力扣刷题(一) #
力扣刷题 全部题目模块(1~100)
简单 #
山峰数组 #
符合下列属性的数组 arr 称为 山峰数组(山脉数组) :arr.length >= 3存在 i(0 < i < arr.length - 1)使得: arr[0] < arr[1] < … arr[i-1] < arr[i] arr[i] > arr[i+1] > … > arr[arr.length - 1] 给定由整数组成的山峰数组 arr ,返回任何满足 arr[0] < arr[1] < … arr[i - 1] < arr[i] > arr[i + 1] > … > arr[arr.length - 1] 的下标 i ,即山峰顶部。
示例 1:
输入:arr = [0,1,0]
输出:1
示例 2:
输入:arr = [1,3,5,4,2]
输出:2
func peakIndexInMountainArray(arr []int) int {
var i,j int
j=len(arr)-1
for i=0;i<j;i++{
if (arr[i]>arr[j]) {
j=j-1
i=i-1
}
}
return i
}从
执行用时:8 ms, 在所有 Go 提交中击败了88.24%的用户
内存消耗:4.5 MB, 在所有 Go 提交中击败了16.18%的用户
两数之和 #
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
func twoSum(nums []int, target int) []int {
var i,j int
//b:=[]int{} 这里定义的切片已经被赋值,切片是只读对象
b:=make([]int, 2) //var b []int
for i=0;i<len(nums)-1;i++{
for j=i+1;j<=len(nums)-1;j++{
if(nums[i]+nums[j]==target){
b[0]=i
b[1]=j
}
}
}
return b
}
执行用时:36 ms, 在所有 Go 提交中击败了9.31%的用户
内存消耗:3.7 MB, 在所有 Go 提交中击败了87.59%的用户
整数反转 #
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
示例 1:
输入:x = 123
输出:321
示例 2:
输入:x = -123
输出:-321
示例 3:
输入:x = 120
输出:21
func reverse(x int) int {
n:=0
for (x!=0){
n=n*10+x%10
x=x/10
}
if(n<(-2147483648))||(n>(2147483647)){
n=0
}
// max := int(^uint32((0)) >> 1)
// min := ^max
// if(n<min)||(n>max){
// n=0
// }
//if(n<(-2^31))||(n>(2^31-1)){ //go语言中^表示按位异或 不是次方 pow(2, 32)
// n=0
//}
return n
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了64.87%的用户
无符号整型uint,其最小值是0,其二进制表示的所有位都为0,
const UINT_MIN uint = 0
其最大值的二进制表示的所有位都为1,那么,
const UINT_MAX = ^uint(0)
有符号整型int,根据补码,其最大值二进制表示,首位0,其余1,那么,
const INT_MAX = int(^uint(0) >> 1)
根据补码,其最小值二进制表示,首位1,其余0,那么,
const INT_MIN = ^INT_MAX
回文数 #
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。
回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。例如,121 是回文,而 123 不是。
示例 1:
输入:x = 121
输出:true
示例 2:
输入:x = -121
输出:false
解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
func isPalindrome(x int) bool {
i:=0
a:=x
if x<0{
return false
}
for x!=0{
i=i*10+x%10
x=x/10
}
if i==a{
return true
}else {
return false
}
}
执行用时:20 ms, 在所有 Go 提交中击败了47.91%的用户
内存消耗:4.9 MB, 在所有 Go 提交中击败了91.25%的用户
罗马数字转整数 #
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。 X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。 C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。 给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
func romanToInt(s string) int {
var mm = []struct {
value string
b int
}{
{"M", 1000},
{"CM", 900},
{"D", 500},
{"CD", 400},
{"C",100},
{"XC", 90},
{"L",50},
{"XL", 40},
{"X", 10},
{"IX", 9},
{"V", 5},
{"IV",4},
{"I",1},
}
x:=0
var ss string
for j:=0;j<len(s);j++{
if j+1<len(s) {
ss = string(s[j]) + string(s[j+1]) //判断组合
}else {
ss="d" //遍历从上到下"MDCXCV" 防止XC 在V前面计算
}
println(ss)
for _,a:=range mm{
if ss==a.value{
x=x+a.b
j=j+1 //for循环后面还要再++ 所以+1
break
}
if j==len(s){
return x
}
if string(s[j])==a.value{
x=x+a.b
break
}
}
}
return x
}
执行用时:24 ms, 在所有 Go 提交中击败了15.05%的用户
内存消耗:3 MB, 在所有 Go 提交中击败了57.37%的用户
var symbolValues = map[byte]int{'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}
func romanToInt(s string) (ans int) {
n := len(s)
for i := range s {
value := symbolValues[s[i]]
if i < n-1 && value < symbolValues[s[i+1]] {
ans -= value
} else {
ans += value
}
}
return
}
最长公共前缀 #
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 “"。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
func longestCommonPrefix(strs []string) string {
x:=make([]rune,0,200)
if strs == nil {
return string(x)
} else { //不为空时
lens:=len(strs[0])
for i:=0;i<len(strs);i++{ //找出子串最小长度
if lens>len(strs[i]){
lens=len(strs[i])
}
}
i, j := 0, 0
for j<lens { //到最小长度停止
d := strs[i][j]
for i:=0;i < len(strs); {
if d == strs[i][j] {
i++
} else {
return string(x)
}
if i == len(strs) { //遍历到后面 加进去
x = append(x, rune(d))
}
}
j++
}
}
return string(x)
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.3 MB, 在所有 Go 提交中击败了89.99%的用户
有效的括号 #
给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。
示例 1:
输入:s = "()"
输出:true
type Stack struct { //定义栈
size int
top int
data []string
}
func isValid(s string) bool {
s1 := Stack{} //初始化栈
s1.size = len(s)
s1.top = -1
s1.data = make([]string, len(s))
for _, a := range s { //遍历s
var b string
if string(a) == ")" { //设置出栈条件
b = "("
}
if string(a) == "}" {
b = "{"
}
if string(a) == "]" {
b = "["
}
if s1.top > -1 && s1.data[s1.top] == b { //相等出栈
s1.top--
} else { //不等入栈
s1.top++
s1.data[s1.top] = string(a)
}
}
if s1.top == -1 { //判断栈空为true
return true
} else {
return false
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了17.24%的用户
合并两个有序链表 #
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
func mergeTwoLists(L1 *ListNode, L2 *ListNode) *ListNode {
L3 := &ListNode{-200, L1} //设置L3.Next=L1
head := L3 //头指针
for L1 != nil && L2 != nil {
if L1.Val >= L2.Val { // 指向小的
head.Next = L2
println(head.Val)
head = head.Next
L2 = L2.Next
} else {
head.Next = L1
println(head.Val)
head = head.Next
L1 = L1.Next
}
}
if L2 != nil { //那个不为空 指向它 添到后面
head.Next = L2
}
if L1 != nil {
head.Next = L1
}
return L3.Next
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了42.80%的用户
删除有序数组中的重复项 #
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
func removeDuplicates(nums []int) int {
var a, b int
if len(nums) == 0 { //排除一些特殊情况
return 0
}
if len(nums) == 1 {
return 1
} else {
a = nums[0]
j := 1
for i := 1; i < len(nums); i++ {
b = nums[i]
if a != b { //不相等的时候用b,去逐渐取代数组里面的值
nums[j] = b
a = nums[j]
j++
}
}
return j
}
}
执行用时:8 ms, 在所有 Go 提交中击败了84.52%的用户
内存消耗:4.3 MB, 在所有 Go 提交中击败了99.94%的用户
移除元素 #
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
func removeElement(nums []int, val int) int {
var b int
j := 0
for i := 0; i < len(nums); i++ {
b = nums[i]
if b != val {
nums[j] = b
j++
}
}
return j
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了58.62%的用户
实现strStr() #
实现 strStr() 函数。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
输入:haystack = "hello", needle = "ll"
输出:2
func strStr(haystack string, needle string) int {
n := len(needle)
falge := false
m := -1
if len(needle) == 0 { //排除特殊情况
return 0
}
for a, b := range haystack {
if b == rune(needle[0]) && falge == false { //相等开始遍历
m = a
falge = true
}
if a+n > len(haystack) { //防止数组越界和不必要的遍历
return -1
}
if falge == true {
for d, c := range needle {
if d == len(haystack) { //排除len(needle)>len(haystack)的情况
return -1
}
if c != rune(haystack[m]) { //遇到不一样的返回
break
}
m++
}
if m-a == n { //如果全部遍历完 一样的话 return 下标
return a
} else {
falge = false
}
}
}
return m
}
执行用时:380 ms, 在所有 Go 提交中击败了11.06%的用户
内存消耗:2.6 MB, 在所有 Go 提交中击败了65.18%的用户
搜索插入位置 #
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
func searchInsert(nums []int, target int) int {
i := 0
j := len(nums) - 1
c := -1
for t := (i + j) / 2; i <= j; t = (i + j) / 2 {//二分法查找
if nums[t] == target { //相等输出
c = t
break
}
if nums[t] < target { //缩小范围
i = t + 1
}
if nums[t] > target {
j = t - 1
}
}
if j < 0 { //排除最左端
c = 0
} else if i > len(nums)-1 { //排除最右端
c = len(nums)
} else if nums[i] > target && target > nums[j] { //中间端
c = i
}
return c
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:3 MB, 在所有 Go 提交中击败了28.29%的用户
最后一个单词的长度 #
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为5。
func lengthOfLastWord(s string) int {
n := 0 //记录长度
a := 0 //计数器
for _, m := range s { //遍历字符串
if m == 32 { //如果为空 a清0
a = 0
} else { //不为空 a++
a++
}
if a != 0 { //如果a不是空,则n跟着a增加
n = a
}
}
return n
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了89.55%的用户
最大子数组和 #
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
func maxSubArray(nums []int) int {
max := nums[0] //max 计数
for i := 1; i < len(nums); i++ {
if nums[i]+nums[i-1] > nums[i] {
nums[i] = nums[i] + nums[i-1] //更新i 记录最大值
}
if nums[i] > max { //更新最大值
max = nums[i]
}
}
return max
}
执行用时:72 ms, 在所有 Go 提交中击败了99.93%的用户
内存消耗:9.3 MB, 在所有 Go 提交中击败了37.27%的用户
回文链表 #
给定一个链表的 头节点 head **,**请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。

输入: head = [1,2,3,3,2,1]
输出: true
func reverselist(head *ListNode) (l *ListNode, r *ListNode) {
var p, q, m *ListNode //翻转函数,输入123,返回321 的头尾指针
p = head
q = head.Next
m = q.Next
if m == nil {
q.Next = p
p.Next = nil
return q, p
}
for q != nil {
q.Next = p
p = q
q = m
if m.Next != nil {
m = m.Next
} else {
q.Next = p
break
}
}
head.Next = nil
return q, head
}
func isPalindrome(head *ListNode) bool {
n := 1
head1 := head
head2 := head
for head1.Next != nil { //算出链表长度
n++
head1 = head1.Next
}
print(n)
for i := 0; i < n/2; i++ { //找到后面链表的开头
head2 = head2.Next
print(i)
}
if n > 1 && n%2 == 0 && n < 6 { //n=2,4 //排除前五个
if n == 2 {
if head.Val != head.Next.Val {
return false
}
}
if n == 4 {
if head.Next.Val != head2.Val {
return false
}
if head.Val != head2.Next.Val {
return false
}
}
}
if n > 1 && n%2 == 1 && n < 6 { //n=3,5
if n == 3 {
if head.Val != head.Next.Next.Val {
return false
}
}
if n == 5 {
head2 = head2.Next
if head.Next.Val != head2.Val {
return false
}
if head.Val != head2.Next.Val {
return false
}
}
}
if n > 5 && n%2 == 0 { //偶数 大于6的时候
head3, _ := reverselist(head2) //翻转后面链表,逐个对比
print(head3.Val)
for head3 != nil {
if head.Val == head3.Val {
head = head.Next
head3 = head3.Next
} else {
return false
}
}
}
if n>5&&n%2==1 { //奇数 大于6的时候
head2 = head2.Next
head3, _ := reverselist(head2)//翻转后面链表,逐个对比
for head3 != nil {
if head.Val == head3.Val {
head = head.Next
head3 = head3.Next
} else {
return false
}
}
}
return true
}
//这个太笨了 史上最lou代码
执行用时: 224 ms
内存消耗: 9.4 MB
func isPalindrome(head *ListNode) bool {
head1 := head
head2 := head
var p, q *ListNode
for head1 != nil && head1.Next != nil { //翻转前部分
head1 = head1.Next.Next
q = head2.Next
head2.Next = p
p = head2
head2 = q
}
if head1 != nil { //看他是不是奇数
head2 = head2.Next
}
for p != nil { //逐个对比
if p.Val != head2.Val {
return false
}
p = p.Next
head2 = head2.Next
}
return true
}
执行用时:128 ms, 在所有 Go 提交中击败了90.49%的用户
内存消耗:10.9 MB, 在所有 Go 提交中击败了21.61%的用户
func isPalindrome(head *ListNode) bool {//递归
var spalin func(*ListNode) bool
spalin = func(head1 *ListNode) bool {
if head1 != nil {
if spalin(head1.Next) == false {
return false
}
if head.Val != head1.Val {
return false
}
head = head.Next
}
return true
}
return spalin(head)
}
执行用时: 164 ms
内存消耗: 17.6 MB
加一 #
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
func plusOne(digits []int) []int {
m:=len(digits)
i:=m-1
for i>-1{
x:=digits[i]+1
if x==10{
digits[i]=0
i--
}else{
digits[i]=x
break
}
}
if i==-1{ //到这里说明都是9 多了一位 新建数组
array:=make([]int,m+1)
array[0]=1
return array
}
return digits
}
二进制求和 #
给你两个二进制字符串,返回它们的和(用二进制表示)。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
func addBinary(a string, b string) string { //到底还是转换成int型做的
ans := ""
carry := 0
lenA, lenB := len(a), len(b)
n := max(lenA, lenB)
for i := 0; i < n; i++ {
if i < lenA {
carry += int(a[lenA-i-1] - '0') //注意这个字符串转成int型的方式
}
if i < lenB {
carry += int(b[lenB-i-1] - '0')
}
ans = strconv.Itoa(carry%2) + ans //int转为string
carry /= 2
}
if carry > 0 {
ans = "1" + ans
}
return ans
}
func max(x, y int) int {
if x > y {
return x
}
return y
}
//我写的笨办法 人麻了
func addBinary(a string, b string) string {
m, n := len(a), len(b)
if m < n { //让a 最长 b 最短 记得交换m,n
a, b = b, a
m, n = n, m
}
s := "" //创建一个字符串
x := 0 //进位标记
for i := 0; i < n; i++ {
if a[m-1-i] == '1' && b[n-1-i] == '1' { //都为1的情况
if x == 0 { //考虑要不要进位 注意更改x的值
s = "0" + s
x = 1
} else {
s = "1" + s
x = 1
}
}
if a[m-1-i] == '0' && b[n-1-i] == '0' { //都为0的情况
if x == 0 { //考虑X的值
s = "0" + s
} else {
s = "1" + s
x = 0
}
}
if a[m-1-i] == '1' && b[n-1-i] == '0' { //其中一个为1
if x == 0 {
s = "1" + s
} else {
s = "0" + s
x = 1
}
}
if a[m-1-i] == '0' && b[n-1-i] == '1' { //这个跟上面的其实可以合起来
if x == 0 {
s = "1" + s
} else {
s = "0" + s
x = 1
}
}
}
if x == 0 { //搞完之后 看x是否还为1 是则要继续
s = a[:m-n] + s
} else {
a = a[:m-n] //将最长的缩短
m = len(a)
for i := m - 1; i > -1; i-- { //对最长的开始进位加1原理一样
if a[i] == '1' && x == 1 {
s = "0" + s
x = 1
continue //这里别让他继续下面的 否则出错
}
if a[i] == '1' && x == 0 {
s = a[:i] + "1" + s
break
}
if a[i] == '0' && x == 1 {
s = a[:i] + "1" + s
x = 0
break
}
if a[i] == '0' && x == 0 {
s = a[:i] + "0" + s
break
}
}
if x == 1 { //最后再确认一遍 x的值
s = "1" + s
}
}
return s
}
执行用时:4 ms, 在所有 Go 提交中击败了5.17%的用户
内存消耗:2.3 MB, 在所有 Go 提交中击败了74.64%的用户
X的平方根 #
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分,小数部分将被舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
func mySqrt(x int) int {
if x==1{
return 1
}
for i:=1;i<=(x/2);i++{ //暴力求解
if i*i<=x&&(i+1)*(i+1)>x{
return i
}
}
return 0
}
执行用时:48 ms, 在所有 Go 提交中击败了7.56%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了5.32%的用户
func mySqrt(x int) int { //二分发查找
l, r := 0, x
ans := -1
for l <= r {
mid := l + (r - l) / 2 //不加1会出现死循环
if mid * mid <= x {
ans = mid
l = mid + 1
} else {
r = mid - 1
}
}
return ans
}
执行用时:4 ms, 在所有 Go 提交中击败了43.73%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了99.83%的用户
爬楼梯 #
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1、 1 阶 + 1 阶
2、 2 阶
func climbStairs(n int) int {
switch n {
case 1: return 1
case 2: return 2
default: break
}
x,y:=1,2
c:=0
for i:=2;i<n;i++{
c=y
y=x+y
x=c
}
return y
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.8 MB, 在所有 Go 提交中击败了80.43%的用户
删除排序链表中的重复元素 #
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
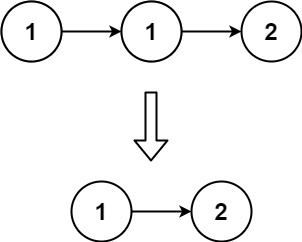
输入:head = [1,1,2]
输出:[1,2]
func deleteDuplicates(head *ListNode) *ListNode {
var pre *ListNode
pre = head
var next *ListNode
if pre == nil { //排除为空情况
return head
}
for pre.Next != nil {
next = pre.Next
if pre.Val == next.Val {
pre.Next = next.Next
} else {
pre = pre.Next
}
}
return head
}
执行用时:4 ms, 在所有 Go 提交中击败了77.07%的用户
内存消耗:3 MB, 在所有 Go 提交中击败了73.48%的用户
二叉树的中序遍历 #
输入:root = [1,null,2,3]
输出:[1,3,2]
闭包函数与普通函数的最大区别就是参数不是值传递,而是引用传递,所以闭包函数可以操作自己函数以外的变量。
func inorderTraversal(root *TreeNode) (res []int) {
var inorder func(node *TreeNode)
inorder = func(node *TreeNode) {
if node == nil {
return
}
inorder(node.Left)
res = append(res, node.Val)
inorder(node.Right)
}
inorder(root)
return
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了75.00%的用户
合并两个有叙数组 #
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
//从后往前 分别挑出两个数组中最大的
func merge(nums1 []int, m int, nums2 []int, n int) {
for p,q,i:=m-1,n-1,m+n-1;p>-1&&q>-1&&i>0;i--{
if p>-1&&q>-1&&nums1[p]>nums2[q]{
nums1[i]=nums1[p]
p--
}else{
nums1[i]=nums2[q]
q--
}
if p==-1{ //排除数组1先被拿完的情况
for i:=0;i<=q;i++{
nums1[i]=nums2[i]
}
}
}
if m==0{ //排除数组1为空的情况
for i:=0;i<n;i++{
nums1[i]=nums2[i]
}
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.2 MB, 在所有 Go 提交中击败了73.67%的用户
相同的树 #
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。

输入:p = [1,2,3], q = [1,2,3]
输出:true
func isSameTree(p *TreeNode, q *TreeNode) bool {
if p == nil && q == nil {
return true
}
if p == nil || q == nil {
return false
}
if p.Val != q.Val {
return false
}
return isSameTree(p.Left, q.Left) && isSameTree(p.Right, q.Right)
}
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func isSameTree(p *TreeNode, q *TreeNode) bool {
if p==nil&&q==nil{
return true
}
if p==nil||q==nil{
return false
}
if p.Val!=q.Val{
return false
}
if isSameTree(p.Left,q.Left)&&isSameTree(p.Right,q.Right){//左右子树都没有问题时,则没问题
return true
}
return false
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了87.97%的用户
中等 #
两数相加 #
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。请你将两个数相加,并以相同形式返回一个表示和的链表。你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {//传入的l1指针是ListNode结构体类型的
dummy := &ListNode{}//定义结构体指针赋值为空
for dy,rst :=dummy,0;l1 != nil || l2 != nil || rst !=0;dy = dy.Next{//指针指向同一位置
if l1 != nil {
rst += l1.Val
l1 = l1.Next
}
if l2 != nil {
rst += l2.Val
l2 = l2.Next
}
dy.Next = &ListNode{Val: rst % 10}
rst /=10
}
return dummy.Next
}
无重复字符的最长子串 #
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
func lengthOfLongestSubstring(s string) int {
s1 := make([]rune, 0,len(s))
max := 0
for _, a := range s {
flag := true
for j, b := range s1 {
if b == a {
if len(s1) > max {
max= len(s1)
}
s1 = s1[j+1:]
s1 = append(s1, b)
flag = false
}
}
if flag {
s1 = append(s1, a)
if len(s1) > max {
max = len(s1)
}
}
}
return max
}
执行用时:12 ms, 在所有 Go 提交中击败了44.77%的用户
内存消耗:2.9 MB, 在所有 Go 提交中击败了55.17%的用户
最长回文子串 #
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
func longestPalindrome(s string) string {
s1:=make([]rune,0,len(s))
s2:=make([]rune,0,len(s))
var l,r int
max:=0
min:=0
for _,a:=range s{
s1=append(s1,a)
}
lens:=len(s1)
if lens==1{
return string(s1[0])
}else {
for i:=1;i<lens;i++{
if s1[i]==s1[i-1]{
for l,r=i-1,i;l>=0&&r<lens;{
if s[l]==s[r]{
if r-l>max-min{
max=r
min=l
}
l--
r++
}else{
break
}
}
for l,r=i-1,i+1;l>=0&&r<lens;{
if s[l]==s[r]{
if r-l>max-min{
max=r
min=l
}
l--
r++
}else{
break
}
}
}else {
for l,r=i-1,i+1;l>=0&&r<lens;{
if s[l]==s[r]{
if r-l>max-min{
max=r
min=l
}
l--
r++
}else{
break
}
}
}
}
}
s2=s1[min:max+1]
return string(s2)
}
执行用时:8 ms, 在所有 Go 提交中击败了67.11%的用户
内存消耗:3.4 MB, 在所有 Go 提交中击败了47.22%的用户
Z字型变换 #
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 “PAYPALISHIRING” 行数为 3 时,排列如下:
P A H N
A P L S I I G
Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:“PAHNAPLSIIGYIR”。
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);
示例 1:
输入:s = "PAYPALISHIRING", numRows = 3
输出:"PAHNAPLSIIGYIR"
示例 2:
输入:s = "PAYPALISHIRING", numRows = 4
输出:"PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
func convert(s string, numRows int) string {
num:=numRows
j:=len(s)/num+num
s1:=make([][]rune,num)
for num:=range s1{
s1[num]=make([]rune,0,j)
}
s2:=make([]rune,0,len(s))
for _,a:=range s{
s2=append(s2,a)
}
i:=0
falg:=true
if num==1{
return s
}else {
for _,b:=range s2{
s1[i]=append(s1[i],b)
if falg==false{
i--
if i==(-1){
falg=true
i=1
}
}else {
i++
if i==num{
falg=false
i=num-2
}
}
}
s4:=make([]rune,0,len(s))
for nn:=range s1{
for _,mm:=range s1[nn]{
s4=append(s4,mm)
}
}
return string(s4)
}
}
执行用时:8 ms, 在所有 Go 提交中击败了79.04%的用户
内存消耗:7.3 MB, 在所有 Go 提交中击败了9.95%的用户
字符串转换整数 #
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
函数 myAtoi(string s) 的算法如下:
读入字符串并丢弃无用的前导空格 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。 将前面步骤读入的这些数字转换为整数(即,“123” -> 123, “0032” -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤 2 开始)。 如果整数数超过 32 位有符号整数范围 [−231, 231 − 1] ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于 231 − 1 的整数应该被固定为 231 − 1 。 返回整数作为最终结果。 注意:
本题中的空白字符只包括空格字符 ’ ’ 。 除前导空格或数字后的其余字符串外,请勿忽略 任何其他字符。
func myAtoi(s string) int {
var x int =0
var falg bool = true
s2:=make([]rune,0,len(s))
for _,n:=range s{ //去掉前面空格
if n==' '{
if len(s2)==0{
continue
}else {
s2=append(s2,n)
}
}else {
s2=append(s2,n)
}
}
if len(s2)==0{
return 0
}
s1:=make([]rune,0,len(s2))
i:=0
if s2[i]=='+'{
i++
}else if s2[i]=='-'{
i++
falg=false
}else if s2[i]>57||s2[i]<48{
return 0
}
for i<len(s2){
if s2[i]>=48&&s2[i]<=57{ //数字加入字符串
s1=append(s1,s2[i])
i++
}else{
break
}
}
s=string(s1)
x, _ = strconv.Atoi(s) //字符串 转换为int 型
if falg==true{ //判断正负
x=x
}else{
x=-x
}
if x>(2147483647){ //判断范围
x=2147483647
}else if x<(-2147483648){
x=-2147483648
}
return x
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.4 MB, 在所有 Go 提交中击败了11.08%的用户
盛最多水的容器 #
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0) 。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器。
示例 1:

输入:[1,8,6,2,5,4,8,3,7] 输出:49 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
func maxArea(height []int) int {
i:=0
j:=len(height)-1 //i,j分别指向首尾
var ss,max,ii int
for i<j{
if height[i]<height[j]{
ss=height[i] //ss=最小值
}else {
ss=height[j]
}
ii = ss*(j-i) //容积
ss=ss+1 //ss逐渐增大,两边不够的逐渐排除
if height[i]<ss{
i++
}
if height[j]<ss{
j--
}
if max>ii{ //只保存最大值
max=max
}else {
max=ii
}
}
return max
}
执行用时:84 ms, 在所有 Go 提交中击败了22.36%的用户
内存消耗:8.6 MB, 在所有 Go 提交中击败了14.00%的用户
整数转罗马数字 #
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。 X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。 C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。 给你一个整数,将其转为罗马数字。
func intToRoman(num int) string {
x:=make([]rune,0,10)
for num!=0{
var m int
m=(num/1000)
if m==0{
var d int
d=num/500
if d==0{
var c int
c=num/100
if c==0{
var l int
l=num/50
if l==0{
var xx int
xx=num/10
if xx==0{
var v int
v=num/5
if v==0{
if num==4{
x=append(x,'I')
x=append(x,'V')
num=0
}else{
for i:=0;i<num;i++{
x=append(x,'I')
}
num=0
}
}else{
if num/9==1{
x=append(x,'I')
x=append(x,'X')
num=0
}else{
x=append(x,'V')
for i:=0;i<(num%5);i++{
x=append(x,'I')
}
num=0
}
}
}else {
if xx==4{
x=append(x,'X')
x=append(x,'L')
num=num%10
}else {
for i:=0;i<xx;i++{
x=append(x,'X')
}
num=num%10
}
}
}else {
if num/90==1{
x=append(x,'X')
x=append(x,'C')
num=num%10
}else{
x=append(x,'L')
for i:=0;i<(num/10)-5;i++{
x=append(x,'X')
}
num=num%10
}
}
}else if c==4{
x=append(x,'C')
x=append(x,'D')
num=num%100
}else{
for i:=0;i<c;i++{
x=append(x,'C')
num=num%100
}
}
}else{
if num/900==1{
x=append(x,'C')
x=append(x,'M')
num=num%100
}else { //d==1的情况 678
x=append(x,'D')
for i:=0;i<((num/100)-5);i++{
x=append(x,'C')
}
num=num%100
}
}
}else {
for i:=0;i<m;i++{
x=append(x,'M')
}
num=num%1000
}
}
return string(x)
}
执行用时:4 ms, 在所有 Go 提交中击败了94.18%的用户
内存消耗:3.3 MB, 在所有 Go 提交中击败了91.04%的用户
var valueSymbols = []struct { //标准答案 想复杂了
value int
symbol string
}{
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
}
func intToRoman(num int) string {
roman := []byte{}
for _, vs := range valueSymbols {
for num >= vs.value {
num -= vs.value
roman = append(roman, vs.symbol...)
}
if num == 0 {
break
}
}
return string(roman)
}
三数之和 #
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
func threeSum(nums []int) [][]int {
s1:=make([][]int,0)
if len(nums)<3{ //前期处理
return s1
}
for i:=0;i<len(nums);i++{ //数组排序
for j:=i+1;j<len(nums);j++{
if nums[i]>nums[j]{
nums[i],nums[j]=nums[j],nums[i]
}
}
}
flag:=false //给一个标记
for k:=0;nums[k]<=1&&k<len(nums)-2;k++{ //循环往后找
j:=len(nums)-1
for i:=k+1;i<j;{
if nums[k]+nums[i]+nums[j]>0{ //大于0 后面太大了 向前走
j--
continue
}
if nums[k]+nums[i]+nums[j]<0{ //小于0 前面太小了 向后走
i++
continue
}
if nums[k]+nums[i]+nums[j]==0{ //等于0 插入数组
if len(s1)==0{ //判断是否为第一组 感觉有点多余
s1=append(s1,[]int{nums[k],nums[i],nums[j]})
i++ //i++ continue不要在往后了
continue
}else{
for _,d:=range s1{ //先遍历一遍去重
if len(d)>0{
if nums[k]==d[0]&&nums[i]==d[1]&&nums[j]==d[2] {
flag=true //找到了 改标记
break
}
}else {
break
}
}
if flag==false{ //看标记插入
s1=append(s1,[]int{nums[k],nums[i],nums[j]})
i++
continue
}
flag=false
}
i++
}
}
}
return s1
}
执行用时:324 ms, 在所有 Go 提交中击败了7.65%的用户
内存消耗:7.4 MB, 在所有 Go 提交中击败了92.49%的用户
func threeSum(nums []int) [][]int {
n := len(nums)
sort.Ints(nums) //排序
ans := make([][]int, 0)
// 枚举 a
for first := 0; first < n; first++ {
// 需要和上一次枚举的数不相同
if first > 0 && nums[first] == nums[first - 1] {
continue
}
// c 对应的指针初始指向数组的最右端
third := n - 1
target := -1 * nums[first]
// 枚举 b
for second := first + 1; second < n; second++ {
// 需要和上一次枚举的数不相同
if second > first + 1 && nums[second] == nums[second - 1] {
continue
}
// 需要保证 b 的指针在 c 的指针的左侧
for second < third && nums[second] + nums[third] > target {
third--
}
// 如果指针重合,随着 b 后续的增加
// 就不会有满足 a+b+c=0 并且 b<c 的 c 了,可以退出循环
if second == third {
break
}
if nums[second] + nums[third] == target {
ans = append(ans, []int{nums[first], nums[second], nums[third]})
}
}
}
return ans
}
最接近的三数之和 #
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例:
输入:nums = [-1,2,1,-4], target = 1
输出:2
解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
func threeSumClosest(nums []int, target int) int {
sort.Ints(nums) //排序
j := len(nums) - 1
max := nums[0] + nums[1] + nums[2]
aa := float64(max - target)
cc := math.Abs(aa)
for k := 0; k < j-1; k++ { //循环遍历
j = len(nums) - 1
for i := k + 1; i < j; {
kij := nums[k] + nums[i] + nums[j]
hhl := float64(kij - target)
bb := math.Abs(hhl)
if kij < target { //小了 加一个
if cc > bb {
cc = bb
max = kij
}
i++
} else if kij > target { //大了 减一个
if cc > bb {
cc = bb
max = kij
}
j--
} else {
return kij
}
}
}
return max
}
执行用时:4 ms, 在所有 Go 提交中击败了96.46%的用户
内存消耗:2.7 MB, 在所有 Go 提交中击败了66.12%的用户
电话号码的字母组合 #
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
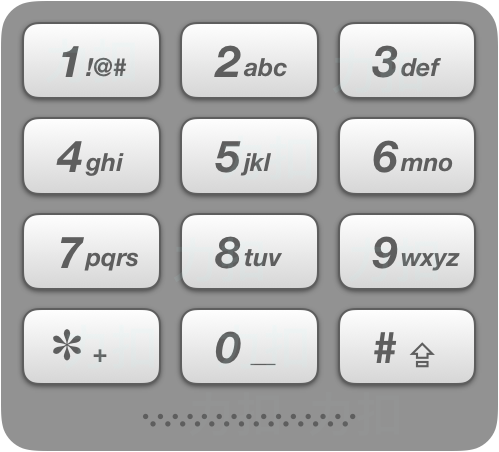
示例 1:
输入:digits = "23"
输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
var ss = [8][]string{ //设二维数组
{"a", "b", "c"},
{"d", "e", "f"},
{"g", "h", "i"},
{"j", "k", "l"},
{"m", "n", "o"},
{"p", "q", "r", "s"},
{"t", "u", "v"},
{"w", "x", "y", "z"},
}
func letterc(a []string, b []string) []string { //设置函数处理两个数组
var cc []string
for i := 0; i < len(a); i++ {
for j := 0; j < len(b); j++ {
cc = append(cc, a[i]+b[j])
}
}
return cc
}
func letterCombinations(digits string) []string {
var cc []string
var digitsint []int
for _, d := range digits { //处理一下字符串 转int 匹配对应数组
dint, _ := strconv.Atoi(string(d))
digitsint = append(digitsint, dint)
}
if len(digits) == 0 {
return cc
}
if len(digits) == 1 { //分情况讨论
cc := ss[digitsint[0]-2]
return (cc)
}
if len(digits) == 2 {
a := ss[digitsint[0]-2]
b := ss[digitsint[1]-2]
cc = letterc(a, b)
return cc
} else { //大于等于3的情况
a := ss[digitsint[0]-2]
b := ss[digitsint[1]-2]
cc = letterc(a, b)
for i := 2; i < len(digits); i++ {
aaa := ss[digitsint[i]-2]
cc = letterc(cc, aaa)
}
return cc
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了21.63%的用户
四数之和 #
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < n a、b、c 和 d 互不相同 nums[a] + nums[b] + nums[c] + nums[d] == target 你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0
输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
func fourSum(nums []int, target int) [][]int {
sort.Ints(nums) //数组排序
s1 := make([][]int, 0)
if len(nums) < 4 {
return s1
}
flag := true
for m := 0; m < len(nums); m++ {
for n := m + 1; n < len(nums)-2; n++ {
j := len(nums) - 1
for i := n + 1; i < j; {
num := nums[m] + nums[n] + nums[i] + nums[j]
if num < target {
i++
}
if num > target {
j--
}
if num == target {
for _, d := range s1 { //先遍历一遍去重
if len(d) > 0 {
if nums[m] == d[0] && nums[n] == d[1] && nums[i] == d[2] && nums[j] == d[3] {
flag = false //找到了 改标记
break
}
} else {
break
}
}
if flag == true { //看标记插入
s1 = append(s1, []int{nums[m], nums[n], nums[i], nums[j]})
i++
continue
}
flag = true
i++
}
}
}
}
return s1
}
执行用时:28 ms, 在所有 Go 提交中击败了15.10%的用户
内存消耗:2.9 MB, 在所有 Go 提交中击败了24.59%的用户
删除链表的倒数第N个节点 #
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
**进阶:**你能尝试使用一趟扫描实现吗?

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
package main
type ListNode struct {
Val int
Next *ListNode
}
func removeNthFromEnd(head *ListNode, n int) *ListNode {
p := head //设两个指针指向头指针
q := head
c := 0 //给出计数
if head.Next == nil { //排除特殊情况
return head.Next
}
for head.Next != nil {
if c == n {
p = p.Next
} else {
c++ //计数 直到c==n
}
head = head.Next
}
if c == n { //去掉这个数
p.Next = p.Next.Next
}
if c < n { //排除n==len(数组)
return q.Next
}
return q
}
func main() {
list := []int{1, 2, 3, 4, 5}
head := &ListNode{Val: list[0]}
tail := head
for i := 1; i < len(list); i++ {
head.Next = &ListNode{Val: list[i]}
head = head.Next
}
println(tail.Val)
println(tail.Next.Val)
n := 2
x := removeNthFromEnd(tail, n)
print(x)
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.2 MB, 在所有 Go 提交中击败了99.97%的用户
括号生成 #
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
有效括号组合需满足:左括号必须以正确的顺序闭合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
func generateParenthesis(n int) []string {
s=make([]string,0) //不能为var s []string append 插不进去
generate(n,0,0,"") //设置一个函数 递归调用
return s
}
func generate(n int,l int ,r int,cur string){
if r==n&&l==n{ //左括号数量=右括号数量=n时 插入数组切片
s=append(s,cur)
return
}
if l<n{ //左括号数量小于n时 cur加入“(”
generate(n,l+1,r,cur+"(")
}
if r<n&&r<l{ //右括号数量小于n切 右括号的数量要小于左括号 cur+")"
generate(n,l,r+1,cur+")")
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.7 MB, 在所有 Go 提交中击败了71.77%的用户
两两交换链表中的节点 #
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。

输入:head = [1,2,3,4]
输出:[2,1,4,3]
func swapPairs(head *ListNode) *ListNode {
var p, q, m *ListNode //定义三个指针
if head == nil {
return head
} else {
he := &ListNode{Val: -1, Next: head}
m = he //m始终指向p,q前面
p = head //p在前
q = head.Next //q在后
for p != nil && q != nil {
p.Next = q.Next
q.Next = p //交换
m.Next = q
m = p //m跟上
p = p.Next
if p == nil { //结束条件
break
}
q = p.Next
}
return he.Next
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了56.09%的用户
两数相除 #
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数 dividend 除以除数 divisor 得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
示例 1:
输入: dividend = 10, divisor = 3
输出: 3
解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
func dd(a int, b int) int { //返回两个正数的除后的值
if b == 1 { //排除b==1的情况
return a
}
if a > b {
i := 1
d := b //给个记录
for a > b {
b = b << 1 // <<1 相当于乘2
i = i << 1
}
if a < b { //证明给高了
b = b >> 1 //除回来
i = i >> 1
c := a - b
for c >= d { //用简单的加法
c = c - d
i++
}
}
return i //返回
} else if a == b { //a==b的情况
return 1
} else { //a<b的情况
return 0
}
}
func divide(dividend int, divisor int) int {
if dividend == 0 {
return 0
}
var b int
if dividend < 0 { //保证给上面函数提供两个正数
if divisor > 0 {
c := dd((-dividend), divisor)
b = -c //根据情况加负号
} else {
c := dd(-dividend, -divisor)
b = c
}
} else {
if divisor > 0 {
c := dd(dividend, divisor)
b = c
} else {
c := dd(dividend, -divisor)
b = -c
}
}
if b > (2147483647) { //判断范围
b = 2147483647
} else if b < (-2147483648) {
b = -2147483648
}
return b
}
执行用时:364 ms, 在所有 Go 提交中击败了58.55%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了5.12%的用户
下一个排列 #
实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列(即,组合出下一个更大的整数)。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须 原地 修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3]
输出:[1,3,2]
示例 2:
输入:nums = [3,2,1]
输出:[1,2,3]
func nextPermutation(nums []int) []int {
b := 0
for i := len(nums) - 1; i > 0; i-- { //从后往前遍历
if nums[i] > nums[i-1] { //如果比前一个大
a := 0
num := nums[i:] //截取切片
sort.Ints(num) //升序排列
for n := 0; n < len(num); n++ { //遍历这个排列找到比它大的最小值
if num[n] > nums[i-1] {
a = nums[i-1] //交换位置
nums[i-1] = num[n]
num[n] = a
break
}
}
sort.Ints(num) //后面的再进行升序
for j := 0; j < len(num); j++ { //插入原来的数组
nums[i] = num[j]
i++
}
break //返回
} else { //如果不大于前一个数 计数
b++
}
}
if b == len(nums)-1 { //计数等于数组长度 则全是降序
nums = sort.Ints(nums) //将它生序
}
return nums
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了15.16%的用户
func isPalindrome(head *ListNode) bool {//递归
var spalin func(*ListNode) bool
spalin = func(head1 *ListNode) bool {
if head1 != nil {
if spalin(head1.Next) == false {
return false
}
if head.Val != head1.Val {
return false
}
head = head.Next
}
return true
}
return spalin(head)
}
执行用时:164 ms, 在所有 Go 提交中击败了14.99%的用户
内存消耗:17.6 MB, 在所有 Go 提交中击败了5.19%的用户
搜索旋转排序数组 #
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
func search(nums []int, target int) int {
if len(nums) >= 2 { //>=2的时候
l := 0
r := len(nums) - 1 //分别指向首尾
for l <= r {
i := (l + r) / 2
if nums[i] == target { //找到返回
return i
}
if nums[0] <= nums[i] { //前半部分部分
if nums[0] <= target && target < nums[i] {
r = i - 1
} else {
l = i + 1
}
} else {
if nums[i] < target && target <= nums[len(nums)-1] {
l = i + 1
} else {
r = i - 1
}
}
}
} else { //如果只有一个或0个的时候
if len(nums) == 1 && nums[0] == target {
return 0
} else {
return -1
}
}
return -1
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了100.00%的用户
在排序数组中查找元素的第一个和最后一个位置 #
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
在排序数组中查找元素的第一个和最后一个位置 #
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
func searchRange(nums []int, target int) []int {
l := sort.SearchInts(nums, target) //找出这个数并返回下标
if l == len(nums) || nums[l] != target {
return []int{-1, -1}
}
r := sort.SearchInts(nums, target + 1) - 1 //找出比他大的数返回下标 减1
return []int{l, r}
}
执行用时:8 ms, 在所有 Go 提交中击败了40.01%的用户
内存消耗:3.9 MB, 在所有 Go 提交中击败了59.36%的用户
有效的数独 #
请你判断一个 9x9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图) 数独部分空格内已填入了数字,空白格用 ‘.’ 表示。
注意:
一个有效的数独(部分已被填充)不一定是可解的。 只需要根据以上规则,验证已经填入的数字是否有效即可。
func isValidSudoku(board [][]byte) bool {
for i := 0; i < 9; i++ { //检查每行每列
for j := 0; j < 8; j++ {
a := board[i][j]
b := board[j][i]
for k := j + 1; k < 9; k++ {
if a == board[i][k] && a != 46 { //行
return false
}
if b == board[k][i] && b != 46 { //列
return false
}
}
}
for j := 0; j < 9; j++ { //检查每个小方块
for k := i + 1; k%3 != 0; k++ { //直接从下一行检查
for h := j / 3 * 3; h < j/3*3+3; h++ {
if board[i][j] == board[k][h] && board[i][j] != 46 {
return false
}
}
}
}
}
return true
}
执行用时:4 ms, 在所有 Go 提交中击败了60.38%的用户
内存消耗:2.6 MB, 在所有 Go 提交中击败了71.78%的用户
外观数列 #
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
countAndSay(1) = “1” countAndSay(n) 是对 countAndSay(n-1) 的描述,然后转换成另一个数字字符串。 前五项如下:
1. 1
2. 11
3. 21
4. 1211
5. 111221
第一项是数字 1 描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 “11” 描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 “21” 描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 “1211” 描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 “111221” 要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
func countAndSay(n int) string {
s := make([]rune, 0)
c := '1'
s = append(s, c)
for i := 1; i < n; i++ { //n==1直接输出,大于1循环
d := s[0] //d==第一个字节
s2 := make([]rune, 0)
for a, b := range s { //遍历s
if a == 0 { //去掉第一个重复的
continue
}
if d != b { //遇到不一样的
s2 = append(s2, c, d) //将之前的加入
d = b //d改成现在的b
c = '1' // 计数改为1
} else { //遇到一样的 C++
c++
}
}
s2 = append(s2, c, d) //将最后的结果加入
s = s2
c = '1' //c计数改为1
}
return string(s)
}
执行用时:216 ms, 在所有 Go 提交中击败了14.13%的用户
内存消耗:7.2 MB, 在所有 Go 提交中击败了46.46%的用户
组合总和 #
给定一个无重复元素的正整数数组 candidates 和一个正整数 target ,找出 candidates 中所有可以使数字和为目标数 target 的唯一组合。
candidates 中的数字可以无限制重复被选取。如果至少一个所选数字数量不同,则两种组合是唯一的。
对于给定的输入,保证和为 target 的唯一组合数少于 150 个。
示例 1:
输入: candidates = [2,3,6,7], target = 7
输出: [[7],[2,2,3]]
func combinationSum(candidates []int, target int) [][]int {
sum := 0
start := 0
var s = make([][]int, 0)
var s1 = make([]int, 0)
var combination func(candidates []int, target int, sum int, start int) //定义内置函数 将两个函数分开会出错,不是函数本身错误 它系统有问题过不去
combination = func(candidates []int, target int, sum int, start int) {
if sum == target { //如果和与target相等
t := make([]int, len(s1)) //切片只是一个指向基础数组的指针,必须复制
copy(t, s1) //如果不希望影响其他切片,需要创建切片副本
s = append(s, t) //插入正确答案
return
}
for i := start; i < len(candidates); i++ {
if sum > target { //剪枝,大于 终止循环
break
}
s1 = append(s1, candidates[i]) //插入数组
sum = sum + candidates[i] //求和
combination(candidates, target, sum, i) //回溯
sum = sum - candidates[i] //撤销操作
s1 = s1[:len(s1)-1]
}
}
combination(candidates, target, sum, start)
return s
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.7 MB, 在所有 Go 提交中击败了98.66%的用户
组合总和II #
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
注意:解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
func combinationSum2(candidates []int, target int) [][]int {
sort.Ints(candidates) //排序
var s = make([][]int, 0) //最终输出数组
var s1 = make([]int, 0) //单个记录答案数组
vis := make([]bool, len(candidates)) //一个标记数组,去重
sum := 0 //和
star := 0 //candidates开始下标
var combin func(candidates []int, target int, sum int, star int)
combin = func(candidates []int, target int, sum int, star int) {
//根据上个题的经验 将回溯函数建立在函数内部
if sum == target { //如何和相等
t := make([]int, len(s1)) //新建答案数组 复制插入,切片是指针
copy(t, s1)
s = append(s, t)
return
}
for i := star; i < len(candidates); i++ { //从开始下标遍历
if sum > target { //大于 剪枝,后面不用遍历
break
}
// vis[i - 1] == true,说明同一树支candidates[i - 1]使用过
// vis[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if i > 0 && candidates[i] == candidates[i-1] && !vis[i-1] {
continue //去重
}
vis[i] = true
sum = sum + candidates[i]
s1 = append(s1, candidates[i])
combin(candidates, target, sum, i+1) //回溯
sum = sum - candidates[i]
s1 = s1[:len(s1)-1]
vis[i] = false
}
}
combin(candidates, target, sum, star)
return s
}
执行用时:4 ms, 在所有 Go 提交中击败了45.08%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了88.90%的用户
字符串相乘 #
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
注意:不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
示例 1:
输入: num1 = "2", num2 = "3"
输出: "6"
示例 2:
输入: num1 = "123", num2 = "456"
输出: "56088"
func multiply(num1 string, num2 string) string {
if num1 == "0" || num2 == "0" {
return "0"
}
ans := "0"
m, n := len(num1), len(num2)
for i := n - 1; i >= 0; i-- {
curr := ""
add := 0
for j := n - 1; j > i; j-- {//字符串移位加0
curr += "0"
}
y := int(num2[i] - '0')
for j := m - 1; j >= 0; j-- {
x := int(num1[j] - '0')
product := x * y + add
curr = strconv.Itoa(product % 10) + curr
add = product / 10
}
for ; add != 0; add /= 10 {
curr = strconv.Itoa(add % 10) + curr
}
ans = addStrings(ans, curr)
}
return ans
}
func addStrings(num1, num2 string) string {
i, j := len(num1) - 1, len(num2) - 1
add := 0
ans := ""
for ; i >= 0 || j >= 0 || add != 0; i, j = i - 1, j - 1 {
x, y := 0, 0
if i >= 0 {
x = int(num1[i] - '0')
}
if j >= 0 {
y = int(num2[j] - '0')
}
result := x + y + add
ans = strconv.Itoa(result % 10) + ans
add = result / 10
}
return ans
}
执行用时:44 ms, 在所有 Go 提交中击败了9.51%的用户
内存消耗:6.7 MB, 在所有 Go 提交中击败了21.60%的用户
跳跃游戏2 #
给你一个非负整数数组 nums ,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
假设你总是可以到达数组的最后一个位置。
示例 1:
输入: nums = [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
示例 2:
输入: nums = [2,3,0,1,4]
输出: 2
func jump(nums []int) int { //创建一个切片记录
m := len(nums)
n1:=0
a:=0
num:=make([]int,m)
for i:=0;i<m;i++{
n2:=i+nums[i] //本次能挑到的最远值
if n2>n1{ //如果比n1大 则换值
n1=n2
a=num[i]+1 //a++ 为了确保不出错 从num[i]上加
}
for i:=1;i<=n1&&i<m;i++{ //更新这个切片 防止越界 加上i<m
if num[i]==0{ //如果里面没有值 则加上a
num[i]=a
}
}
}
return num[m-1] //最后输出最后记录值
}
执行用时:236 ms, 在所有 Go 提交中击败了5.04%的用户
内存消耗:6.1 MB, 在所有 Go 提交中击败了27.96%的用户
func jump(nums []int) int {
m := len(nums)
n1 := 0
a := 0 //记录跳跃次数
max := 0 //记录边界
for i := 0; i < m-1; i++ { //i<m-1可防止只有一个值时 程序执行for循环
n2 := i + nums[i] //最远值
if n2 > n1 { //找到跳的最大值
n1 = n2
}
if i == max { //到达边界
max = n1 //边界等于最大值
a++ //步数+1
}
}
return a
}
执行用时:20 ms, 在所有 Go 提交中击败了35.90%的用户
内存消耗:5.8 MB, 在所有 Go 提交中击败了53.87%的用户
全排列 #
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
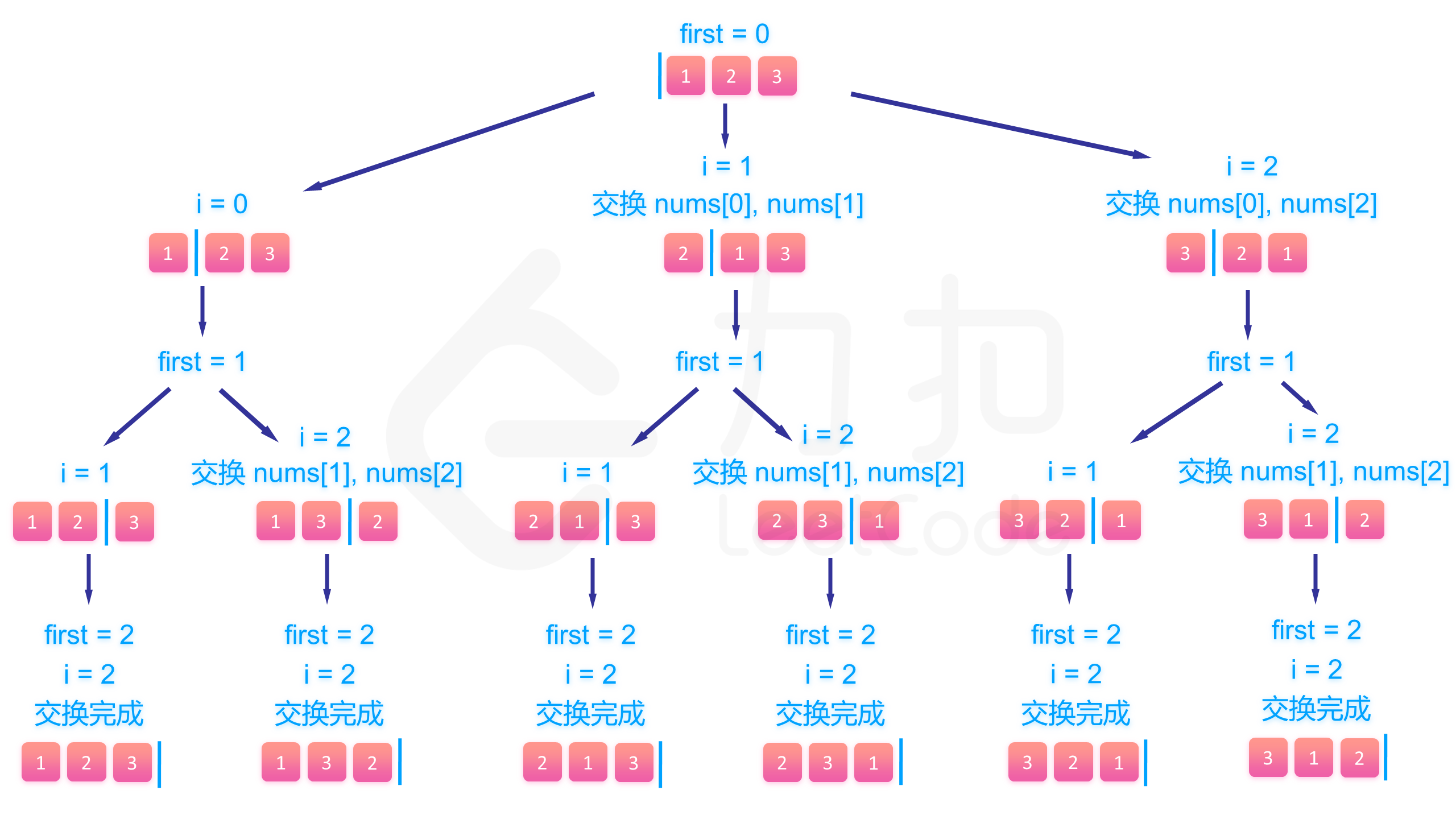
func permute(nums []int) [][]int {
n := len(nums)
num := make([][]int, 0)
var backtrace func(path int) //内置循环函数
backtrace = func(path int) {
if path == n { //深度等于n 输出
nu := make([]int, n)
copy(nu, nums) //不然会全部改变
num = append(num, nu)
return
}
for i := path; i < n; i++ {
nums[path], nums[i] = nums[i], nums[path] //交换位置
backtrace(path + 1) //递归
nums[path], nums[i] = nums[i], nums[path] //撤销交换
}
}
backtrace(0)
return num
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.4 MB, 在所有 Go 提交中击败了99.60%的用户
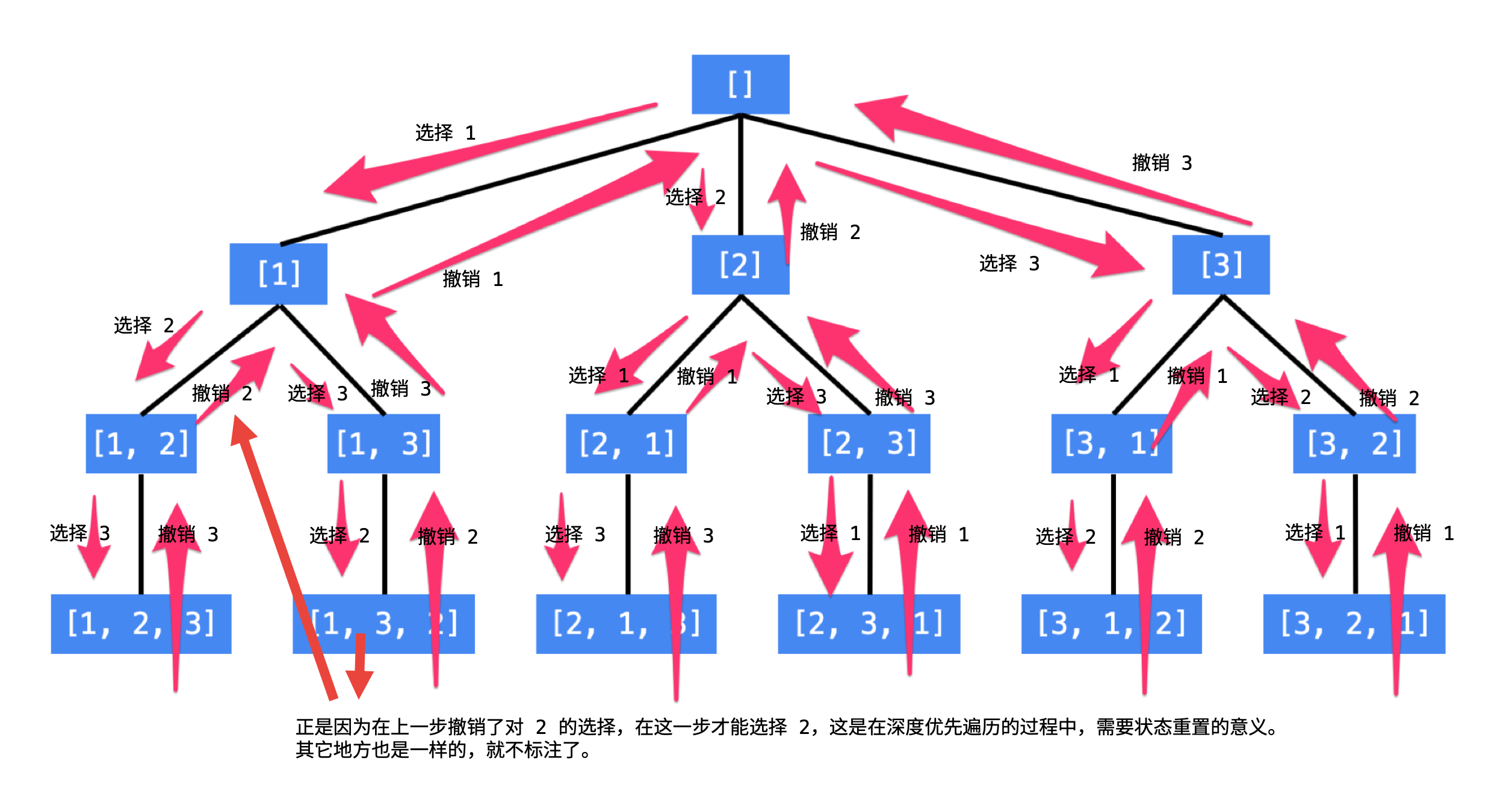
var res [][]int
func permute(nums []int) [][]int {
res = [][]int{}
backTrack(nums,len(nums),[]int{})
return res
}
func backTrack(nums []int,numsLen int,path []int) {
if len(nums)==0{
p:=make([]int,len(path))
copy(p,path)
res = append(res,p)
}
for i:=0;i<numsLen;i++{
cur:=nums[i]
path = append(path,cur)
nums = append(nums[:i],nums[i+1:]...)//直接使用切片
backTrack(nums,len(nums),path)
nums = append(nums[:i],append([]int{cur},nums[i:]...)...)//回溯的时候切片也要复原,元素位置不能变
path = path[:len(path)-1]
}
}
func permute(nums []int) [][]int {
if len(nums) == 0 {
return nil
}
//思路是在已有的排列数组中,从头到尾见缝插针,组成新的全排列
//比如有 1,2 的情况下,插入3,就是在头插入 3,1,2;中间插入1,3,2;尾巴插入1,2,3
temp := make([][]int,0)
temp = append(temp,[]int{nums[0]})
for i:=1;i<len(nums);i++{
temp2 := temp
temp = make([][]int,0)
for j:=0;j<=i;j++{
for k:=0;k<len(temp2);k++ {
temp3 := make([]int, 0)
temp3 = append(temp3, temp2[k][0:j]...)
temp3 = append(temp3, nums[i])
temp3 = append(temp3, temp2[k][j:]...)
temp = append(temp, temp3)
}
}
}
return temp
}
全排列2 #
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
var marry [][]int
func permuteUnique(nums []int) [][]int {
marry=[][]int{}
tmp:=[]int{}
sort.Ints(nums) //先给切片排序 这种算法要牢记
backtraceing(nums,tmp)
return marry
}
func backtraceing(nums []int,tmp []int){
if len(nums)==0{ //如果
cc:=make([]int,len(tmp))
copy(cc,tmp)
marry=append(marry,cc)
}
for i:=0;i<len(nums);i++{
if i>0&&nums[i]==nums[i-1]{ // 去重
continue
}
cur:=nums[i] //
tmp=append(tmp,nums[i])
nums = append(nums[:i],nums[i+1:]...) //切片删除第i个元素
backtraceing(nums,tmp)
nums = append(nums[:i],append([]int{cur},nums[i:]...)...) //切片在第i个位置增加元素
tmp=tmp[:len(tmp)-1]
}
}
执行用时:4 ms, 在所有 Go 提交中击败了53.95%的用户
内存消耗:3.9 MB, 在所有 Go 提交中击败了23.05%的用户
旋转图像 #
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
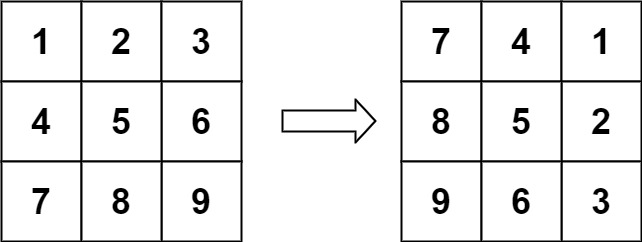
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]]】
func rotate(matrix [][]int) { //有点绕 背答案吧
n := len(matrix)
for i := 0; i < n/2; i++ {
for j := 0; j < (n+1)/2; j++ {
matrix[i][j], matrix[n-j-1][i], matrix[n-i-1][n-j-1], matrix[j][n-i-1] =
matrix[n-j-1][i], matrix[n-i-1][n-j-1], matrix[j][n-i-1], matrix[i][j]
}
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了100.00%的用户
字母异位词分组 #
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
func SortString(s string) string { //排序函数
ss := make([]rune, 0)
for _, n := range s {
ss = append(ss, n)
}
for i := 0; i < len(ss); i++ {
for j := i + 1; j < len(ss); j++ {
if ss[i] > ss[j] {
a := ss[i]
ss[i] = ss[j]
ss[j] = a
}
}
}
return string(ss)
}
func groupAnagrams(strs []string) [][]string {
mp := map[string][]string{} //建立一个字典
for _, str := range strs { //遍历字符串数组
ss := SortString(str) //排序
mp[ss] = append(mp[ss], str) //加入字典
}
ans := make([][]string, 0, len(mp))
for _, v := range mp { //将字典中的数据加入二维数组
ans = append(ans, v)
}
return ans
}
执行用时:24 ms, 在所有 Go 提交中击败了54.24%的用户
内存消耗:7.9 MB, 在所有 Go 提交中击败了71.81%的用户
Pow(x,n) #
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn )。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
func Pow(x float64, n int) float64 { //精髓在这里 2^0 2^1 2^2 2^4 2^8
if n == 0 { //不然会超时
return 1
}
y := Pow(x, n/2)
if n%2 == 0 {
return y * y
}
return y * y * x
}
func myPow(x float64, n int) float64 {
if n > 0 {
if x < 0 {
if n%2 == 1 {
x = -Pow(-x, n)
} else {
x = Pow(-x, n)
}
} else {
x = Pow(x, n)
}
} else if n == 0 {
return 1.0
} else { //n<0
if x < 0 {
if (-n)%2 == 1 {
x = -Pow(-x, -n)
} else {
x = Pow(-x, -n)
}
} else {
x = (1 / Pow(x, -n))
}
}
return x
}
func myPow(x float64, n int) float64 { //最后结果跟x正负没有关系
if n > 0 {
x = Pow(x, n)
} else if n == 0 {
return 1.0
} else { //n<0
x = (1 / Pow(x, -n))
}
return x
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了86.38%的用户
螺旋矩阵 #
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。

输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
func spiralOrder(matrix [][]int) []int {
m := len(matrix)
n := len(matrix[0])
s := make([]int, 0)
if m == 1 { //处理只有一行
for i := 0; i < n; i++ {
s = append(s, matrix[0][i])
}
} else if n == 1 {//处理只有一列
for i := 0; i < m; i++ {
s = append(s, matrix[i][0])
}
} else {
matrix2 := make([][]bool, m)
for i := 0; i < m; i++ { //创建记录数组,默认为false
matrix2[i] = make([]bool, n)
}
for i, j := 0, 0; i < m && j < n; { //循环
for j < n && matrix2[i][j] == false { //遍历到尾部,向下
s = append(s, matrix[i][j])
matrix2[i][j] = true
j++
}
if j == n || matrix2[i][j] == true { //到尾部,改i,j
j--
i++
}
for i < m && matrix2[i][j] == false { //向下遍历
s = append(s, matrix[i][j])
matrix2[i][j] = true
i++
}
if i == m || matrix2[i][j] == true {//到底部,改i,j
i--
j--
}
for j > -1 && matrix2[i][j] == false {//向左遍历
s = append(s, matrix[i][j])
matrix2[i][j] = true
j--
}
if j == -1 || matrix2[i][j] == true { //到左边,改i,j
j++
i--
}
for i > -1 && matrix2[i][j] == false {//向上遍历
s = append(s, matrix[i][j])
matrix2[i][j] = true
i--
}
if i == 0 || matrix2[i][j] == true {//到顶部,改i,j
i++
j++
if matrix2[i][j] == true { //设置结束条件
break
}
}
}
}
return s
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了77.39%的用户
跳跃游戏 #
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
func canJump(nums []int) bool {
n:=len(nums)
boundary:=0 //设置边界
for i:=0;i<n;i++{
if (i+nums[i])>boundary{
boundary=i+nums[i] //更新边界
}
if nums[i]==0&&n>1&&i>=boundary{ //去除[0][0,1][3,0,4]
return false
}
if boundary>=n-1{ //边界超出 true
return true
}
}
return false
}
执行用时:52 ms, 在所有 Go 提交中击败了74.87%的用户
内存消耗:6.7 MB, 在所有 Go 提交中击败了75.06%的用户
合并区间 #
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
func merge(intervals [][]int) [][]int {
for i := 0; i < len(intervals); i++ { //先从第一个值开始排序 不排序搞不了,试过了
for j := i + 1; j < len(intervals); j++ {
if intervals[i][0] > intervals[j][0] {
a := intervals[i][0]
b := intervals[i][1]
intervals[i][0] = intervals[j][0]
intervals[i][1] = intervals[j][1]
intervals[j][0] = a
intervals[j][1] = b
}
}
}
for i := 0; i < len(intervals); {
if i+1 < len(intervals)&& intervals[i][1] <= intervals[i+1][1]&&intervals[i][1]>=intervals[i+1][0] {//[a,b][c,d] d>=b>=c 时
intervals[i][1] = intervals[i+1][1] //b=d
intervals = append(intervals[:i+1], intervals[i+2:]...) //去掉后面的
i=0
} else{
if i+1 < len(intervals)&& intervals[i][1] > intervals[i+1][1] {//b>d时
intervals = append(intervals[:i+1], intervals[i+2:]...) //去掉后面的
i=0
}else{
i++ //i++
}
}
}
return intervals
}
插入区间 #
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
//最笨方法
func merge(intervals [][]int) [][]int {
for i := 0; i < len(intervals); i++ { //先从第一个值开始排序 不排序搞不了,试过了
for j := i + 1; j < len(intervals); j++ {
if intervals[i][0] > intervals[j][0] {
a := intervals[i][0]
b := intervals[i][1]
intervals[i][0] = intervals[j][0]
intervals[i][1] = intervals[j][1]
intervals[j][0] = a
intervals[j][1] = b
}
}
}
for i := 0; i < len(intervals); {
if i+1 < len(intervals) && intervals[i][1] <= intervals[i+1][1] && intervals[i][1] >= intervals[i+1][0] { //[a,b][c,d] d>=b>=c 时
intervals[i][1] = intervals[i+1][1] //b=d
intervals = append(intervals[:i+1], intervals[i+2:]...) //去掉后面的
i = 0
} else {
if i+1 < len(intervals) && intervals[i][1] > intervals[i+1][1] { //b>d时
intervals = append(intervals[:i+1], intervals[i+2:]...) //去掉后面的
i = 0
} else {
i++ //i++
}
}
}
return intervals
}
func insert(intervals [][]int, newInterval []int) [][]int {
if len(intervals) == 0 { //如果长度为零,直接加入输出
intervals = append(intervals, newInterval)
} else { //直接插入 然后用上面函数重新排序 合并 最笨方法
intervals = append(intervals, newInterval)
intervals = merge(intervals)
}
return intervals
}
执行用时:92 ms, 在所有 Go 提交中击败了5.41%的用户
内存消耗:4.5 MB, 在所有 Go 提交中击败了95.68%的用户
func insert(intervals [][]int, newInterval []int) [][]int {
ans := make([][]int, 0)
acc := false //哨兵 插入变true
for _, terval := range intervals {
if newInterval[1] < terval[0] { //在左边 无交集
if acc != true {
ans = append(ans, newInterval) //先把newInterval插入 并做好标记
acc = true
}
ans = append(ans, terval) //继续插入其他元素
} else if newInterval[0] > terval[1] { //在右边 无交集
ans = append(ans, terval) // 先插入 interval newInterval先放着
} else { //有交集的情况 更改 newInterval值
newInterval[0] = min(newInterval[0], terval[0])
newInterval[1] = max(newInterval[1], terval[1])
}
}
if acc != true { //如果遍历完还没插入 则加后面
ans = append(ans, newInterval)
}
return ans
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
执行用时:8 ms, 在所有 Go 提交中击败了75.14%的用户
内存消耗:4.5 MB, 在所有 Go 提交中击败了83.78%的用户
螺旋矩阵2 #
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
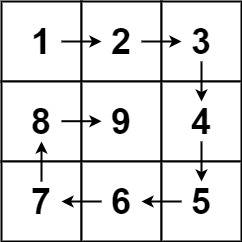
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
func generateMatrix(n int) [][]int {
made := make([][]int, 0)
mm := make([]int, 0)
for i := 0; i < n; i++ { //创建数组
mm = append(mm, 0)
}
for i := 0; i < n; i++ { //创建二维数组
cc := make([]int, len(mm)) //这里要copy 不然会一起改变数字
copy(cc, mm)
made = append(made, cc)
}
if n == 1 { //排除n==1的情况
made[0][0] = 1
return made
}
m := 1
for i, j := 0, 0; m < n*n+1; { //给出循环限定条件 让他一直转
if made[i][j] != 0 { //改变方向条件
i++
j++
}
for j < n-1 && made[i][j] == 0 { //从左往右
made[i][j] = m
m++
j++
}
if made[i][j] != 0 { //改变方向
j--
i++
}
for i < n-1 && made[i][j] == 0 { //从上往下
made[i][j] = m
m++
i++
}
if made[i][j] != 0 { //改变方向
i--
j--
}
for j > 0 && made[i][j] == 0 { //从右往左
made[i][j] = m
m++
j--
}
if made[i][j] != 0 { //改变方向
i--
j++
}
for i > 0 && made[i][j] == 0 { //从下往上
made[i][j] = m
m++
i--
}
}
return made
}
旋转链表 #
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
//自己写的超时算法
func Rotate(head *ListNode) *ListNode { //整体后移一位 这里head直接指数字
var p, q *ListNode
p = head
q = p
if p.Next != nil {
p = p.Next
}
for p.Next != nil {
p = p.Next
q = q.Next
}
p.Next = head
head = p
q.Next = nil
return head
}
func rotateRight(head *ListNode, k int) *ListNode {
if head == nil || k == 0 || head.Next == nil { //排除特殊情况
return head
}
for i := 0; i < k; i++ { //循环 则意味着超时
head = Rotate(head)
}
return head
}
func rotateRight(head *ListNode, k int) *ListNode {
if head==nil||k==0||head.Next==nil {
return head
}
num:=1 //计数 看链表有多少个数
p:=head
for p.Next!=nil{ //循环计数
num++
p=p.Next
}
p.Next=head //链表首尾相连
cx:=num-k%num //看一下就知道为什么要这样
if cx==0{
return head
}
for i:=0;i<cx;i++{ //找到那个头 断开
head=head.Next
p=p.Next
}
p.Next=nil
return head
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.4 MB, 在所有 Go 提交中击败了54.93%的用户
不同路径 #
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
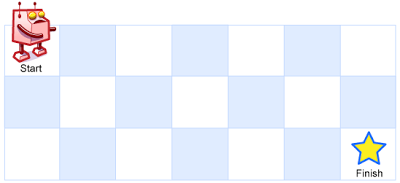
输入:m = 3, n = 7
输出:28
func uniquePaths(m int, n int) int { //动态规划
array := make([][]int, m) //var array [m][n]int 不可取,m n 必须是常量才可以创建
for i := range array { //array:=[m][n]int{} 也不行,要常量
array[i] = make([]int, n)
}
for i := 0; i < m; i++ { //第一列 每个到达路径都为1
array[i][0] = 1
}
for j := 0; j < n; j++ { //第一行 每个到达路径都为1
array[0][j] = 1
}
for i := 1; i < m; i++ {
for j := 1; j < n; j++ { //array[i][j] = array[i-1][j] + array[i][j-1]
array[i][j] = array[i-1][j] + array[i][j-1]
}
}
return array[m-1][n-1]
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了51.82%的用户
不同路径2 #
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。

输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
m := len(obstacleGrid)
n := len(obstacleGrid[0])
array := make([][]int, m) //这道题的关键在于重新创建数组,在原数组上修改比较麻烦
for i, _ := range array {
array[i] = make([]int, n)
}
for i := 0; i < m && obstacleGrid[i][0] == 0; i++ { //前面是0的全改为1后面的不变全是0 新建的数组
array[i][0] = 1
}
for j := 0; j < n && obstacleGrid[0][j] == 0; j++ {
array[0][j] = 1
}
for i := 1; i < m; i++ {
for j := 1; j < n; j++ {
if obstacleGrid[i][j] == 1 { //是1就继续 新建的数组 默认为0
continue
} else {
array[i][j] = array[i-1][j] + array[i][j-1]
}
}
}
return array[m-1][n-1]
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.4 MB, 在所有 Go 提交中击败了49.62%的用户
最小路径和 #
给定一个包含非负整数的 *m* x *n* 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
**说明:**每次只能向下或者向右移动一步。

输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
func minPathSum(grid [][]int) int {
m,n:=len(grid),len(grid[0])
for i:=1;i<m;i++{ //从第二个行元素开始,后面的都等于前面的和
grid[i][0]=grid[i][0]+grid[i-1][0]
}
for j:=1;j<n;j++{ //从第二个列元素开始,后面的都等于前面的和
grid[0][j]=grid[0][j]+grid[0][j-1]
}
for i:=1;i<m;i++{
for j:=1;j<n;j++{ //那个小就让他等于那个
if grid[i][j]+grid[i-1][j]<=grid[i][j]+grid[i][j-1]{
grid[i][j]=grid[i][j]+grid[i-1][j]
}else{
grid[i][j]=grid[i][j]+grid[i][j-1]
}
}
}
return grid[m-1][n-1]
}
执行用时:8 ms, 在所有 Go 提交中击败了21.87%的用户
内存消耗:3.7 MB, 在所有 Go 提交中击败了99.94%的用户
删除排序链表中的重复元素2 #
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。

输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil { //排除为空
return head
}
var pre *ListNode
cur := &ListNode{-1, head} //亮点在于创建头节点 防止第一第二结点重复
pre = cur
for pre.Next != nil && pre.Next.Next != nil {
if pre.Next.Val == pre.Next.Next.Val { //如果相等了 找一个值 一个一个剔除
x := pre.Next.Val
for pre.Next != nil && pre.Next.Val == x {
pre.Next = pre.Next.Next
}
} else {
pre = pre.Next
}
}
return cur.Next
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.9 MB, 在所有 Go 提交中击败了100.00%的用户
翻转链表2 #
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
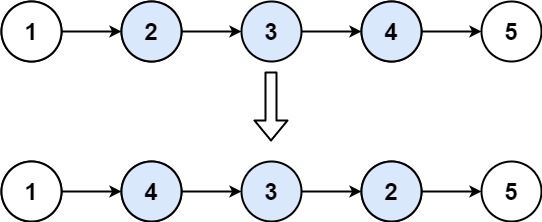
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
func reverseBetween(head *ListNode, left, right int) *ListNode {
pre:=&ListNode{-1,head}//设置头结点,防止left为1干扰
head=pre
for i:=0;i<left-1;i++{
pre=pre.Next
}
cur:=pre.Next
for i:=left;i<right;i++{ //翻转链表 直到 right
next:=cur.Next
cur.Next=next.Next
next.Next=pre.Next
pre.Next=next
}
return head.Next
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了72.69%的用户
分割链表 #
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
func partition(head *ListNode, x int) *ListNode {
large:=&ListNode{}
small:=&ListNode{}
cur:=small
pre:=large
for head!=nil{
if head.Val<x{
small.Next=head
small=small.Next
}else{
large.Next=head
large=large.Next
}
head=head.Next
}
large.Next=nil
small.Next=pre.Next
return cur.Next
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.3 MB, 在所有 Go 提交中击败了76.15%的用户
简化路径 #
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,’//’)都被视为单个斜杠 ‘/’ 。 对于此问题,任何其他格式的点(例如,’…’)均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
始终以斜杠 ‘/’ 开头。 两个目录名之间必须只有一个斜杠 ‘/’ 。 最后一个目录名(如果存在)不能 以 ‘/’ 结尾。 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 ‘.’ 或 ‘..’)。 返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
func simplifyPath(path string) string {
stack:=[]string{} //利用栈的思想
for _,c:=range strings.Split(path,"/"){ //将path按照/ 分开
if c==".."{ //表示要出栈
n:=len(stack)
if n>0{ //一定要大于0,否则会报错
stack=stack[:n-1] //出栈
}
}else if c=="."||c==""{ //“”这个必须 split划分后,左右都有“”
continue //出现这两个不入栈
}else{
stack=append(stack,c) //入栈
}
}
ss:="/"+strings.Join(stack,"/") //前面拼接上/
return ss
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.9 MB, 在所有 Go 提交中击败了86.63%的用户
矩阵置零 #
给定一个 *m* x *n* 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法**。**

输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
func setZeroes(matrix [][]int) { //用首行首列去记录0值
m:=len(matrix)
n:=len(matrix[0])
x:=false //代表首行没有0
y:=false //代表首列没有0
for i:=0;i<m;i++{ //判断首列有没有0
if matrix[i][0]==0{
y=true
}
}
for i:=0;i<n;i++{ //判断首行有没有0
if matrix[0][i]==0{
x=true
}
}
for i:=1;i<m;i++{
for j:=1;j<n;j++{
if matrix[i][j]==0{
matrix[0][j]=0 //首行==0 标记
matrix[i][0]=0 //首列==0
}
}
}
for i:=1;i<m;i++{ //除第一行外,其他行如果有0 则 这行为0
if matrix[i][0]==0{
for j:=0;j<n;j++{
matrix[i][j]=0
}
}
}
for j:=1;j<n;j++{ //除第一列外,其他列如果有0,则这列为0
if matrix[0][j]==0{
for i:=0;i<m;i++{
matrix[i][j]=0
}
}
}
if x { //如果首行有0
for i:=0;i<n;i++{
matrix[0][i]=0
}
}
if y { //如果首列有0
for i:=0;i<m;i++{
matrix[i][0]=0
}
}
}
执行用时:12 ms, 在所有 Go 提交中击败了70.85%的用户
内存消耗:6.2 MB, 在所有 Go 提交中击败了35.54%的用户
搜索二维矩阵 #
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。

输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
func searchMatrix(matrix [][]int, target int) bool {
m:=len(matrix)
n:=len(matrix[0])
for i:=0;i<m;i++{
if matrix[i][0]==target{ //判断每行第一个
return true
}
if (i+1)<m&&matrix[i][0]<target&&matrix[i+1][0]>target{ //看target是不是在这个区间
for j:=1;j<n;j++{ //在的话进去找一下
if matrix[i][j]==target{
return true
}
}
}
if matrix[i][0]>target{ //节省时间
break
}
}
for i,j:=m-1,0;j<n&&matrix[m-1][0]<target;j++{ //考虑只有一行,或最后一行的情况
if matrix[i][j]==target{
return true
}
}
return false
}
执行用时:4 ms, 在所有 Go 提交中击败了17.52%的用户
内存消耗:2.5 MB, 在所有 Go 提交中击败了99.83%的用户
func searchMatrix(matrix [][]int, target int) bool { //两次二分法 调用了函数 背吧
row := sort.Search(len(matrix), func(i int) bool { return matrix[i][0] > target }) - 1
if row < 0 { //只有一行
return false
}
col := sort.SearchInts(matrix[row], target)
return col < len(matrix[row]) && matrix[row][col] == target
}
颜色分类 #
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
必须在不使用库的sort函数的情况下解决这个问题。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
func sortColors(nums []int) { //分别给他计数,然后修改 扫描了两趟 不是最优
x,y,z:=0,0,0
for _,c:=range nums{
if c==0{
x++
}
if c==1{
y++
}
if c==2{
z++
}
}
for i:=0;i<x;i++{
nums[i]=0
}
for i:=x;i<x+y;i++{
nums[i]=1
}
for i:=x+y;i<x+y+z;i++{
nums[i]=2
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了62.46%的用户
//双指针
func sortColors(nums []int) { //在头跟尾设置双指针,去交换0,2
p,q:=0,len(nums)-1
for i:=0;i<=q;i++{
for ; i <= q && nums[i] == 2; q-- { //一直换到i,不是2
nums[i], nums[q] = nums[q], nums[i]
}
if nums[i]==0 { //跟前面换
nums[i],nums[p]=nums[p],nums[i]
p++
}
}
}
组合 #
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
//知道要用回溯法 但第一次还是没写出来
var marry [][]int //要设置全局变量
func combine(n int, k int) [][]int {
marry=[][]int{} //不写这个会报错,
if n<k|| n<=0||k<=0{
return marry
}
ss:=make([]int,0)
comb(n,k,1,ss)
return marry
}
func comb(n int,k int,start int,ss []int){
if len(ss)==k{
cc:=make([]int,k)
copy(cc,ss) //这里不复制会改变值
marry=append(marry,cc)
return
}
if n-start+len(ss)+1<k { //剪枝
return
}
for i:=start;i<n+1;i++{
ss=append(ss,i)
comb(n,k,i+1,ss)
ss=ss[:len(ss)-1] //回退
}
}
执行用时:8 ms, 在所有 Go 提交中击败了64.68%的用户
内存消耗:6 MB, 在所有 Go 提交中击败了97.55%的用户
子集 #
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
var marry [][]int
func subsets(nums []int) [][]int { //回溯
marry = [][]int{}
ss := []int{}
backtraceing(nums, 0, ss)
return marry
}
func backtraceing(nums []int, start int, ss []int) {
cc := make([]int, len(ss))
copy(cc, ss)
marry = append(marry, cc)
for i := start; i < len(nums); i++ {
ss = append(ss, nums[i])
backtraceing(nums, i+1, ss)
ss = ss[:len(ss)-1]
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了50.39%的用户
单词搜索 #
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
var find =true
func exist(board [][]byte, word string) bool { //回溯法
m, n := len(board), len(board[0])
find = false //先让它为false
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
if board[i][j] == word[0] { //找到它开始回溯
blacktracking(i, j, board, word, 0)
}
}
}
return find
}
func blacktracking(i int, j int, board [][]byte, word string, index int) {
if i < 0 || i > len(board)-1 || j < 0 || j > len(board[0])-1 || find || board[i][j] == '#' || board[i][j] != word[index] { //如果board[i][j] == '#'证明来过
return
}
if index == len(word)-1 { //发现长度一样,证明找到了 改变全局变量find
find = true
return
}
tmp := board[i][j]
board[i][j] = '#' //做记号,证明来过
blacktracking(i+1, j, board, word, index+1)
blacktracking(i-1, j, board, word, index+1)
blacktracking(i, j+1, board, word, index+1)
blacktracking(i, j-1, board, word, index+1)
board[i][j] = tmp //回退
}
执行用时:60 ms, 在所有 Go 提交中击败了91.84%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了94.58%的用户
删除有序数组中的重复项2 #
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
func removeDuplicates(nums []int) int { //双指针
n:=len(nums)
p:=0
x:=1 //计数
c:=-1
for i:=0;i<n;i++{ //从头往后遍历
if nums[i]!=c{ //不相等
x=1 //X计数1
nums[p]=nums[i] //赋值 巧妙在 刚开始 nums[0]=nums[0]
p++ //p挪到下一个位置
c=nums[i] //c记录新值
continue //很重要让他继续
}
if nums[i]==c&&x<2{ //相等且x<2,则赋值,移位
nums[p]=nums[i]
p++
x++
continue //也要跳出去
} //如果相等且x>=2时 不做任何操作
}
return p
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.9 MB, 在所有 Go 提交中击败了61.72%的用户
func removeDuplicates(nums []int) int { //双指针
n:=len(nums)
if n<=2{
return n
}
index:=2
for i:=2;i<n;i++{
if nums[i]!=nums[index-2]{ //2!=0 没两个一看 也挺巧妙
nums[index]=nums[i]
index++
}
}
return index
}
搜索旋转排序数组2 #
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为 [4,5,6,6,7,0,1,2,4,4] 。
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果 nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
你必须尽可能减少整个操作步骤。
示例 1:
输入:nums = [2,5,6,0,0,1,2], target = 0
输出:true
func search(nums []int, target int) bool {
n := len(nums)
l, r := 0, n-1
if nums[l] == target || nums[r] == target {
return true
}
for l < r { //n>=2时适用
mid := (l + r) / 2
if nums[mid] == target || nums[r] == target || nums[l] == target {
return true
}
if nums[mid] == nums[l] { //难以判断在左还是右,去重
l = l + 1
continue
}
if nums[mid] > nums[l] { //证明左边不存在比mid还大的
if nums[mid] > target && nums[l] < target { //证明在左边
r = mid - 1
} else { //nums[mid]<target nums[l]<target 证明在右边
l = mid + 1
}
} else { //nums[mid]<nums[l]
if nums[mid] < target && target < nums[r] {
l = mid + 1
} else {
r = mid - 1
}
}
}
return false
}
执行用时:4 ms, 在所有 Go 提交中击败了84.94%的用户
内存消耗:3 MB, 在所有 Go 提交中击败了49.84%的用户
格雷编码 #
n 位格雷码序列 是一个由 2n 个整数组成的序列,其中: 每个整数都在范围 [0, 2n - 1] 内(含 0 和 2n - 1) 第一个整数是 0 一个整数在序列中出现 不超过一次 每对 相邻 整数的二进制表示 恰好一位不同 ,且 第一个 和 最后一个 整数的二进制表示 恰好一位不同 给你一个整数 n ,返回任一有效的 n 位格雷码序列 。
示例 1:
输入:n = 2
输出:[0,1,3,2]
解释:
[0,1,3,2] 的二进制表示是 [00,01,11,10] 。
- 00 和 01 有一位不同
- 01 和 11 有一位不同
- 11 和 10 有一位不同
- 10 和 00 有一位不同
[0,2,3,1] 也是一个有效的格雷码序列,其二进制表示是 [00,10,11,01] 。
- 00 和 10 有一位不同
- 10 和 11 有一位不同
- 11 和 01 有一位不同
- 01 和 00 有一位不同
//背吧
/**
关键是搞清楚格雷编码的生成过程, G(i) = i ^ (i/2);
如 n = 3:
G(0) = 000,
G(1) = 1 ^ 0 = 001 ^ 000 = 001
G(2) = 2 ^ 1 = 010 ^ 001 = 011
G(3) = 3 ^ 1 = 011 ^ 001 = 010
G(4) = 4 ^ 2 = 100 ^ 010 = 110
G(5) = 5 ^ 2 = 101 ^ 010 = 111
G(6) = 6 ^ 3 = 110 ^ 011 = 101
G(7) = 7 ^ 3 = 111 ^ 011 = 100
**/
func grayCode(n int) []int {
c:=make([]int,1<<n) //1*z^n
for i:=0;i<1<<n;i++{
c[i]=i^(i/2)
}
return c
}
执行用时:12 ms, 在所有 Go 提交中击败了28.19%的用户
内存消耗:6.7 MB, 在所有 Go 提交中击败了62.16%的用户
子集2 #
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]

var marry [][]int
func subsetsWithDup(nums []int) [][]int { //回溯法
marry = [][]int{}
ss := []int{}
sort.Ints(nums)
backtraceing(nums, 0, ss)
return marry
}
func backtraceing(nums []int, start int, ss []int) {
cc := make([]int, len(ss))
copy(cc, ss)
marry = append(marry, cc)
for i := start; i < len(nums); i++ {
if i > start && nums[i] == nums[i-1] { //看了一遍全过程 还是不能理解
continue
}
ss = append(ss, nums[i])
backtraceing(nums, i+1, ss)
ss = ss[:len(ss)-1]
}
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.3 MB, 在所有 Go 提交中击败了49.06%的用户
var marry [][]int
func subsetsWithDup(nums []int) [][]int { //回溯法
marry = [][]int{}
ss := []int{}
used := make([]bool, len(nums))
sort.Ints(nums)
backtraceing(nums, 0, ss, used)
return marry
}
func backtraceing(nums []int, start int, ss []int, used []bool) {
cc := make([]int, len(ss))
copy(cc, ss)
marry = append(marry, cc)
for i := start; i < len(nums); i++ {
if i > 0 && nums[i] == nums[i-1] && used[i-1] == false {
continue
}
ss = append(ss, nums[i])
used[i] = true
backtraceing(nums, i+1, ss, used)
used[i] = false
ss = ss[:len(ss)-1]
}
}
解码方法 #
一条包含字母 A-Z 的消息通过以下映射进行了 编码 :
'A' -> "1"
'B' -> "2"
...
'Z' -> "26"
要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例
如,"11106" 可以映射为:
"AAJF" ,将消息分组为 (1 1 10 6)
"KJF" ,将消息分组为 (11 10 6)
注意,消息不能分组为 (1 11 06) ,因为 "06" 不能映射为 "F" ,这是由于 "6" 和 "06" 在映射中并不等价。
给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。
题目数据保证答案肯定是一个 32 位 的整数。
输入:s = "226"
输出:3
解释:它可以解码为 "BZ" (2 26), "VF" (22 6), 或者 "BBF" (2 2 6) 。
/**
上楼梯的复杂版?
如果连续的两位数符合条件,就相当于一个上楼梯的题目,可以有两种选法:
1.一位数决定一个字母
2.两位数决定一个字母
就相当于dp(i) = dp[i-1] + dp[i-2];
如果不符合条件,又有两种情况
1.当前数字是0:
不好意思,这阶楼梯不能单独走,
dp[i] = dp[i-2]
2.当前数字不是0
不好意思,这阶楼梯太宽,走两步容易扯着蛋,只能一个一个走
dp[i] = dp[i-1];
*/
func numDecodings(s string) int {
n:=len(s)
if n==0||s[0]=='0'{
return 0
}
marry:=make([]int,n+1) //记录用的数组
marry[0]=1
for i:=0;i<n;i++{
if s[i]=='0'{
marry[i+1]=0
}else{
marry[i+1]=marry[i]
}
if i>0&&(s[i-1]=='1'||(s[i-1]=='2'&&s[i]<='6')){
marry[i+1]=marry[i+1]+marry[i-1] //当不存在0时f(n+1)=f(n)+f(n-1)
}
}
return marry[n]
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.9 MB, 在所有 Go 提交中击败了54.79%的用户
反转链表2 #
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。

输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
func reverseBetween(head *ListNode, left, right int) *ListNode {
pre:=&ListNode{-1,head}//设置头结点,防止left为1干扰
head=pre
for i:=0;i<left-1;i++{
pre=pre.Next
}
cur:=pre.Next
for i:=left;i<right;i++{ //翻转链表 直到 right
next:=cur.Next
cur.Next=next.Next
next.Next=pre.Next
pre.Next=next
}
return head.Next
}
复原IP地址 #
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “192.168@1.1” 是 无效 IP 地址。 给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 ‘.’ 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
示例 1:
输入:s = "25525511135"
输出:["255.255.11.135","255.255.111.35"]
var marry []string //全局变量,如果传入 要改指针
func restoreIpAddresses(s string) []string {
marry=[]string{}
ss:=[]string{} //定义队列数组,存放合法的字符串
backtraceing(s,0,ss)
return marry
}
func backtraceing(s string,start int,ss []string){ //搜索的起始位置,还有
if start==len(s)&&len(ss)==4{ //证明满足条件
tmpstring:=strings.Join(ss,".") //用.连接ss中的字段path[0]+"."+path[1]+"."+...
marry=append(marry,tmpstring)
}
for i:=start;i<len(s);i++{
ss=append(ss,s[start:i+1])
if i-start<3&&len(ss)<=4&&isture(s,start,i){ //长度不能超过3 len(ss)最多四段 且满足条件
backtraceing(s,i+1,ss)
}
ss=ss[:len(ss)-1] //会退
}
}
func isture(s string,start int,end int)bool{ //判断是否满足条件
checkint,_:=strconv.Atoi(s[start:end+1]) //这几个字符串处理函数要熟记
if start!=end&&s[start]=='0'{ //判断01这种情况
return false
}
if checkint>255{
return false
}
return true
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.2 MB, 在所有 Go 提交中击败了28.67%的用户
不同的二叉搜索树2 #
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。

输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func generateTrees(n int) []*TreeNode {
return backtraceing(1,n)
}
func backtraceing(l, r int) []*TreeNode {
if l > r {
return []*TreeNode{nil}
}
allTrees := []*TreeNode{}
// 枚举可行根节点
for i := l; i <= r; i++ {
// 获得所有可行的左子树集合
leftTrees := backtraceing(l, i - 1)
// 获得所有可行的右子树集合
rightTrees := backtraceing(i + 1, r)
// 从左子树集合中选出一棵左子树,从右子树集合中选出一棵右子树,拼接到根节点上
for _, left := range leftTrees {
for _, right := range rightTrees {
currTree := &TreeNode{i, nil, nil}
currTree.Left = left
currTree.Right = right
allTrees = append(allTrees, currTree)
}
}
}
return allTrees
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:4.2 MB, 在所有 Go 提交中击败了84.20%的用户
不同的二叉搜索树 #
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
输入:n = 3
输出:5

func numTrees(n int) int {
dp:=make([]int,n+1)
dp[0]=1
dp[1]=1
for i:=2;i<=n;i++{//从第二个开始遍历到n
for j:=1;j<=i;j++{//从第一个开始,循环往上加G(i)=f(1)+...+f(i)
dp[i]+=dp[j-1]*dp[i-j]//f[i]=G[i-1]*G[n-i]
}
}
return dp[n]
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:1.8 MB, 在所有 Go 提交中击败了71.60%的用户
验证二叉搜索树 #
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。

输入:root = [2,1,3]
输出:true
func isValidBST(root *TreeNode) bool {
// 二叉搜索树也可以是空树
if root == nil {
return true
}
// 由题目中的数据限制可以得出min和max
return check(root,math.MinInt64,math.MaxInt64)
}
func check(node *TreeNode,min,max int64) bool {
if node == nil {
return true
}
if min >= int64(node.Val) || max <= int64(node.Val) {
return false
}
// 分别对左子树和右子树递归判断,如果左子树和右子树都符合则返回true
return check(node.Right,int64(node.Val),max) && check(node.Left,min,int64(node.Val))
}
// 中序遍历解法
func isValidBST(root *TreeNode) bool {
// 保存上一个指针
var prev *TreeNode
var travel func(node *TreeNode) bool
travel = func(node *TreeNode) bool {
if node == nil {
return true
}
leftRes := travel(node.Left)
// 当前值小于等于前一个节点的值,返回false
if prev != nil && node.Val <= prev.Val {
return false
}
prev = node
rightRes := travel(node.Right)
return leftRes && rightRes
}
return travel(root)
}
var pre *TreeNode //自己写的 不知道是什么问题,单独跑 和提交结果不一致 应该是网bug
func isValidBST(root *TreeNode) bool {
if root.Left==nil&&root.Right==nil{
return true
}
return trave(root)
}
func trave(node *TreeNode)bool{
if node==nil{
return true
}
leftRes:=trave(node.Left)
if pre!=nil&&node.Val<=pre.Val{
return false
}
pre=node
rightRes:=trave(node.Right)
return leftRes&&rightRes
}
交错字符串 #
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。
两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干非空子字符串:
s = s1 + s2 + ... + sn
t = t1 + t2 + ... + tm
|n - m| <= 1
交错 是 s1 + t1 + s2 + t2 + s3 + t3 + ... 或者 t1 + s1 + t2 + s2 + t3 + s3 + ...
注意:a + b 意味着字符串 a 和 b 连接。

输入:s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
输出:true

func isInterleave(s1 string, s2 string, s3 string) bool {
n1, n2, n3 := len(s1), len(s2), len(s3)
if n3 != n1+n2 {
return false
}
var marry = make([][]bool, n1+1) //声明一个初始切片,都为false
for i := 0; i < n1+1; i++ {
marry[i] = make([]bool, n2+1)
}
marry[0][0]=true
for i:=0;i<n1+1;i++{
for j:=0;j<n2+1;j++{
if i>0{
if s3[i+j-1]==s1[i-1]&&marry[i-1][j]==true{
marry[i][j]=true
}
}
if j>0{
if s3[i+j-1]==s2[j-1]&&marry[i][j-1]==true{ //相等且左边的为true
marry[i][j]=true
}
}
}
}
return marry[n1][n2]
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了82.45%的用户
恢复二叉搜索树 #
给你二叉搜索树的根节点 root ,该树中的 恰好 两个节点的值被错误地交换。请在不改变其结构的情况下,恢复这棵树 。

输入:root = [1,3,null,null,2]
输出:[3,1,null,null,2]
解释:3 不能是 1 的左孩子,因为 3 > 1 。交换 1 和 3 使二叉搜索树有效。
func recoverTree(root *TreeNode) { //这里的指针操作值得学习
var pre *TreeNode = nil
var first *TreeNode = nil
var second *TreeNode = nil
dfs(root, &pre, &first, &second)
// 交换两个逆序节点
first.Val, second.Val = second.Val, first.Val
}
func dfs(root *TreeNode, pre **TreeNode, first **TreeNode, second **TreeNode) {
if root == nil {
return
}
dfs(root.Left, pre, first, second)
// 找到两个逆序节点
if (*pre) != nil && root.Val < (*pre).Val {
if (*first) == nil {
(*first) = (*pre)
}
(*second) = root
}
(*pre) = root
dfs(root.Right, pre, first, second)
}
var resd = make([]*TreeNode, 0)//控制台可行,点提交不行 很烦
func recoverTree(root *TreeNode) {
if root == nil {
return
}
midOrder(root)
p, q := root, root
pre := true
for i := 0; i < len(resd)-1; i++ {
if resd[i].Val > resd[i+1].Val && pre == true {
p = resd[i]
q = resd[i+1]
pre = false
} else if resd[i].Val > resd[i+1].Val && pre == false {
q = resd[i+1]
}
}
p.Val, q.Val = q.Val, p.Val
}
func midOrder(root *TreeNode) { //中序遍历,将根指针插入resd数组
if root != nil {
midOrder(root.Left)
resd = append(resd, root)
midOrder(root.Right)
}
}
func recoverTree(root *TreeNode) { //go语言遇到这种题直接死 没看懂
stack := []*TreeNode{}
var x, y, pred *TreeNode
for len(stack) > 0 || root != nil {
for root != nil {
stack = append(stack, root)
root = root.Left
}
root = stack[len(stack)-1]
stack = stack[:len(stack)-1]
if pred != nil && root.Val < pred.Val {
y = root
if x == nil {
x = pred
} else {
break
}
}
pred = root
root = root.Right
}
x.Val, y.Val = y.Val, x.Val
}
func recoverTree(root *TreeNode) { //笨办法
marry:=[]int{} //先定义一个记录数组
var midOrder func(root *TreeNode) //定义一个内置函数,注意格式
midOrder=func(root *TreeNode){
if root!=nil{
midOrder(root.Left)
marry=append(marry,root.Val) //将里面的值中序遍历放入数组
midOrder(root.Right)
}
}
midOrder(root) //记住定义的函数要使用
x,y:=findmarry(marry) //找到两个不合格的数
recovermarry(x,y,2,root) //在树里面去找,找到后交换数据
}
func findmarry(marry []int)(x,y int){
find:=true
for i:=0;i<len(marry)-1;i++{
if marry[i]>marry[i+1]&&find==true{ //代表找到了第一个
x=marry[i]
y=marry[i+1] //这里要注意,例如1,3,2,4 只有一次满足
find=false
}else if marry[i]>marry[i+1]&&find==false{ //找到第二个
y=marry[i+1] //这里是i+1, 1,4,3,2,5
}
}
return x,y
}
func recovermarry(x int,y int, count int,root *TreeNode){//去树里寻找
if root!=nil{
recovermarry(x,y,count,root.Left)
if root.Val==x||root.Val==y{
if root.Val==x{
root.Val=y
}else{
root.Val=x
}
count--
if count==0{ //剪枝
return
}
}
recovermarry(x,y,count,root.Right)
}
}
执行用时:12 ms, 在所有 Go 提交中击败了52.23%的用户
内存消耗:6.2 MB, 在所有 Go 提交中击败了19.05%的用户
困难 #
寻找两个正序数组的中位数 #
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
func findMedianSortedArrays(nums1 []int, nums2 []int) float64 {
var i,j,m,n,u int
m=len(nums1)
n=len(nums2)
if n<m {
nums1,nums2=nums2,nums1
m,n=n,m
}
var x float64
nums3:=make([]int,n+m)
i,u=0,0
for i<m || j<n {
if i==m{
for j<n{
nums3[u]=nums2[j]
u++
j++
}
}else if j==n{
for i<m{
nums3[u]=nums1[i]
i++
u++
}
}else if i<m||j<n {
if nums1[i] <= nums2[j] {
nums3[u] = nums1[i]
println(nums3[u])
u++
i++
} else {
nums3[u] = nums2[j]
println(nums3[u])
u++
j++
}
}
}
var a,b,y int
a=(m+n)%2
b=(m+n)/2
if a==0{
x=(float64(nums3[b-1]+nums3[b]))/2
}else {
b=(m+n)/2
x=float64(nums3[b])
println(y)
}
return x
}
正则表达式匹配 #
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
‘.’ 匹配任意单个字符 ‘*’ 匹配零个或多个前面的那一个元素 所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
func isMatch(s string, p string) bool {
if len(p) == 0 { //排除p==0的情况
if len(s) != 0 {
return false
}
return true
}
if len(s) == 0 { //排除S等于0的情况
if len(p) == 0 {
return false
}
for i := 0;i < len(p); { //P不等于0
if p[i] != '*' { //'*' 匹配零个或多个前面的那一个元素
if i+1 < len(p) && p[i+1] == '*'{
i+=2 //a* 相当于没有 跳到后面检查
continue
}
return false
}else { //如果p[i] =='*' return true
return true
}
}
return true
}
ss, pp := s[0], p[0]
if ss == pp || pp == '.' {
if len(p) == 1 {
return isMatch(s[1:], p[1:])
} else {
if p[1] == '*' {
match := isMatch(s, p[2:]) // p[1] == '*' 前面可以抵消 返回后面再查一遍
if match {
return true
}
match = isMatch(s[1:], p) //确保第一个匹配 'aa' 'a*'
if match {
return true
}
} else { //都没有问题 s,p缩短一位
return isMatch(s[1:], p[1:])
}
}
} else { //ss != pp || pp != '.'
if len(p) == 1 {
return false
} else {
if p[1] == '*' {
return isMatch(s, p[2:])
}
}
}
return false
}
执行用时:12 ms, 在所有 Go 提交中击败了15.89%的用户
内存消耗:2.1 MB, 在所有 Go 提交中击败了94.79%的用户
合并K个生序链表 #
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
type ListNode struct {
Val int
Next *ListNode
}
func mergeKLists(lists []*ListNode) *ListNode {
var p, q, he *ListNode
if len(lists) == 0 {
return p
}
head := &ListNode{Val: 100000, Next: lists[0]}
for i := 1; i < len(lists); i++ {
he = head //始终操作第一个数组
p = head.Next
q = lists[i] //q逐个代表后面的数组 插入第一个数组中
for q != nil && p != nil { //和正常两个链表合并一样
if p.Val <= q.Val {
he.Next = p
he = he.Next
p = p.Next
} else {
he.Next = q
he = he.Next
q = q.Next
}
}
if q != nil {
he.Next = q
}
if p != nil {
he.Next = p
}
}
return head.Next
}
func main() {
var lists = [][]int{
{1, 4, 5},
{1, 3, 4},
{2, 6},
}
var tt []*ListNode //定义指针数组
for i := 0; i < len(lists); i++ { //逐个遍历生成指链表
head := &ListNode{Val: lists[i][0]}
tail := head
for j := 1; j < len(lists[i]); j++ {
head.Next = &ListNode{Val: lists[i][j]}
head = head.Next
}
tt = append(tt, tail) //插入指针数组
}
println(tt[0].Val)
x := mergeKLists(tt)
for x != nil {
print(x.Val)
x = x.Next
}
}
执行用时:104 ms, 在所有 Go 提交中击败了28.10%的用户
内存消耗:5.3 MB, 在所有 Go 提交中击败了54.40%的用户
K个一组翻转链表 #
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
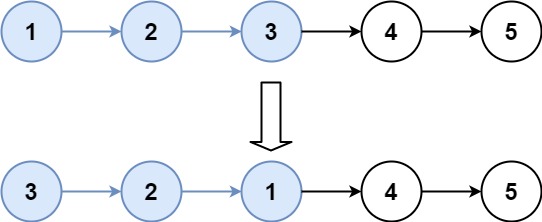
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
func reverselist(head *ListNode) (l *ListNode, r *ListNode) {
var p, q, m *ListNode //翻转函数,输入123,返回321 的头尾指针
p = head
q = head.Next
m = q.Next
if m == nil {
q.Next = p
p.Next = nil
return q, p
}
for q != nil {
q.Next = p
p = q
q = m
if m.Next != nil {
m = m.Next
} else {
q.Next = p
break
}
}
head.Next = nil
return q, head
}
func reverseKGroup(head *ListNode, k int) *ListNode {
var pp, qq, h, l, r, left, right *ListNode
i := 1
if k == 1 {
return head
}
pp = head
qq = pp
for pp.Next != nil {
pp = pp.Next
i++
if i == k { //相等了就调用上面函数翻转一下
i = 1
h = pp
pp = pp.Next
h.Next = nil
l, r = reverselist(qq)
if left == nil && right == nil {
left = l
right = r
} else {
right.Next = l //首尾相接
right = r
}
qq = pp
if pp == nil {
break
}
}
}
right.Next = qq //接上剩余部分
return left
}
执行用时:4 ms, 在所有 Go 提交中击败了90.01%的用户
内存消耗:3.6 MB, 在所有 Go 提交中击败了99.95%的用户
串联所有单词的子串 #
给定一个字符串 s 和一些 长度相同 的单词 words 。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符 ,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
//此方法可以得到答案 ,但是超时了
func findblock(s []string, words []string, ) bool {
wordss := make([]bool, 0)
for a := 0; a < len(words); a++ { //给words加一个标签 ,遍历到就改变
wordss = append(wordss, false)
}
b := 0
for i := 0; i < len(s); i++ {
for j := 0; j < len(words); j++ {
if s[i] == words[j] && wordss[j] == false { //遍历到就改变
wordss[j] = true
b++ //计数加一
break
}
}
}
if b == len(words) { //计数等于len(words)长度 证明全部遍历过了
return true
} else {
return false
}
}
func findSubstring(s string, words []string) []int {
c := make([]int, 0)
blocklen := len(words) * len(words[0]) //滑块长度
for i := 0; i < len(s)-blocklen+1; i++ {
s1 := s[i : i+blocklen] //滑块
s2 := make([]string, 0, len(words))
for j := 0; j < len(s1)-len(words[0])+1; {
s2 = append(s2, s1[j:j+len(words[0])]) //将滑块分块
j += len(words[0])
}
if findblock(s2, words) { //匹配函数
c = append(c, i) //匹配成功将i 加入
}
}
return c
}
//修改版
func findblock(s []string, wordsreceive map[string]int) bool {
wordsreceive2 := make(map[string]int, 0)
falge := true
for i := 0; i < len(s); i++ {
if a, ok := wordsreceive[s[i]]; ok { //如果查到的话
if b, ok := wordsreceive2[s[i]]; ok {
if b < a { //如果查到了 但b<a去掉重复掉
wordsreceive2[s[i]] = b + 1
} else {
falge = false
break
}
} else { //第一次肯定查不到
wordsreceive2[s[i]] = 1 //插入进去
}
} else {
falge = false //没查到
break
}
}
return falge
}
func findSubstring(s string, words []string) []int {
c := make([]int, 0)
blocklen := len(words) * len(words[0]) //滑块长度
wordsreceive := make(map[string]int, 0) //创建一个字典,出现相同字典+1
for _, bb := range words {
wordsreceive[bb] = wordsreceive[bb] + 1
println(wordsreceive[bb])
}
for i := 0; i < len(s)-blocklen+1; i++ {
s1 := s[i : i+blocklen] //滑块
s2 := make([]string, 0, len(words))
for j := 0; j < len(s1)-len(words[0])+1; {
s2 = append(s2, s1[j:j+len(words[0])]) //将滑块分块
j += len(words[0])
}
if findblock(s2, wordsreceive) { //匹配函数
c = append(c, i) //匹配成功将i 加入
}
}
return c
}
执行用时:56 ms, 在所有 Go 提交中击败了46.46%的用户
内存消耗:7.2 MB, 在所有 Go 提交中击败了31.31%的用户
最长有效括号 #
给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
type Stack struct { //栈结构
size int
top int
data []int
}
func max(x, y int) int { //输出最大值函数
if x > y {
return x
}
return y
}
func longestValidParentheses(s string) int {
s1 := Stack{ //初始化栈
size: len(s),
top: -1,
data: make([]int, len(s)+1),
}
length := 0
maxlength := 0
s1.top = 0
s1.data[s1.top] = -1 //里面输入-1
for m, a := range s { //遍历S
if string(a) == "(" { //( 入栈
s1.top++
s1.data[s1.top] = m
} else { //) 先出栈
s1.top--
if s1.top == -1 { //如果栈为空 把 m放进去 新的开始
s1.top++
s1.data[s1.top] = m
} else { //栈不为空 得到length 上面输入-1的原因
length = m - s1.data[s1.top]
maxlength = max(length, maxlength) //得到最大值
}
}
}
return maxlength
}
执行用时:0 ms, 在所有 Go 提交中击败了100.00%的用户
内存消耗:2.8 MB, 在所有 Go 提交中击败了83.89%的用户
解数独 #
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图) 数独部分空格内已填入了数字,空白格用 ‘.’ 表示。


func isvalid(row int, col int, k byte, borad [][]byte) bool {
for i := 0; i < 9; i++ { //判断行是否重复
if borad[row][i] == k {
return false
}
}
for j := 0; j < 9; j++ { //判断列是否重复
if borad[j][col] == k {
return false
}
}
Row := (row / 3) * 3
Col := (col / 3) * 3
for i := Row; i < Row+3; i++ { //判断这个小方块是否重复
for j := Col; j < Col+3; j++ {
if borad[i][j] == k {
return false
}
}
}
return true //都没有重复 返回true
}
func solve(board [][]byte) bool {
for i := 0; i < 9; i++ {
for j := 0; j < 9; j++ {
if board[i][j] != '.' { //如果为数字 继续
continue
}
for k := '1'; k <= '9'; k++ { //需要判断这行 这列 这小块有没有这个数 有的话++
if isvalid(i, j, byte(k), board) { //都没有重复
board[i][j] = byte(k) //把K 填入
if solve(board) { //找到则返回
return true
} else {
board[i][j] = '.' //没找到回溯
}
}
}
return false
}
}
return true
}
func solveSudoku(board [][]byte) {
solve(board)
}
执行用时:4 ms, 在所有 Go 提交中击败了50.56%的用户
内存消耗:2 MB, 在所有 Go 提交中击败了95.10%的用户
缺失的第一个正数 #
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
输入:nums = [1,2,0]
输出:3
func firstMissingPositive(nums []int) int {
n := len(nums)
for i := 0; i < n; i++ {
for nums[i] > 0 && nums[i] < n && nums[nums[i]-1] != nums[i] {
nums[i], nums[nums[i]-1] = nums[nums[i]-1], nums[i]
}//置换, 注意这里不是if for加了限制条件 可以把某位置的数直接放到原位置,如果是if的话 只换一次 换回来的数不一定在原位置
}
for i := 0; i < n; i++ {
if nums[i] != i+1 {
return i + 1
}
}
return n + 1
}
func firstMissingPositive(nums []int) int { //这他妈好狗
n := len(nums)
for i := 0; i < n; i++ {//将所有负数变为n+1
if nums[i] <= 0 {
nums[i] = n + 1
}
}
for i := 0; i < n; i++ {//将对应位置变为负数
num := abs(nums[i])
if num <= n {
fmt.Println(num-1)
nums[num - 1] = -abs(nums[num - 1])
}
}
for i := 0; i < n; i++ { //找正数下标加一 没变负数 证明这个没出现过
if nums[i] > 0 {
return i + 1
}
}
return n + 1
}
func abs(x int) int {
if x < 0 {
return -x
}
return x
}
接雨水 #
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
func trap(height []int) int {
c := 0
p := 1
a := 0
b := len(height) - 1
for i := 0; a < b; { //从头往后遍历
for height[i] < p { //一个一个往上增 找到定位
i++
a++
if i == b { //越界就返回
break
}
}
for height[b] < p { //找定位
b--
if b == 0 {
break
}
}
for j := a; j < b; j++ {//遍历定位中的值
if height[j] < p {
c++
}
}
p++ //p++
}
return c
}
执行用时:1444 ms, 在所有 Go 提交中击败了5.43%的用户
内存消耗:4.4 MB, 在所有 Go 提交中击败了13.87%的用户
通配符匹配 #
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 ‘?’ 和 ‘*’ 的通配符匹配。
'?' 可以匹配任何单个字符。
'*' 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
func isMatch(s string, p string) bool {
if len(p) == 0 { //len(p)=0 len(s)=0 true len(p)=0 len(s)!=0 false
if len(s) == 0 {
return true
}
return false
}
if len(s) == 0 { //len(s)=0 len(p)!=0时 排除*
for i := 0; i < len(p); {
if p[i] == '*' {
i++
} else {
return false
}
}
return true
}
ss, pp := s[0], p[0]
if ss == pp || pp == '?' {
return isMatch(s[1:], p[1:])
} else {
if pp == '*' {
if isMatch(s, p[1:]) == true {
return true
} else {
if isMatch(s[1:], p) == true {
return true
} else {
return false
}
}
} else {
return false
}
}
return true
}
用递归做的 自认为没问题 但是超时了 很烦
func isMatch(s string, p string) bool {
m, n := len(s), len(p)
pp := make([][]bool, m+1) // 制作一个二维bool数组 表示字符串s的前i个字符和p中的前j个字符是否能匹配
for i := 0; i <= m; i++ {
pp[i] = make([]bool, n+1) //?防止数组越界 默认都为false
}
pp[0][0] = true //两个空字符串匹配
for i:=1;i<=n;i++{
if p[i-1]=='*'{
pp[0][i]=true //*匹配所有字符
}else {
break //跳出for循环 从第一个开始都为* 则为true 一直到不一样
}
}
for i:=1;i<=m;i++{ //s选一 p从一选到最后 看是否匹配
for j:=1;j<=n;j++{
if p[j-1]=='*'{ //p为*号;
pp[i][j]=pp[i][j-1]||pp[i-1][j]
}else if p[j-1]=='?'|| s[i-1]==p[j-1]{ //p为? 或者这两个相等,看它前面的匹配 他就匹配
pp[i][j]=pp[i-1][j-1]
}
}
}
return pp[m][n]
}
执行用时:20 ms, 在所有 Go 提交中击败了26.35%的用户
内存消耗:6.3 MB, 在所有 Go 提交中击败了63.81%的用户
N皇后 #
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。

输入:n = 4
输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
N皇后2 #
n 皇后问题 研究的是如何将 n 个皇后放置在 n × n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。
输入:n = 4
输出:2
解释:如上图所示,4 皇后问题存在两个不同的解法。
排序序列 #
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
"123"
"132"
"213"
"231"
"312"
"321"
给定 n 和 k,返回第 k 个排列。
示例 1:
输入:n = 3, k = 3
输出:"213"
示例 2:
输入:n = 4, k = 9
输出:"2314"
编辑距离 #
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
func minDistance(word1 string, word2 string) int {
m,n:=len(word1),len(word2)
marry :=make([][]int,m+1)
for i:=range marry{
marry[i]=make([]int,n+1)
}
--------------------------------------------------------------
marry :=[][]int{}
//arry:=make([]int,n+1) 如果放到外面,它会改变所有地方因为指针引用
for i:=0;i<m+1;i++{
arry:=make([]int,n+1)
marry=append(marry,arry)
}
--------------------------------------------------------------
for i:=0;i<m+1;i++{
marry[i][0]=i
}
for j:=0;j<n+1;j++{
marry[0][j]=j
}
for i:=1;i<m+1;i++{
for j:=1;j<n+1;j++{
if word1[i-1]==word2[j-1]{
marry[i][j]=marry[i-1][j-1]
}else{
marry[i][j]=minmarry(marry[i-1][j],marry[i][j-1],marry[i-1][j-1])+1
}
}
}
return marry[m][n]
}
func minmarry(a int,b int,c int)int{
if a>b{
if b>c{
return c
}else{
return b
}
}else{
if a>c{
return c
}else{
return a
}
}
}
执行用时:4 ms, 在所有 Go 提交中击败了72.50%的用户
内存消耗:5.4 MB, 在所有 Go 提交中击败了56.63%的用户
最小覆盖子串 #
给出两个字符串 s 和 t,要求在 s 中找出最短的包含 t 中所有字符的连续子串。
数据范围:0≤∣S∣,∣T∣≤100000≤∣S∣,∣T∣≤10000,保证s和t字符串中仅包含大小写英文字母
要求:进阶:空间复杂度 O(n)O(n) , 时间复杂度 O(n)O(n)
例如:
S=“XDOYEZODEYXNZ” T=“XYZ” 找出的最短子串为"YXNZ”
注意: 如果 s 中没有包含 t 中所有字符的子串,返回空字符串 “”; 满足条件的子串可能有很多,但是题目保证满足条件的最短的子串唯一。
输入:"XDOYEZODEYXNZ","XYZ"
返回值:"YXNZ"
以S="DOABECODEBANC",T="ABC"为例 初始状态:

步骤一:不断增加j使滑动窗口增大,直到窗口包含了T的所有元素,need中所有元素的数量都小于等于0,同时needCnt也是0

步骤二:不断增加i使滑动窗口缩小,直到碰到一个必须包含的元素A,此时记录长度更新结果

步骤三:让i再增加一个位置,开始寻找下一个满足条件的滑动窗口

func minWindow(S string, T string) string {
needCnt := len(T)
need := make(map[byte]int)
for _, v := range T {
need[byte(v)]++
}
i := 0 //滑动窗口左边界
left,right:=0,len(S)+1
for j, v := range S { //j,右边界
if need[byte(v)] > 0 { //如果查出来有,总数减1
needCnt = needCnt - 1
}
need[byte(v)] -= 1 //如果有,字典减1,如果没有,就设置为0
if needCnt == 0 { //步骤一,证明滑块内包含T了
for { //步骤二,增加i,排除多余元素
x := S[i]
if need[x] == 0 {
break
}
need[x] += 1
i += 1
}
if j-i < right-left { //记录结果
left,right= i,j
}
need[S[i]] += 1 //步骤三,i再增加一个位置,寻找新的满足条件的窗口
needCnt += 1
i += 1
}
}
if right>len(S){//意思就是没变化过
return ""
}
return S[left : right+1]
}