效率,发挥多核处理能力。
只须在函数调用前添加 go 关键字即可创建并发任务。
go println("hello, world!")
go func(s string) {
println(s)
}("hello, world!")
注意是函数调用,所以必须提供相应的参数。
关键字 go 并非执行并发操作,而是创建一个并发任务单元。新建任务被放置在系统队 列中,等待调度器安排合适系统线程去获取执行权。当前流程不会阻塞,不会等待该任 务启动,且运行时也不保证并发任务的执行次序。
每个任务单元除保存函数指针、调用参数外,还会分配执行所需的栈内存空间。相比系 统 默认 MB 级别的线程栈,goroutine 自定义栈初始仅须 2 KB,所以才能创建成千上万 的并发任务。自定义栈采取按需分配策略,在需要时进行扩容,最大能到 GB 规模。
与 defer 一样,goroutine 也会因“延迟执行”而立即计算并复制执行参数。
var c int
func counter() int {
c++
return c
}
func main() {
a := 100
go func(x, y int) {
time.Sleep(time.Second) // 让 goroutine 在 main 逻辑之后执行
println("go:", x, y)
}(a, counter()) // 立即计算并复制参数
a += 100
println("main:", a, counter())
time.Sleep(time.Second * 3) // 等待 goroutine 结束
}
输出:
main: 200 2
go: 100 1
Wait #
进程退出时不会等待并发任务结束,可用通道(channel)阻塞,然后发出退出信号。
func main() {
exit := make(chan struct{}) // 创建通道。因为仅是通知,数据并没有实际意义
go func() {
time.Sleep(time.Second)
println("goroutine done.")
close(exit) // 关闭通道,发出信号
}()
println("main ...")
<-exit // 如通道关闭,立即解除阻塞
println("main exit.")
}
输出:
main ...
goroutine done.
main exit.
除关闭通道外,写入数据也可解除阻塞。channel 的更多信息,后面再做详述。
如要等待多个任务结束,推荐使用 sync.WaitGroup。通过设定计数器,让每个 goroutine 在退出前递减,直至归零时解除阻塞。
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1) // 累加计数
go func(id int) {
defer wg.Done() // 递减计数
time.Sleep(time.Second)
println("goroutine", id, "done.")
}(i)
}
println("main ...")
wg.Wait() // 阻塞,直到计数归零
println("main exit.")
}
输出:
main ...
goroutine 9 done.
goroutine 4 done.
goroutine 2 done.
goroutine 6 done.
goroutine 8 done.
goroutine 3 done.
goroutine 5 done.
goroutine 1 done.
goroutine 0 done.
goroutine 7 done.
main exit.
尽管 WaitGroup.Add 实现了原子操作,但建议在 goroutine 外累加计数器,以免 Add 尚 未执行,Wait 已经退出。
func main() {
var wg sync.WaitGroup
go func() {
wg.Add(1) // 来不及设置
println("hi!")
}()
wg.Wait()
println("exit.")
}
可在多处使用 Wait 阻塞,它们都能接收到通知。
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
wg.Wait() // 等待归零,解除阻塞
println("wait exit.")
}()
go func() {
time.Sleep(time.Second)
println("done.")
wg.Done() // 递减计数
}()
wg.Wait() // 等待归零,解除阻塞
println("main exit.")
}
输出:
done.
wait exit.
main exit.
GOMAXPROCS #
运行时可能会创建很多线程,但任何时候仅有限的几个线程参与并发任务执行。该数量 默认与处理器核数相等,可用 runtime.GOMAXPROCS 函数(或环境变量)修改。
如参数小于 1,GOMAXPROCS 仅返回当前设置值,不做任何调整。
// 测试目标函数
func count() {
x := 0
for i := 0; i < math.MaxUint32; i++ {
x += i
}
println(x)
}
// 循环执行
func test(n int) {
for i := 0; i < n; i++ {
count()
}
}
// 并发执行
func test2(n int) {
var wg sync.WaitGroup
wg.Add(n)
for i := 0; i < n; i++ {
go func() {
count()
wg.Done()
}()
}
wg.Wait()
}
func main() {
n := runtime.GOMAXPROCS(0)
test(n)
// test2(n)
}
$ time ./test
9223372030412324865
9223372030412324865
9223372030412324865
9223372030412324865
real 0m8.395s
user 0m8.281s
sys 0m0.056s
$ time ./test2
9223372030412324865
9223372030412324865
9223372030412324865
9223372030412324865
real 0m3.907s // 程序实际执行时间
user 0m14.438s // 多核执行时间累加
sys 0m0.041s
Local Storage #
与线程不同,goroutine 任务无法设置优先级,无法获取编号,没有局部存储(TLS), 甚至连返回值都会被抛弃。但除优先级外,其他功能都很容易实现。
func main() {
var wg sync.WaitGroup
var gs [5]struct { // 用于实现类似 TLS 功能
id int // 编号
result int // 返回值
}
for i := 0; i < len(gs); i++ {
wg.Add(1)
go func(id int) { // 使用参数避免闭包延迟求值
defer wg.Done()
gs[id].id = id
gs[id].result = (id + 1) * 100
}(i)
}
wg.Wait()
fmt.Printf("%+v\n", gs)
}
{id:0 result:100} {id:1 result:200} {id:2 result:300} {id:3 result:400} {id:4 result:500}
如使用 map 作为局部存储容器,建议做同步处理,因为运行时会对其做并发读写检查。
Gosched #
暂停,释放线程去执行其他任务。当前任务被放回队列,等待下次调度时恢复执行。
func main() {
runtime.GOMAXPROCS(1)
exit := make(chan struct{})
go func() { // 任务 a
defer close(exit)
go func() { // 任务 b。放在此处,是为了确保 a 优先执行
println("b")
}()
for i := 0; i < 4; i++ {
println("a:", i)
if i == 1 { // 让出当前线程,调度执行 b
runtime.Gosched()
}
}
}()
<-exit
}
a: 0
a: 1
b
a: 2
a: 3
该函数很少被使用,因为运行时会主动向长时间运行(10 ms)的任务发出抢占调度。 只是当前版本实现的算法稍显粗糙,不能保证调度总能成功,所以主动切换还有适用场 合。
Goexit #
Goexit 立即终止当前任务,运行时确保所有已注册延迟调用被执行。该函数不会影响其 他并发任务,不会引发 panic,自然也就无法捕获。
func main() {
exit := make(chan struct{})
go func() {
defer close(exit) // 执行
defer println("a") // 执行
func() {
defer func() {
println("b", recover() == nil) // 执行,recover 返回 nil
}()
func() { // 在多层调用中执行 Goexit
println("c")
runtime.Goexit() // 立即终止整个调用堆栈
println("c done.") // 不会执行
}()
println("b done.") // 不会执行
}()
println("a done.") // 不会执行
}()
<-exit
println("main exit.")
}
c
b true
a
main exit.
如果在 main.main 里调用 Goexit,它会等待其他任务结束,然后让进程直接崩溃。
func main() {
for i := 0; i < 2; i++ {
go func(x int) {
for n := 0; n < 2; n++ {
fmt.Printf("%c: %d\n", 'a'+x, n)
time.Sleep(time.Millisecond)
}
}(i)
}
runtime.Goexit() // 等待所有任务结束
println("main exit.")
}
b: 0
a: 0
b: 1
a: 1
fatal error: no goroutines (main called runtime.Goexit) - deadlock!
无论身处哪一层,Goexit 都能立即终止整个调用堆栈,这与 return 仅退出当前函数不同。
标准库函数 os.Exit 可终止进程,但不会执行延迟调用。
通道 #
相比 Erlang,Go 并未实现严格的并发安全。
允许全局变量、指针、引用类型这些非安全内存共享操作,就需要开发人员自行维护数 据一致和完整性。Go 鼓励使用 CSP 通道,以通信来代替内存共享,实现并发安全。
通过消息来避免竞态的模型除了 CSP,还有 Actor。但两者有较大区别。
作为 CSP 核心,通道(channel)是显式的,要求操作双方必须知道数据类型和具体通 道,并不关心另一端操作者身份和数量。可如果另一端未准备妥当,或消息未能及时处 理时,会阻塞当前端。
相比起来,Actor 是透明的,它不在乎数据类型及通道,只要知道接收者信箱即可。默 认就是异步方式,发送方对消息是否被接收和处理并不关心。
从底层实现上来说,通道只是一个队列。同步模式下,发送和接收双方配对,然后直接 复制数据给对方。如配对失败,则置入等待队列,直到另一方出现后才被唤醒。异步模 式抢夺的则是数据缓冲槽。发送方要求有空槽可供写入,而接收方则要求有缓冲数据可 读。需求不符时,同样加入等待队列,直到有另一方写入数据或腾出空槽后被唤醒。
除传递消息(数据)外,通道还常被用作事件通知。
func main() {
done := make(chan struct{}) // 结束事件
c := make(chan string) // 数据传输通道
go func() {
s := <-c // 接收消息
println(s)
close(done) // 关闭通道,作为结束通知
}()
c <- "hi!" // 发送消息
<-done // 阻塞,直到有数据或管道关闭
}
hi!
同步模式必须有配对操作的 goroutine 出现,否则会一直阻塞。而异步模式在缓冲区未 满或数据未读完前,不会阻塞。
func main() {
c := make(chan int, 3) // 创建带 3 个缓冲槽的异步通道
c <- 1 // 缓冲区未满,不会阻塞
c <- 2
println(<-c) // 缓冲区尚有数据,不会阻塞
println(<-c)
}
1
2
多数时候,异步通道有助于提升性能,减少排队阻塞。
缓冲区大小仅是内部属性,不属于类型组成部分。另外通道变量本身就是指针,可用相 等操作符判断是否为同一对象或 nil。
func main() {
var a, b chan int = make(chan int, 3), make(chan int)
var c chan bool
println(a == b)
println(c == nil)
fmt.Printf("%p, %d\n", a, unsafe.Sizeof(a))
}
false
true
0xc820076000, 8
虽然可传递指针来避免数据复制,但须额外注意数据并发安全。
内置函数 cap 和 len 返回缓冲区大小和当前已缓冲数量;而对于同步通道则都返回 0, 据此可判断通道是同步还是异步。
func main() {
a, b := make(chan int), make(chan int, 3)
b <- 1
b <- 2
println("a:", len(a), cap(a))
println("b:", len(b), cap(b))
}
a: 0 0
b: 2 3
收发 #
除使用简单的发送和接收操作符外,还可用 ok-idom 或 range 模式处理数据。
func main() {
done := make(chan struct{})
c := make(chan int)
go func() {
defer close(done) // 确保发出结束通知
for {
x, ok := <-c
if !ok { // 据此判断通道是否被关闭
return
}
println(x)
}
}()
c <- 1
c <- 2
c <- 3
close(c)
<-done
}
1
2
3
对于循环接收数据,range 模式更简洁一些。
func main() {
done := make(chan struct{})
c := make(chan int)
go func() {
defer close(done)
for x := range c { // 循环获取消息,直到通道被关闭
println(x)
}
}()
c <- 1
c <- 2
c <- 3
close(c)
<-done
}
及时用 close 函数关闭通道引发结束通知,否则可能会导致死锁。
fatal error: all goroutines are asleep - deadlock!
通知可以是群体性的。也未必就是通知结束,可以是任何需要表达的事件。
func main() {
var wg sync.WaitGroup
ready := make(chan struct{})
for i := 0; i < 3; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
println(id, ": ready.") // 运动员准备就绪
<-ready // 等待发令
println(id, ": running...")
}(i)
}
time.Sleep(time.Second)
println("Ready? Go!")
close(ready) // 砰!
wg.Wait()
}
0 : ready.
2 : ready.
1 : ready.
Ready? Go!
1 : running...
0 : running...
2 : running...
一次性事件用 close 效率更好,没有多余开销。连续或多样性事件,可传递不同数据标志实现。
还可使用 sync.Cond 实现单播或广播事件。
对于 closed 或 nil 通道,发送和接收操作都有相应规则:
- 向已关闭通道发送数据,引发 panic。
- 从已关闭接收数据,返回已缓冲数据或零值。
- 无论收发,nil 通道都会阻塞。
func main() {
c := make(chan int, 3)
c <- 10
c <- 20
close(c)
for i := 0; i < cap(c)+1; i++ {
x, ok := <-c
println(i, ":", ok, x)
}
}
0 : true 10
1 : true 20
2 : false 0
3 : false 0
重复关闭,或关闭 nil 通道都会引发 panic 错误。
panic: close of closed channel
panic: close of nil channel
单向 #
通道默认是双向的,并不区分发送和接收端。但某些时候,我们可限制收发操作的方向 来获得更严谨的操作逻辑。
尽管可用 make 创建单向通道,但那没有任何意义。通常使用类型转换来获取单向通 道,并分别赋予操作双方。
func main() {
var wg sync.WaitGroup
wg.Add(2)
c := make(chan int)
var send chan<- int = c
var recv <-chan int = c
go func() {
defer wg.Done()
for x := range recv {
println(x)
}
}()
go func() {
defer wg.Done()
defer close(c)
for i := 0; i < 3; i++ {
send <- i
}
}()
wg.Wait()
}
不能在单向通道上做逆向操作。
func main() {
c := make(chan int, 2)
var send chan<- int = c
var recv <-chan int = c
<-send // 无效操作: <-send (receive from send-only type chan<- int)
recv <- 1 // 无效操作: recv <- 1 (send to receive-only type <-chan int)
}
同样,close 不能用于接收端。
func main() {
c := make(chan int, 2)
var recv <-chan int = c
close(recv) // 无效操作: close(recv) (cannot close receive-only channel)
}
无法将单向通道重新转换回去。
func main() {
var a, b chan int
a = make(chan int, 2)
var recv <-chan int = a
var send chan<- int = a
b = (chan int)(recv) // 错误: cannot convert recv (type <-chan int) to type chan int
b = (chan int)(send) // 错误: cannot convert send (type chan<- int) to type chan int
}
选择 #
如要同时处理多个通道,可选用 select 语句。它会随机选择一个可用通道做收发操作。
func main() {
var wg sync.WaitGroup
wg.Add(2)
a, b := make(chan int), make(chan int)
go func() { // 接收端
defer wg.Done()
for {
var (
name string
x int
ok bool
)
select { // 随机选择可用 channel 接收数据
case x, ok = <-a:
name = "a"
case x, ok = <-b:
name = "b"
}
if !ok { // 如果任一通道关闭,则终止接收
return
}
println(name, x) // 输出接收的数据信息
}
}()
go func() { // 发送端
defer wg.Done()
defer close(a)
defer close(b)
for i := 0; i < 10; i++ {
select { // 随机选择发送 channel
case a <- i:
case b <- i * 10:
}
}
}()
wg.Wait()
}
b 0
a 1
a 2
b 30
a 4
a 5
b 60
b 70
a 8
b 90
如要等全部通道消息处理结束(closed),可将已完成通道设置为 nil。这样它就会被阻 塞,不再被 select 选中。
func main() {
var wg sync.WaitGroup
wg.Add(3)
a, b := make(chan int), make(chan int)
go func() { // 接收端
defer wg.Done()
for {
select {
case x, ok := <-a:
if !ok { // 如果通道关闭,则设置为 nil,阻塞
a = nil
break
}
println("a", x)
case x, ok := <-b:
if !ok {
b = nil
break
}
println("b", x)
}
if a == nil && b == nil { // 全部结束,退出循环
return
}
}
}()
go func() { // 发送端 a
defer wg.Done()
defer close(a)
for i := 0; i < 3; i++ {
a <- i
}
}()
go func() { // 发送端 b
defer wg.Done()
defer close(b)
for i := 0; i < 5; i++ {
b <- i * 10
}
}()
wg.Wait()
}
b 0
b 10
b 20
b 30
b 40
a 0
a 1
a 2
即便是同一通道,也会随机选择 case 执行。
func main() {
var wg sync.WaitGroup
wg.Add(2)
c := make(chan int)
go func() { // 接收端
defer wg.Done()
for {
var v int
var ok bool
select { // 随机选择 case
case v, ok = <-c:
println("a1:", v)
case v, ok = <-c:
println("a2:", v)
}
if !ok {
return
}
}
}()
go func() { // 发送端
defer wg.Done()
defer close(c)
for i := 0; i < 10; i++ {
select { // 随机选择 case
case c <- i:
case c <- i * 10:
}
}
}()
wg.Wait()
}
a1: 0
a2: 10
a2: 2
a1: 30
a1: 40
a2: 50
a2: 60
a2: 7
a1: 8
a1: 90
a1: 0
当所有通道都不可用时,select 会执行 default 语句。如此可避开 select 阻塞,但须注意 处理外层循环,以免陷入空耗。
func main() {
done := make(chan struct{})
c := make(chan int)
go func() {
defer close(done)
for {
select {
case x, ok := <-c:
if !ok {
return
}
fmt.Println("data:", x)
default: // 避免 select 阻塞
}
fmt.Println(time.Now())
time.Sleep(time.Second)
}
}()
time.Sleep(time.Second * 5)
c <- 100
close(c)
<-done
}
2016-04-01 17:22:07
2016-04-01 17:22:08
2016-04-01 17:22:09
2016-04-01 17:22:10
2016-04-01 17:22:11
data: 100
2016-04-01 17:22:12
也可用 default 处理一些默认逻辑。
func main() {
done := make(chan struct{})
data := []chan int{ // 数据缓冲区
make(chan int, 3),
}
go func() {
defer close(done)
for i := 0; i < 10; i++ {
select {
case data[len(data)-1] <- i: // 生产数据
default: // 当前通道已满,生成新的缓存通道
data = append(data, make(chan int, 3))
}
}
}()
<-done
for i := 0; i < len(data); i++ { // 显示所有数据
c := data[i]
close(c)
for x := range c {
println(x)
}
}
}
模式 #
通常使用工厂方法将 goroutine 和通道绑定
type receiver struct {
sync.WaitGroup
data chan int
}
func newReceiver() *receiver {
r := &receiver{
data: make(chan int),
}
r.Add(1)
go func() {
defer r.Done()
for x := range r.data { // 接收消息,直到通道被关闭
println("recv:", x)
}
}()
return r
}
func main() {
r := newReceiver()
r.data <- 1
r.data <- 2
close(r.data) // 关闭通道,发出结束通知
r.Wait() // 等待接收者处理结束
}
recv: 1
recv: 2
鉴于通道本身就是一个并发安全的队列,可用作 ID generator、Pool 等用途。
type pool chan []byte
func newPool(cap int) pool {
return make(chan []byte, cap)
}
func (p pool) get() []byte {
var v []byte
select {
case v = <-p: // 返回
default: // 返回失败,新建
v = make([]byte, 10)
}
return v
}
func (p pool) put(b []byte) {
select {
case p <- b: // 放回
default: // 放回失败,放弃
}
}
用通道实现信号量(semaphore)。
func main() {
runtime.GOMAXPROCS(4)
var wg sync.WaitGroup
sem := make(chan struct{}, 2) // 最多允许 2 个并发同时执行
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
sem <- struct{}{} // acquire: 获取信号
defer func() { <-sem }() // release: 释放信号
time.Sleep(time.Second * 2)
fmt.Println(id, time.Now())
}(i)
}
wg.Wait()
}
4 2016-02-19 18:24:09
0 2016-02-19 18:24:09
2 2016-02-19 18:24:11
1 2016-02-19 18:24:11
3 2016-02-19 18:24:13
标准库 time 提供了 timeout 和 tick channel 实现。
func main() {
go func() {
for {
select {
case <-time.After(time.Second * 5):
fmt.Println("timeout ...")
os.Exit(0)
}
}
}()
go func() {
tick := time.Tick(time.Second)
for {
select {
case <-tick:
fmt.Println(time.Now())
}
}
}()
<-(chan struct{})(nil) // 直接用 nil channel 阻塞进程
}
捕获 INT、TERM 信号,顺便实现一个简易的 atexit 函数。
var exits = &struct {
sync.RWMutex
funcs []func()
signals chan os.Signal
}{}
func atexit(f func()) {
exits.Lock()
defer exits.Unlock()
exits.funcs = append(exits.funcs, f)
}
func waitExit() {
if exits.signals == nil {
exits.signals = make(chan os.Signal)
signal.Notify(exits.signals, syscall.SIGINT, syscall.SIGTERM)
}
exits.RLock()
for _, f := range exits.funcs {
defer f() // 即便某些函数 panic,延迟调用也能确保后续函数执行
} // 延迟调用按 FILO 顺序执行
exits.RUnlock()
<-exits.signals
}
func main() {
atexit(func() { println("exit1 ...") })
atexit(func() { println("exit2 ...") })
waitExit()
}
性能 #
将发往通道的数据打包,减少传输次数,可有效提升性能。从实现上来说,通道队列依 旧使用锁同步机制,单次获取更多数据(批处理),可改善因频繁加锁造成的性能问 题。
虽然单次消耗更多内存,但性能提升非常明显。如将数组改成切片会造成更多内存分配次数。
资源泄漏 #
通道可能会引发 goroutine leak,确切地说,是指 goroutine 处于发送或接收阻塞状态, 但一直未被唤醒。垃圾回收器并不收集此类资源,导致它们会在等待队列里长久休眠, 形成资源泄漏。
同步 #
通道并非用来取代锁的,它们有各自不同的使用场景。通道倾向于解决逻辑层次的并发 处理架构,而锁则用来保护局部范围内的数据安全。
标准库 sync 提供了互斥和读写锁,另有原子操作等,可基本满足日常开发需要。 Mutex、RWMutex 的使用并不复杂,只有几个地方需要注意。
将 Mutex 作为匿名字段时,相关方法必须实现为 pointer-receiver,否则会因复制导致锁 机制失效。
type data struct {
sync.Mutex
}
func (d data) test(s string) {
d.Lock()
defer d.Unlock()
for i := 0; i < 5; i++ {
println(s, i)
time.Sleep(time.Second)
}
}
func main() {
var wg sync.WaitGroup
wg.Add(2)
var d data
go func() {
defer wg.Done()
d.test("read")
}()
go func() {
defer wg.Done()
d.test("write")
}()
wg.Wait()
}
write 0
read 0
read 1
write 1
write 2
read 2
read 3
write 3
write 4
read 4
锁失效,将 receiver 类型改为 *data 后正常。
也可用嵌入 *Mutex 来避免复制问题,但那需要专门初始化。
应将 Mutex 锁粒度控制在最小范围内,及早释放。
// 错误用法
func doSomething() {
m.Lock()
url := cache["key"]
http.Get(url) // 该操作并不需要锁保护
m.Unlock()
}
// 正确用法
func doSomething() {
m.Lock()
url := cache["key"]
m.Unlock() // 如使用 defer,则依旧将 Get 保护在内
http.Get(url)
}
Mutex 不支持递归锁,即便在同一 goroutine 下也会导致死锁。
func main() {
var m sync.Mutex
m.Lock()
{
m.Lock()
m.Unlock()
}
m.Unlock()
}
fatal error: all goroutines are asleep - deadlock!
在设计并发安全类型时,千万注意此类问题。
type cache struct {
sync.Mutex
data []int
}
func (c *cache) count() int {
c.Lock()
n := len(c.data)
c.Unlock()
return n
}
func (c *cache) get() int {
c.Lock()
defer c.Unlock()
var d int
if n := c.count(); n > 0 { // count 重复锁定,导致死锁
d = c.data[0]
c.data = c.data[1:]
}
return d
}
func main() {
c := cache{
data: []int{1, 2, 3, 4},
}
println(c.get())
}
fatal error: all goroutines are asleep - deadlock!
相关建议:
- 对性能要求较高时,应避免使用 defer Unlock。
- 读写并发时,用 RWMutex 性能会更好一些。
- 对单个数据读写保护,可尝试用原子操作。
- 执行严格测试,尽可能打开数据竞争检查。