新⼿常犯的50个错误 #
https://blog.csdn.net/gezhonglei2007/article/details/52237582
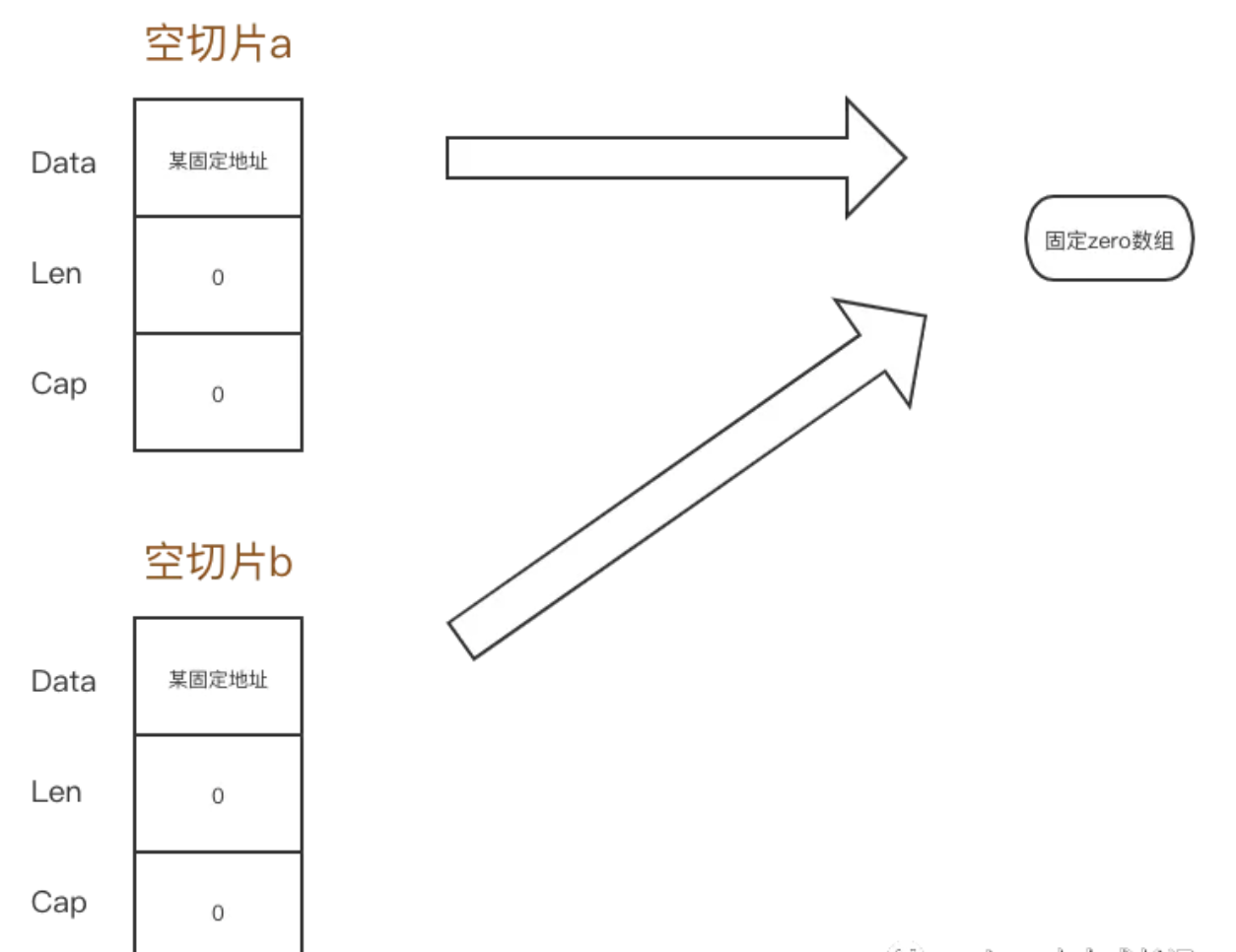
nil切⽚和空切⽚ #
- nil切片和空切片指向的地址不一样。nil空切片引用数组指针地址为0(无指向任何实际地址)
- 空切片的引用数组指针地址是有的,且固定为一个值
//切片数据结构
type SliceHeader struct {
Data uintptr //引用数组指针地址
Len int // 切片的目前使用长度
Cap int // 切片的容量
}

字符串转成byte数组,会发⽣内存拷⻉吗? #
字符串转成切片,会产生拷贝。严格来说,只要是发生类型强转都会发生内存拷贝。
有没有什么办法可以在字符串转成切片的时候不用发生拷贝呢?
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
a :="aaa"
ssh := *(*reflect.StringHeader)(unsafe.Pointer(&a))
b := *(*[]byte)(unsafe.Pointer(&ssh))
fmt.Printf("%v",b)
}
解释:
StringHeader是字符串在go的底层结构。
type StringHeader struct {
Data uintptr
Len int
}
SliceHeader是切片在go的底层结构。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 那么如果想要在底层转换二者,只需要把
StringHeader的地址强转成SliceHeader就行。那么go有个很强的包叫unsafe。- 1.
unsafe.Pointer(&a)方法可以得到变量a的地址。 - 2.
(*reflect.StringHeader)(unsafe.Pointer(&a))可以把字符串a转成底层结构的形式。 - 3.
(*[]byte)(unsafe.Pointer(&ssh))可以把ssh底层结构体转成byte的切片的指针。 - 4.再通过
*转为指针指向的实际内容。
- 1.
翻转含有中⽂、数字、英⽂字⺟的字符串 #
代码实现
package main
import"fmt"
func main() {
src := "你好abc啊哈哈"
dst := reverse([]rune(src))
fmt.Printf("%v\n", string(dst))
}
func reverse(s []rune) []rune {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
return s
}
解释
rune关键字,从golang源码中看出,它是int32的别名(-2^31 ~ 2^31-1),比起byte(-128~127),可表示更多的字符。- 由于rune可表示的范围更大,所以能处理一切字符,当然也包括中文字符。在平时计算中文字符,可用rune。
- 因此将
字符串转为rune的切片,再进行翻转,完美解决。
为什么 int8 的最大值是 127 而不是 128?
#
这是因为有符号整数的表示方式使用了二进制补码(Two’s Complement)形式。在补码表示中:
-
最高位(最左边的位)是符号位:
0表示正数或零。1表示负数。
-
数值范围:
-
对于
int8(8 位有符号整数),总共有 8 位,其中 1 位是符号位,剩下的 7 位用于表示数值。 -
正数的最大值是
01111111(二进制),即:
- 符号位
0(正数)。 - 数值部分
1111111(二进制) =127(十进制)。
- 符号位
-
因此,
int8的正数范围是0到127。 -
负数的范围是
-1到-128(通过补码表示)。
-
-
为什么不是 128?
- 如果用 8 位表示有符号整数,
128的二进制形式是10000000(二进制补码中,这是-128的表示,而不是+128)。 - 因此,
int8无法表示+128,它的最大值是127。
- 如果用 8 位表示有符号整数,
拷⻉⼤切⽚⼀定⽐⼩切⽚代价⼤吗? #
并不是,所有切片的大小相同;三个字段(一个 uintptr,两个int)。切片中的第一个字是指向切片底层数组的指针,这是切片的存储空间,第二个字段是切片的长度,第三个字段是容量。将一个 slice 变量分配给另一个变量只会复制三个机器字。所以 拷贝大切片跟小切片的代价应该是一样的。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
json包变量不加tag会怎么样? #
- 如果变量
首字母小写,则为private。无论如何不能转,因为取不到反射信息。 - 如果变量
首字母大写,则为public。不加tag,可以正常转为json里的字段,json内字段名跟结构体内字段原名一致。加了tag,从struct转json的时候,json的字段名就是tag里的字段名,原字段名已经没用。
举例
- 通过一个例子加深理解。
package main
import (
"encoding/json"
"fmt"
)
type J struct {
a string //小写无tag
b string `json:"B"` //小写+tag
C string //大写无tag
D string `json:"DD"` //大写+tag
}
func main() {
j := J {
a: "1",
b: "2",
C: "3",
D: "4",
}
fmt.Printf("转为json前j结构体的内容 = %+v\n", j)
jsonInfo, _ := json.Marshal(j)
fmt.Printf("转为json后的内容 = %+v\n", string(jsonInfo))
}
输出
转为json前j结构体的内容 = {a:1 b:2 C:3 D:4}
转为json后的内容 = {"C":"3","DD":"4"}
解释
- 结构体里定义了四个字段,分别对应
小写无tag,小写+tag,大写无tag,大写+tag。 - 转为
json后首字母小写的不管加不加tag都不能转为json里的内容,而大写的加了tag可以取别名,不加tag则json内的字段跟结构体字段原名一致。
reflect**(反射包)如何获取字段tag?为什么json包不能导出私有变量的tag**? #
tag信息可以通过反射(reflect包)内的方法获取,通过一个例子加深理解。
package main
import (
"fmt"
"reflect"
)
type J struct {
a string //小写无tag
b string `json:"B"` //小写+tag
C string //大写无tag
D string `json:"DD" otherTag:"good"` //大写+tag
}
func printTag(stru interface{}) {
t := reflect.TypeOf(stru).Elem()
for i := 0; i < t.NumField(); i++ {
fmt.Printf("结构体内第%v个字段 %v 对应的json tag是 %v , 还有otherTag? = %v \n", i+1, t.Field(i).Name, t.Field(i).Tag.Get("json"), t.Field(i).Tag.Get("otherTag"))
}
}
func main() {
j := J{
a: "1",
b: "2",
C: "3",
D: "4",
}
printTag(&j)
}
输出
结构体内第1个字段 a 对应的json tag是 , 还有otherTag? =
结构体内第2个字段 b 对应的json tag是 B , 还有otherTag? =
结构体内第3个字段 C 对应的json tag是 , 还有otherTag? =
结构体内第4个字段 D 对应的json tag是 DD , 还有otherTag? = good
解释
printTag方法传入的是j的指针。reflect.TypeOf(stru).Elem()获取指针指向的值对应的结构体内容。NumField()可以获得该结构体的含有几个字段。- 遍历结构体内的字段,通过
t.Field(i).Tag.Get("json")可以获取到tag为json的字段。 - 如果结构体的字段有
多个tag,比如叫otherTag,同样可以通过t.Field(i).Tag.Get("otherTag")获得。
再补一句
提到json包不能导出私有变量的tag是因为取不到反射信息的说法,但是直接取t.Field(i).Tag.Get("json")却可以获取到私有变量的json字段,是为什么呢?
其实准确的说法是,json包里不能导出私有变量的tag是因为json包里认为私有变量为不可导出的Unexported,所以跳过获取名为json的tag的内容。具体可以看/src/encoding/json/encode.go:1070的代码。
func typeFields(t reflect.Type) []field {
// 注释掉其他逻辑...
// 遍历结构体内的每个字段
for i := 0; i < f.typ.NumField(); i++ {
sf := f.typ.Field(i)
isUnexported := sf.PkgPath != ""
// 注释掉其他逻辑...
if isUnexported {
// 如果是不可导出的变量则跳过
continue
}
// 如果是可导出的变量(public),则获取其json字段
tag := sf.Tag.Get("json")
// 注释掉其他逻辑...
}
// 注释掉其他逻辑...
}
在for循环⾥append元素 #
package main
import "fmt"
func main() {
s := []int{1,2,3,4,5}
for _, v:=range s {
s =append(s, v)
fmt.Printf("len(s)=%v\n",len(s))
}
}
这个代码会造成死循环吗?
-
不会死循环,
for range其实是golang的语法糖,在循环开始前会获取切片的长度len(切片),然后再执行len(切片)次数的循环。 -
for range的源码是
// The loop we generate:
// for_temp := range
// len_temp := len(for_temp)
// for index_temp = 0; index_temp < len_temp; index_temp++ {
// value_temp = for_temp[index_temp]
// index = index_temp
// value = value_temp
// original body
// }
go struct能不能⽐较 #
相同struct类型的可以⽐较
不同struct类型的不可以⽐较,编译都不过,类型不匹配
如果 struct 的所有字段都是可比较的类型(即支持 == 和 != 操作),那么该 struct 本身也是可比较的。例如:
type Person struct {
Name string
Age int
}
p1 := Person{"Alice", 25}
p2 := Person{"Alice", 25}
p3 := Person{"Bob", 30}
fmt.Println(p1 == p2) // true,因为所有字段都相同
fmt.Println(p1 == p3) // false,因为字段不同
不可比较的 struct**
如果 struct 包含不可比较的字段(如 slice、map、func 等),那么该 struct 不能直接比较,否则会编译错误:
type Data struct {
Tags []string // slice 不可比较
}
d1 := Data{Tags: []string{"a", "b"}}
d2 := Data{Tags: []string{"a", "b"}}
// fmt.Println(d1 == d2) // 编译错误:invalid operation: d1 == d2 (struct containing []string cannot be compared)
3. 特殊情况
-
map的 key 必须是可比较的,所以如果 struct 包含不可比较的字段,就不能作为map的 key:type User struct { ID int Data map[string]string // map 不可比较 } // users := make(map[User]string) // 编译错误:invalid map key type User -
reflect.DeepEqual可以比较任意 struct(即使包含不可比较的字段):import "reflect" d1 := Data{Tags: []string{"a", "b"}} d2 := Data{Tags: []string{"a", "b"}} fmt.Println(reflect.DeepEqual(d1, d2)) // true
函数是引用类型
Go 的函数本质上是一个指向函数代码的指针(类似于 C 的函数指针)。如果允许比较函数,实际上比较的是它们的内存地址,而不是函数本身的逻辑。
1. 不可比较的类型(Non-comparable Types)
| 类型 | 原因 |
|---|---|
slice(切片) |
底层数据可能共享,比较无意义 |
map(映射) |
底层哈希表结构可能变化 |
func(函数) |
函数是引用类型,比较无意义 |
chan(通道) |
虽然 chan 可以比较(比较的是底层指针),但通常不建议直接比较 |
any(即 interface{}) |
如果动态类型是不可比较的(如 []int),则运行时 panic |
包含上述类型的 struct |
只要有一个字段不可比较,整个 struct 就不可比较 |
2. 可比较的类型(Comparable Types)
| 类型 | 备注 |
|---|---|
| 基本类型 | int、float、bool、string 等 |
array(数组) |
只要元素可比较,数组就可比较 |
pointer(指针) |
比较的是地址,而不是指向的值 |
struct |
所有字段可比较时,struct 才可比较 |
chan(通道) |
可比较,但比较的是底层指针 |
Go ⽀持什么形式的类型转换?将整数转换为浮点数。 #
Go ⽀持显式类型转换以满⾜其严格的类型要求。
i := 55 //int
j := 67.8 //float64
sum := i + int(j)//j is converted to int
Log包线程安全吗? #
在 Go 的标准库 log 包中,线程安全(goroutine 安全) 是通过 互斥锁(sync.Mutex) 来保证的。具体来说,log 包在以下方面做了线程安全保护:
log 包的线程安全实现
全局锁保护日志输出
log 包内部使用一个 sync.Mutex 来确保多个 goroutine 并发调用 Print、Printf、Println等日志方法时不会发生竞争条件:
// src/log/log.go
var (
std = New(os.Stderr, "", LstdFlags) // 默认的 Logger
mu sync.Mutex // 全局互斥锁
)
- 每次调用日志方法(如
log.Println())时,都会先加锁,确保同一时间只有一个 goroutine 能写入日志。 - 日志输出完成后,解锁。
Goroutine和线程的区别? #
什么是 Goroutine**?你如何停⽌它?** #
⼀个 Goroutine 是⼀个函数或⽅法执⾏同时旁边其他任何够程采⽤了特殊的 Goroutine 线程。Goroutine 线程⽐标准线程更轻量级,⼤多数 Golang 程序同时使⽤数千个 g、Goroutine。
可以通过向 Goroutine 发送⼀个信号通道来停⽌它
Go中除了加Mutex锁以外还有哪些⽅式安全读写共享变量? #
Golang中Goroutine 可以通过 Channel 进⾏安全读写共享变量。
go语⾔的并发机制以及它所使⽤的CSP并发模型 #
Golang 中常⽤的并发模型? #
Golang 中常⽤的并发模型有三种:
-
通过channel通知实现并发控制
-
通过sync包中的WaitGroup实现并发控制
-
通过Context上下⽂,实现并发控制
JSON 标准库对 nil slice 和 空 slice 的处理是⼀致的吗? #
⾸先JSON 标准库对 nil slice 和 空 slice 的处理是不⼀致.
通常错误的⽤法,会报数组越界的错误,因为只是声明了slice,却没有给实例化的对象。
var slice []int
slice[1] = 0
此时slice的值是nil,这种情况可以⽤于需要返回slice的函数,当函数出现异常的时候,保证函数依然会有nil的返回值。
empty slice 是指slice不为nil,但是slice没有值,slice的底层的空间是空的,此时的定义如下:
slice := make([]int,0)
slice := []int{}
当我们查询或者处理⼀个空的列表的时候,这⾮常有⽤,它会告诉我们返回的是⼀个列表,但是列表内没有任何值。
总之,nil slice 和 empty slice是不同的东⻄,需要我们加以区分的.
协程,线程,进程的区别 #
互斥锁,读写锁,死锁问题是怎么解决 #
Golang的内存模型,为什么⼩对象多了会造成gc压⼒。 #
通常⼩对象过多会导致GC三⾊法消耗过多的GPU。优化思路是,减少对象分配
说下Go中的锁有哪些?三种锁,读写锁,互斥锁,还有map的安全的锁? #
channel为什么它可以做到线程安全? #
Channel(通道)的线程安全(goroutine 安全) 是由其底层实现机制保证的。使用了一个 互斥锁(sync.Mutex) 来保护对 Channel 的读写操作。
怎么限制Goroutine的数量 #
使⽤通道,每次执⾏的go之前向通道写⼊值,直到通道满的时候就阻塞了
Channel是同步的还是异步的. #
Channel是异步进⾏的。
channel存在3种状态:
-
nil,未初始化的状态,只进⾏了声明,或者⼿动赋值为nil
-
active,正常的channel,可读或者可写
-
closed,已关闭,千万不要误认为关闭channel后,channel的值是nil
Data Race问题怎么解决?能不能不加锁解决这个问题? #
要想解决数据竞争的问题可以使⽤互斥锁sync.Mutex,解决数据竞争(Data race),也可以使⽤管道解决,使⽤管道的效率要⽐互斥锁⾼。
Go 当中同步锁有什么特点?作⽤是什么 #
当⼀个 Goroutine(协程)获得了 Mutex 后,其他 Gorouline(协程)就只能乖乖的等待,除⾮该 gorouline 释放了该 MutexRWMutex在读锁占⽤的情况下,会阻⽌写,但不阻⽌读 RWMutex 在写锁占⽤情况下,会阻⽌任何其他goroutine(⽆论读和写)进来,整个锁相当于由该 goroutine 独占同步锁的作⽤是保证资源在使⽤时的独有性,不会因为并发⽽导致数据错乱,保证系统的稳定性。
go 两个接⼝之间可以存在什么关系? #
如果两个接⼝有相同的⽅法列表,那么他们就是等价的,可以相互赋值。如果接⼝ A的⽅法列表是接⼝ B的⽅法列表的⾃⼰,那么接⼝ B可以赋值给接⼝ A。接⼝查询是否成功,要在运⾏期才能够确定。
go convey 是什么?⼀般⽤来做什么? #
-
go convey 是⼀个⽀持 golang 的单元测试框架
-
go convey 能够⾃动监控⽂件修改并启动测试,并可以将测试结果实时输出到 Web界⾯
-
go convey 提供了丰富的断⾔简化测试⽤例的编写
new 和 make 有什么区别吗? #
关键区别
| 特性 | new |
make |
|---|---|---|
| 适用类型 | 任意类型(int、struct 等) |
仅 slice、map、chan |
| 返回值类型 | 指针(*T) |
已初始化的对象(T) |
| 内存初始化 | 零值 | 根据类型初始化(如 map 的哈希表) |
| 是否常用 | 较少使用(通常直接声明或复合字面量) | 高频使用(初始化引用类型必须用它) |
make不能初始化数组,因为它是值类型,静态分配
new 的作用:为值类型(如 int、struct)或引用类型(如 slice、map 的指针)分配内存,并返回零值的指针(*T),不能new函数,但可以new函数指针:
var pf *func() // 声明函数指针
pf = new(func()) // 分配内存,pf 指向 nil 函数
*pf = func() { // 解引用并赋值
fmt.Println("Assigned")
}
(*pf)() // 输出 "Assigned"
Go **语⾔当中值传递和地址传递(引⽤传递)如何运⽤?有什么区别? #
- 值传递只会把参数的值复制⼀份放进对应的函数,两个变量的地址不同,不可相互修改。
- 地址传递(引⽤传递)会将变量本身传⼊对应的函数,在函数中可以对该变量进⾏值内容的修改。
Go 语⾔当中数组和切⽚在传递的时候的区别是什么? #
- 数组是值传递
- 切⽚是引⽤传递