什么是分布式系统?和集群的区别? #
分布式就是把一个集中式系统拆分成多个系统,每一个系统单独对外提供部分功能,整个分布式系统整体对外提供一整套服务。对于访问分布式系统的用户来说,感知上就像访问一台计算机一样。
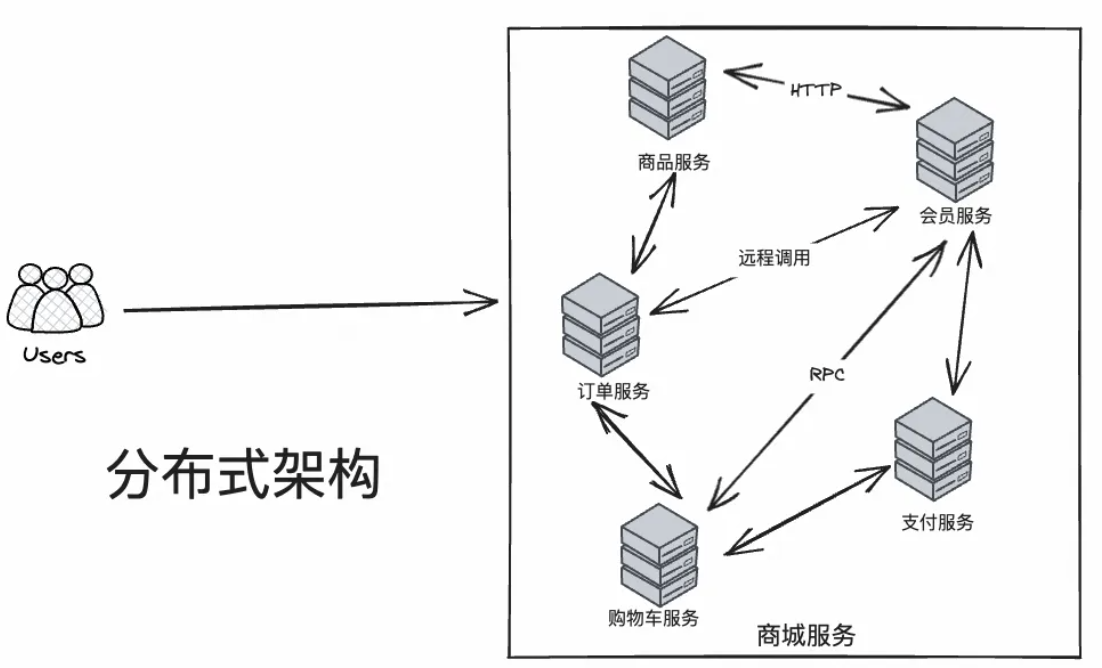
分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
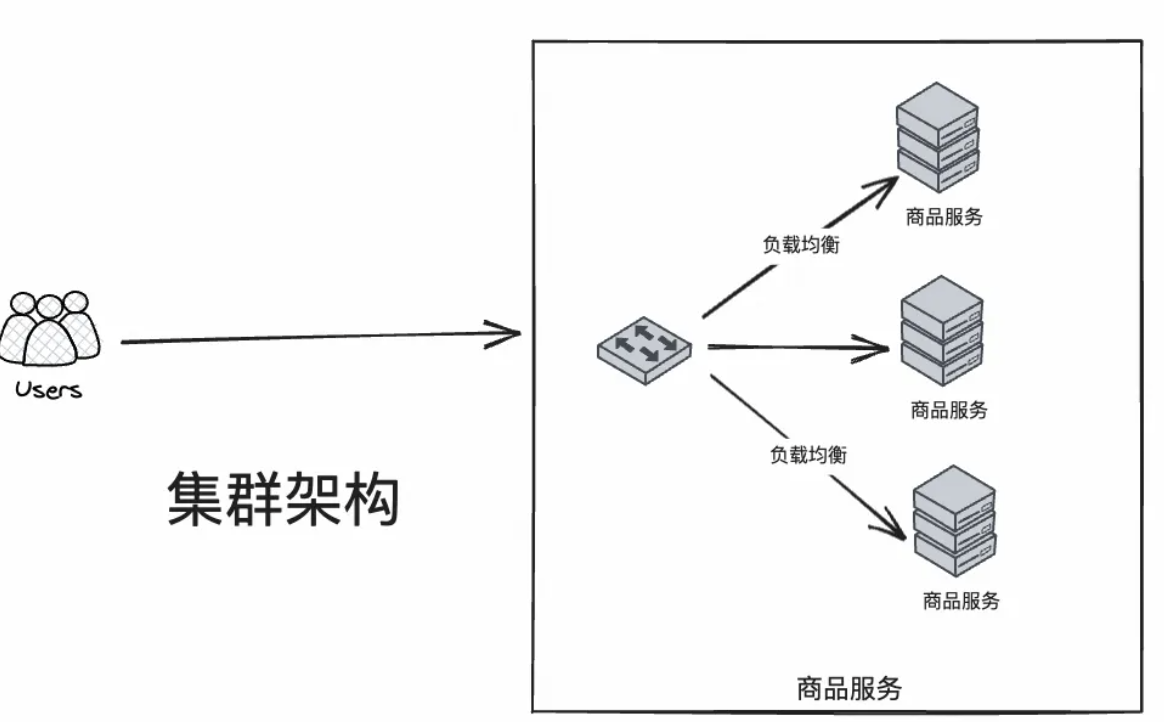
集群(cluster)是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
什么是分布式系统的一致性? #
所谓一致性,是指数据在多个副本之间是否能够保持一致的特性。
大的分类上面,主要有三种,分别是强一致性、弱一致性和最终一致性:
- 强一致性模型(Strong Consistency): 在强一致性模型下,系统保证每个读操作都将返回最近的写操作的结果,即任何时间点,客户端都将看到相同的数据视图。这包括线性一致性(Linearizability)、顺序一致性(Sequential Consistency)和严格可串行性(Strict Serializability)等子模型。强一致性模型通常牺牲了可用性来实现数据一致性。
- 弱一致性模型(Weak Consistency): 弱一致性模型放宽了一致性保证,它允许在不同节点之间的数据访问之间存在一定程度的不一致性,以换取更高的性能和可用性。这包括因果一致性(Causal Consistency)、会话一致性(Session Consistency)和单调一致性(Monotonic Consistency)等子模型。弱一致性模型通常更注重可用性,允许一定程度的数据不一致性。
- 最终一致性模型(Eventual Consistency): 最终一致性模型是一种最大程度放宽了一致性要求的模型。它允许在系统发生分区或网络故障后,经过一段时间,系统将最终达到一致状态。这个模型在某些情况下提供了很高的可用性,但在一段时间内可能会出现数据不一致的情况。
线性一致性和顺序一致性 #
线性一致性是一种最强的一致性模型,它强调在分布式系统中的任何时间点,读操作都应该返回最近的写操作的结果。
顺序一致性也是一种强一致性模型,但相对于线性一致性而言,它放宽了一些限制。在顺序一致性模型中,系统维护一个全局的操作顺序,以确保每个客户端看到的操作顺序都是一致的。
与线性一致性不同,顺序一致性不强调实时性,只要操作的顺序是一致的,就可以接受一些延迟。
什么是一致性哈希? #
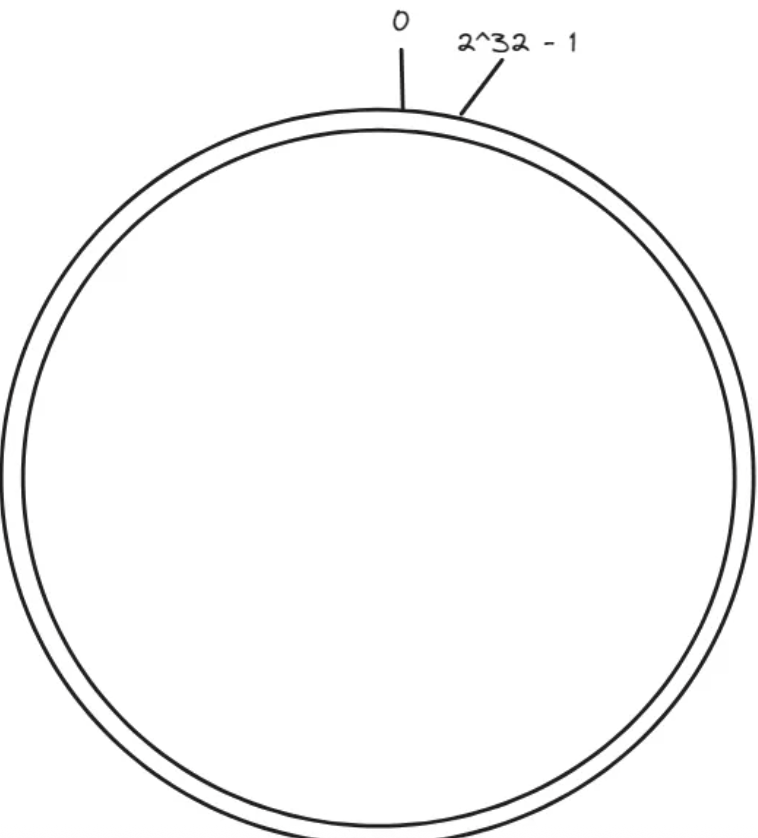
一致性哈希是一种用于分布式系统中数据分片和负载均衡的算法。它的目标是在节点的动态增加或删除时,尽可能的减少数据迁移和重新分布的成本。
实现一致性哈希算法首先需要构造一个哈希环,然后把他划分为固定数量的虚拟节点,如2^32。那么他的节点编号就是 0-2^32-1:
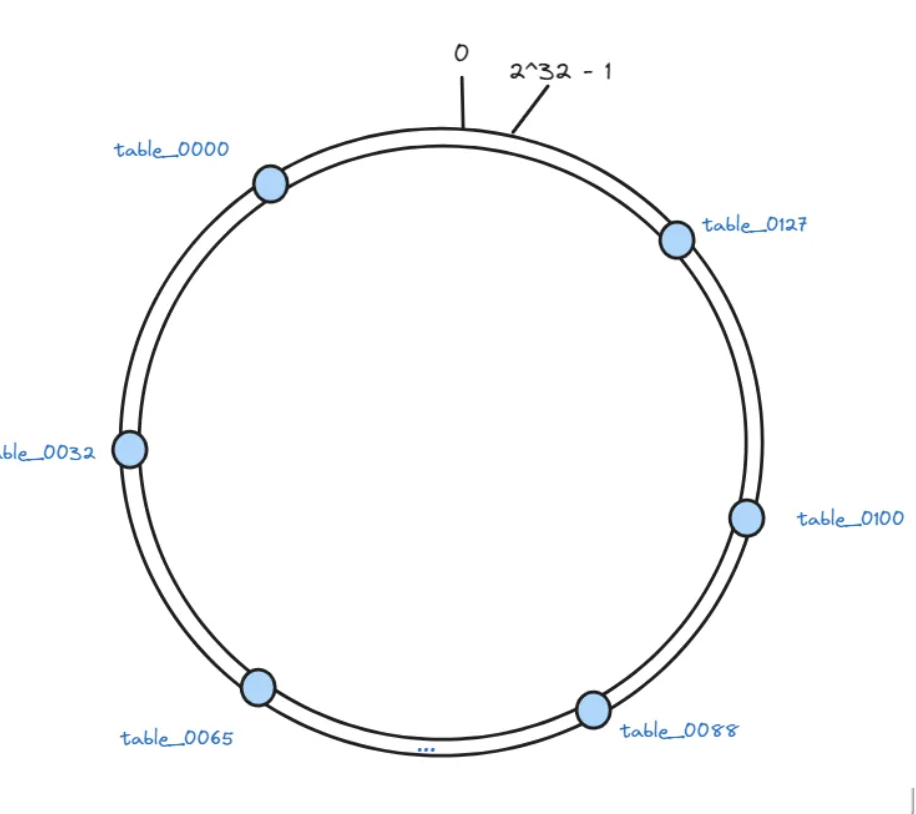
接下来, 我们把128张表作为节点映射到这些虚拟节点上,每个节点在哈希空间上都有一个对应的虚拟节点:
hash(table_0000)%2^32、hash(table_0001)%2^32、hash(table_0002)%2^32 …. hash(table_0127)%2^32
在把这些表做好hash映射之后,我们就需要存储数据了,现在我们要把一些需要分表的数据也根据同样的算法进行hash,并且也将其映射哈希环上。
hash(buyer_id)%2^32:hash(12321)%2^32、hash(34432)%2^32、hash(54543)%2^32 …. hash(767676)%2^32
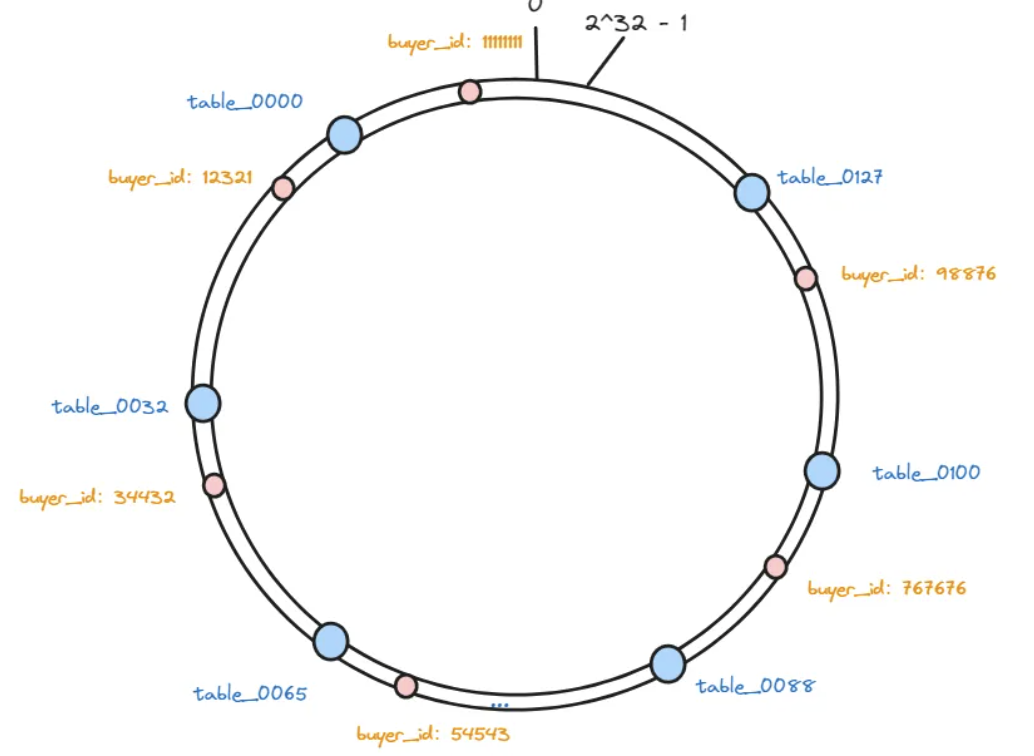
这样,这个hash环上的虚拟节点就包含两部分数据的映射了,一部分是存储数据的分表的映射,一部分是真实要存储的数据的映射。
那么, 我们最终还是要把这些数据存储到数据库分表中,那么做好哈希之后,这些数据又要保存在哪个数据库表节点中呢?
其实很简单,只需要按照数据的位置,沿着顺时针方向查找,找到的第一个分表节点就是数据应该存放的节点:
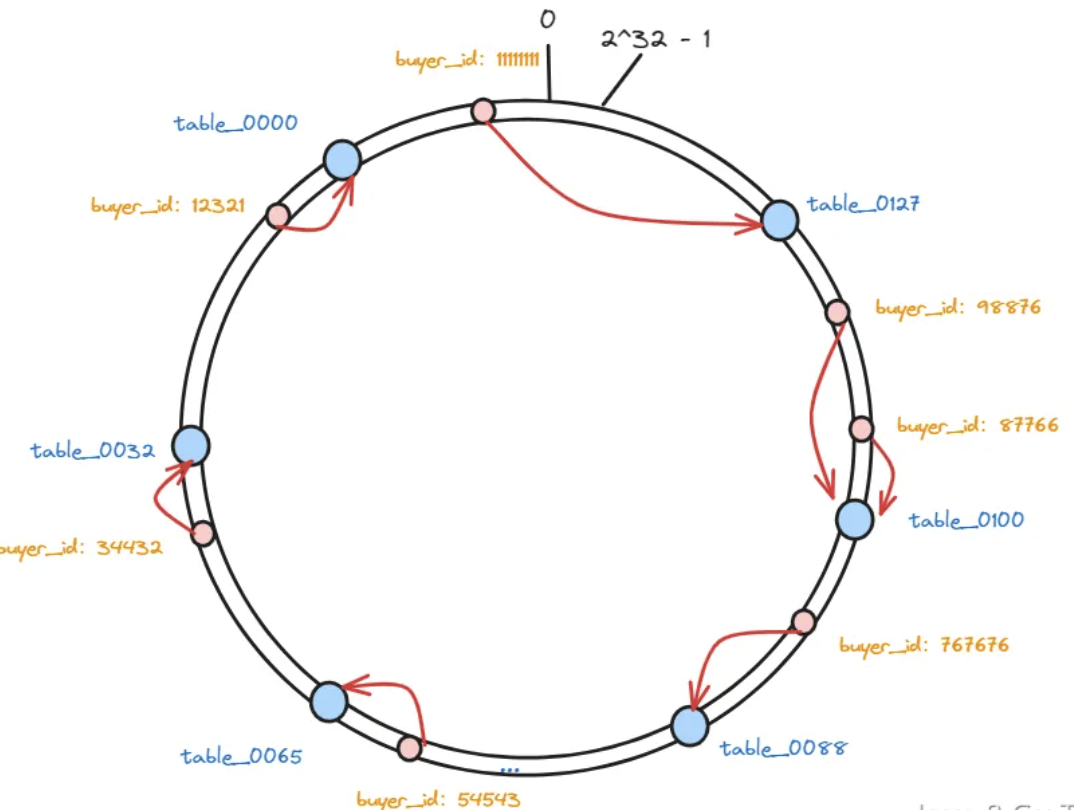
因为要存储的数据,以及存储这些数据的数据库分表,hash后的值都是固定的,所以在数据库数量不变的情况下,下次想要查询数据的时候,只需要按照同样的算法计算一次就能找到对应的分表了。
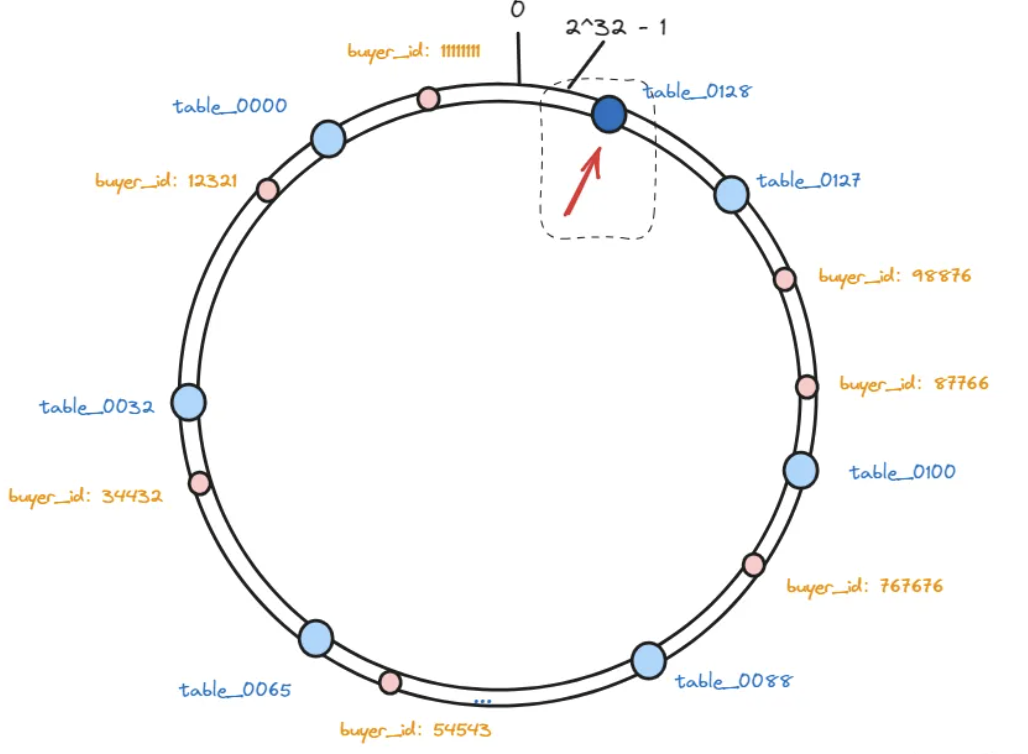
以上,就是一致性hash算法的原理,那么,再回到我们开头的问题,如果我要增加一个分表怎么办呢?
我们首先要将新增加的表通过一致性hash算法映射到哈希环的虚拟节点中:
这样,会有一部分数据,因为节点数量发生变化,那么他顺时针遇到的第一个分表可能就变了。
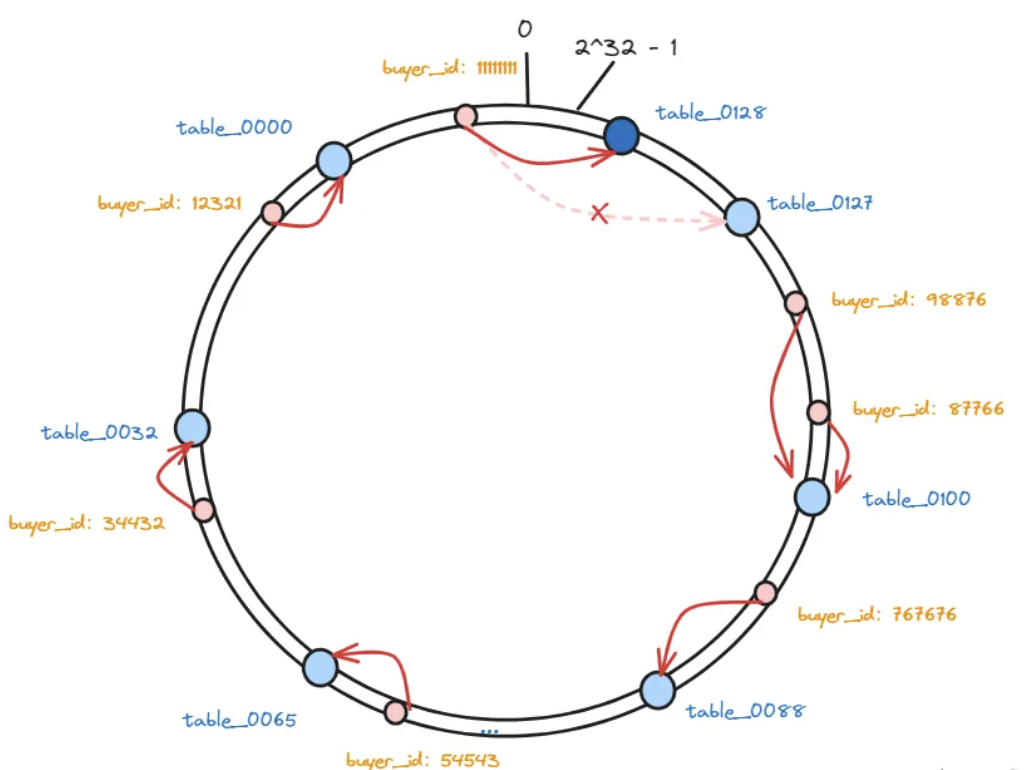
相比于普通hash算法,在增加服务器之后,影响的范围非常小,只影响到一部分数据,其他的数据是不需要调整的。
优点:
数据均衡:在增加或删除节点时,一致性哈希算法只会影响到少量的数据迁移,保持了数据的均衡性。
高扩展性:当节点数发生变化时,对于已经存在的数据,只有部分数据需要重新分布,不会影响到整体的数据结构。
缺点:
hash倾斜:在节点数较少的情况下,由于哈希空间是有限的,节点的分布可能不够均匀,导致数据倾斜。
节点的频繁变更:如果频繁添加或删除节点,可能导致大量的数据迁移,造成系统压力。
哈希倾斜 #
其实,hash倾斜带来的主要问题就是如果数据过于集中的话,就会使得节点数量发生变化时,数据的迁移成本过高。
那么想要解决这个问题,比较好的办法就是增加服务器节点,这样节点就会尽可能的分散了。
但是如果没有那么多服务器,我们也可以引入一些虚拟节点,把一个服务器节点,拆分成多个虚拟节点,然后数据在映射的时候先映射到虚拟节点,然后虚拟节点在找到对应的物理节点进行存储和读取就行了。
常见的分布式事务有哪些? #
分布式事务的目的是保证分布式系统中的多个参与方的数据能够保证一致性。
一致性分为强一致性,和最终一致性。
-
如果想要强一致性,就一定要引入协调者,通过协调者来协调所有参与者进行提交或者回滚。
这类方案包含基于XA规范的二阶段即三阶段提交、以及支持2节点提交。